Les sémaphores¶
Le problème de la coordination entre threads est un problème majeur. Outre les mutex que nous avons présenté, d’autres solutions à ce problème ont été développées. Historiquement, une des premières propositions de coordination sont les sémaphores [Dijkstra1965b]. Un sémaphore est une structure de données qui est maintenue par le système d’exploitation et contient :
- un entier qui stocke la valeur, positive ou nulle, du sémaphore.
- une queue qui contient les pointeurs vers les threads qui sont bloqués en attente sur ce sémaphore.
Tout comme pour les mutex, la queue associée à un sémaphore permet de bloquer les threads qui sont en attente d’une modification de la valeur du sémaphore.
Une implémentation des sémaphores se compose en général de quatre fonctions :
- une fonction d’initialisation qui permet de créer le sémaphore et de lui attribuer une valeur initiale nulle ou positive.
- une fonction permettant de détruire un sémaphore et de libérer les ressources qui lui sont associées.
- une fonction post qui est utilisée par les threads pour modifier la valeur du sémaphore. S’il n’y a pas de thread en attente dans la queue associée au sémaphore, sa valeur est incrémentée d’une unité. Sinon, un des threads en attente est libéré et passe à l’état Ready.
- une fonction wait qui est utilisée par les threads pour tester la valeur d’un sémaphore. Si la valeur du sémaphore est positive, elle est décrémentée d’une unité et la fonction réussit. Si le sémaphore a une valeur nulle, le thread est bloqué jusqu’à ce qu’un autre thread le débloque en appelant la fonction post.
Les sémaphores sont utilisés pour résoudre de nombreux problèmes de coordination [Downey2008]. Comme ils permettent de stocker une valeur entière, ils sont plus flexibles que les mutex qui sont utiles surtout pour les problèmes d’exclusion mutuelle.
Sémaphores POSIX¶
La librairie POSIX comprend une implémentation des sémaphores [1] qui expose plusieurs fonctions aux utilisateurs. La page de manuel sem_overview(7) présente de façon sommaire les fonctions de la librairie relatives aux sémaphores. Les quatre principales sont les suivantes :
#include <semaphore.h>
int sem_init(sem_t *sem, int pshared, unsigned int value);
int sem_destroy(sem_t *sem);
int sem_wait(sem_t *sem);
int sem_post(sem_t *sem);
Le fichier semaphore.h contient les différentes définitions de structures qui sont nécessaires au bon fonctionnement des sémaphores ainsi que les signatures des fonctions de cette API. Un sémaphore est représenté par une structure de données de type sem_t. Toutes les fonctions de manipulation des sémaphores prennent comme argument un pointeur vers le sémaphore concerné.
Pour pouvoir utiliser un sémaphore, il faut d’abord l’initialiser. Cela se fait en utilisant la fonction sem_init(3) qui prend comme argument un pointeur vers le sémaphore à initialiser. Nous n’utiliserons pas le second argument dans ce chapitre. Le troisième argument est la valeur initiale, positive ou nulle, du sémaphore.
La fonction sem_destroy(3) permet de libérer un sémaphore qui a été initialisé avec sem_init(3). Les sémaphores consomment des ressources qui peuvent être limitées dans certains environnements. Il est important de détruire proprement les sémaphores dès qu’ils ne sont plus nécessaires.
Les deux principales fonctions de manipulation des sémaphores sont sem_wait(3) et sem_post(3). Certains auteurs utilisent down ou P à la place de sem_wait(3) et up ou V à la place de sem_post(3) [Downey2008]. Schématiquement, l’opération sem_wait peut s’implémenter en utilisant le pseudo-code suivant :
int sem_wait(semaphore *s)
{
s->val=s->val-1;
if(s->val<0)
{
// Place this thread in s.queue;
// This thread is blocked;
}
}
La fonction sem_post(3) quant à elle peut schématiquement s’implémenter comme suit :
int sem_post(semaphore *s)
{
s->val=s->val+1;
if(s.val<=0)
{
// Remove one thread(T) from s.queue;
// Mark Thread(T) as ready to run;
}
}
Ces deux opérations sont bien entendu des opérations qui ne peuvent s’exécuter simultanément. Leur implémentation réelle comprend des sections critiques qui doivent être construites avec soin. Le pseudo-code ci-dessus ignore ces sections critiques. Des détails complémentaires sur l’implémentation des sémaphores peuvent être obtenus dans livre sur les systèmes d’exploitation [Stallings2011] [Tanenbaum+2009].
La meilleure façon de comprendre leur utilisation est d’analyser des problèmes classiques de coordination qui peuvent être résolus en utilisant des sémaphores.
Exclusion mutuelle¶
Les sémaphores permettent de résoudre de nombreux problèmes classiques. Le premier est celui de l’exclusion mutuelle. Lorsqu’il est initialisé à 1, un sémaphore peut être utilisé de la même façon qu’un mutex. En utilisant des sémaphores, une exclusion mutuelle peut être protégée comme suit :
#include <semaphore.h>
//...
sem_t semaphore;
sem_init(&semaphore, 0, 1);
sem_wait(&semaphore);
// section critique
sem_post(&semaphore);
sem_destroy(&semaphore);
Les sémaphores peuvent être utilisés pour d’autres types de synchronisation. Par exemple, considérons une application découpée en threads dans laquelle la fonction after ne peut jamais être exécutée avant la fin de l’exécution de la fonction before. Ce problème de coordination peut facilement être résolu en utilisant un sémaphore qui est initialisé à la valeur 0. La fonction after doit démarrer par un appel à sem_wait(3) sur ce sémaphore tandis que la fonction before doit se terminer par un appel à la fonction sem_post(3) sur ce sémaphore. De cette façon, si le thread qui exécute la fonction after est trop rapide, il sera bloqué sur l’appel à sem_wait(3). S’il arrive à cette fonction après la fin de la fonction before dans l’autre thread, il pourra passer sans être bloqué. Le programme ci-dessous illustre cette utilisation des sémaphores POSIX.
#define NTHREADS 2
sem_t semaphore;
void *before(void * param) {
// do something
for(int j=0;j<1000000;j++) {
}
sem_post(&semaphore);
return(NULL);
}
void *after(void * param) {
sem_wait(&semaphore);
// do something
for(int j=0;j<1000000;j++) {
}
return(NULL);
}
int main (int argc, char *argv[]) {
pthread_t thread[NTHREADS];
void * (* func[])(void *)={before, after};
int err;
err=sem_init(&semaphore, 0,0);
if(err!=0) {
error(err,"sem_init");
}
for(int i=0;i<NTHREADS;i++) {
err=pthread_create(&(thread[i]),NULL,func[i],NULL);
if(err!=0) {
error(err,"pthread_create");
}
}
for(int i=0;i<NTHREADS;i++) {
err=pthread_join(thread[i],NULL);
if(err!=0) {
error(err,"pthread_join");
}
}
sem_destroy(&semaphore);
if(err!=0) {
error(err,"sem_destroy");
}
return(EXIT_SUCCESS);
}
Si un sémaphore initialisé à la valeur 1 est généralement utilisé comme un mutex, il y a une différence importante entre les implémentations des sémaphores et des mutex. Un sémaphore est conçu pour être manipulé par différents threads et il est fort possible qu’un thread exécute sem_wait(3) et qu’un autre exécute sem_post(3). Pour les mutex, certaines implémentations supposent que le même thread exécute pthread_mutex_lock(3posix) et pthread_mutex_unlock(3posix). Lorsque ces opérations doivent être effectuées dans des threads différents, il est préférable d’utiliser des sémaphores à la place de mutex.
Problème du rendez-vous¶
Le problème du rendez-vous [Downey2008] est un problème assez courant dans les applications multithreadées. Considérons une application découpée en N threads. Chacun de ces threads travaille en deux phases. Durant la première phase, tous les threads sont indépendants et peuvent s’exécuter simultanément. Cependant, un thread ne peut démarrer sa seconde phase que si tous les N threads ont terminé leur première phase. L’organisation de chaque thread est donc :
premiere_phase();
// rendez-vous
seconde_phase();
Chaque thread doit pouvoir être bloqué à la fin de la première phase en attendant que tous les autres threads aient fini d’exécuter leur première phase. Cela peut s’implémenter en utilisant un mutex et un sémaphore.
sem_t rendezvous;
pthread_mutex_t mutex;
int count=0;
sem_init(&rendezvous,0,0);
La variable count permet de compter le nombre de threads qui ont atteint le point de rendez-vous. Le mutex protège les accès à la variable count qui est partagée entre les différents threads. Le sémaphore rendezvous est initialisé à la valeur 0. Le rendez-vous se fera en bloquant les threads sur le sémaphore rendezvous tant que les N threads ne sont pas arrivés à cet endroit.
premiere_phase();
// section critique
pthread_mutex_lock(&mutex);
count++;
if(count==N) {
// tous les threads sont arrivés
sem_post(&rendezvous);
}
pthread_mutex_unlock(&mutex);
// attente à la barrière
sem_wait(&rendezvous);
// libération d'un autre thread en attente
sem_post(&rendezvous);
seconde_phase();
Le pseudo-code ci-dessus présente une solution permettant de résoudre ce problème du rendez-vous. Le sémaphore étant initialisé à 0, le premier thread qui aura terminé la première phase sera bloqué sur sem_wait(&rendezvous);. Les N-1 premiers threads qui auront terminé leur première phase seront tous bloqués à cet endroit. Lorsque le dernier thread finira sa première phase, il incrémentera count puis exécutera sem_post(&rendezvous); ce qui libèrera un premier thread. Le dernier thread sera ensuite bloqué sur sem_wait(&rendezvous); mais il ne restera pas bloqué longtemps car chaque fois qu’un thread parvient à passer sem_wait(&rendezvous);, il exécute immédiatement sem_post(&rendezvous); ce qui permet de libérer un autre thread en cascade.
Cette solution permet de résoudre le problème du rendez-vous avec un nombre fixe de threads. Certaines implémentations de la librairie des threads POSIX comprennent une barrière qui peut s’utiliser de la même façon que la solution ci-dessus. Une barrière est une structure de données de type pthread_barrier_t. Elle s’initialise en utilisant la fonction pthread_barrier_init(3posix) qui prend trois arguments : un pointeur vers une barrière, des attributs optionnels et le nombre de threads qui doivent avoir atteint la barrière pour que celle-ci s’ouvre. La fonction pthread_barrier_destroy(3posix) permet de détruire une barrière. Enfin, la fonction pthread_barrier_wait(3posix) qui prend comme argument un pointeur vers une barrière bloque le thread correspondant à celle-ci tant que le nombre de threads requis pour passer la barrière n’a pas été atteint.
Problème des producteurs-consommateurs¶
Le problème des producteurs-consommateurs est un problème extrêmement fréquent et important dans les applications découpées en plusieurs threads. Il est courant de structurer une telle application, notamment si elle réalise de longs calculs, en deux types de threads :
- les producteurs : Ce sont des threads qui produisent des données et placent le résultat de leurs calculs dans une zone mémoire accessible aux consommateurs.
- les consommateurs : Ce sont des threads qui utilisent les valeurs calculées par les producteurs.
Ces deux types de threads communiquent en utilisant un buffer qui a une capacité limitée à N places comme illustré dans la figure ci-dessous.
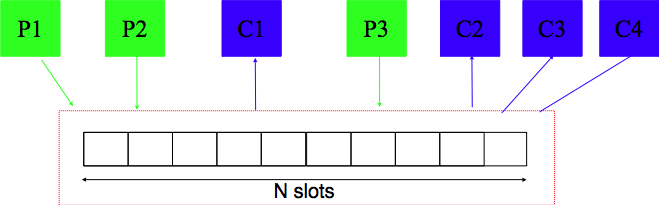
Problème des producteurs-consommateurs
La difficulté du problème est de trouver une solution qui permet aux producteurs et aux consommateurs d’avancer à leur rythme sans que les producteurs ne bloquent inutilement les consommateurs et inversement. Le nombre de producteurs et de consommateurs ne doit pas nécessairement être connu à l’avance et ne doit pas être fixe. Un producteur peut arrêter de produire à n’importe quel moment.
Le buffer étant partagé entre les producteurs et les consommateurs, il doit nécessairement être protégé par un mutex. Les producteurs doivent pouvoir ajouter de l’information dans le buffer partagé tant qu’il y a au moins une place de libre dans le buffer. Un producteur ne doit être bloqué que si tout le buffer est rempli. Inversement, les consommateurs doivent être bloqués uniquement si le buffer est entièrement vide. Dès qu’une donnée est ajoutée dans le buffer, un consommateur doit être réveillé pour traiter cette donnée.
Ce problème peut être résolu en utilisant deux sémaphores et un mutex. L’accès au buffer, que ce soit par les consommateurs ou les producteurs est une section critique. Cet accès doit donc être protégé par l’utilisation d’un mutex. Quant aux sémaphores, le premier, baptisé empty dans l’exemple ci-dessous, sert à compter le nombre de places qui sont vides dans le buffer partagé. Ce sémaphore doit être initialisé à la taille du buffer puisque celui-ci est initialement vide. Le second sémaphore est baptisé full dans le pseudo-code ci-dessous. Sa valeur représente le nombre de places du buffer qui sont occupées. Il doit être initialisé à la valeur 0.
// Initialisation
#define N 10 // places dans le buffer
pthread_mutex_t mutex;
sem_t empty;
sem_t full;
pthread_mutex_init(&mutex, NULL);
sem_init(&empty, 0 , N); // buffer vide
sem_init(&full, 0 , 0); // buffer vide
Le fonctionnement général d’un producteur est le suivant. Tout d’abord, le producteur est mis en attente sur le sémaphore empty. Il ne pourra passer que si il y a au moins une place du buffer qui est vide. Lorsque la ligne sem_wait(&empty); réussit, le producteur s’approprie le mutex et modifie le buffer de façon à insérer l’élément produit (dans ce cas un entier). Il libère ensuite le mutex pour sortir de sa section critique.
// Producteur
void producer(void)
{
int item;
while(true)
{
item=produce(item);
sem_wait(&empty); // attente d'une place libre
pthread_mutex_lock(&mutex);
// section critique
insert_item();
pthread_mutex_unlock(&mutex);
sem_post(&full); // il y a une place remplie en plus
}
}
Le consommateur quant à lui essaie d’abord de prendre le sémaphore full. Si celui-ci est positif, cela indique la présence d’au moins un élément dans le buffer partagé. Ensuite, il entre dans la section critique protégée par le mutex et récupère la donnée se trouvant dans le buffer. Puis, il incrémente la valeur du sémaphore empty de façon à indiquer à un producteur qu’une nouvelle place est disponible dans le buffer.
// Consommateur
void consumer(void)
{
int item;
while(true)
{
sem_wait(&full); // attente d'une place remplie
pthread_mutex_lock(&mutex);
// section critique
item=remove(item);
pthread_mutex_unlock(&mutex);
sem_post(&empty); // il y a une place libre en plus
}
}
De nombreux programmes découpés en threads fonctionnent avec un ensemble de producteurs et un ensemble de consommateurs.
Problème des readers-writers¶
Le problème des readers-writers est un peu différent du précédent. Il permet de modéliser un problème qui survient lorsque des threads doivent accéder à une base de données [Courtois+1971]. Les threads sont généralement de deux types.
- les lecteurs (readers) sont des threads qui lisent une structure de données (ou une base de données) mais ne la modifient pas. Comme ces threads se contentent de lire de l’information en mémoire, rien ne s’oppose à ce que plusieurs readers s’exécutent simultanément.
- les écrivains (writers). Ce sont des threads qui modifient une structure de données (ou une base de données). Pendant qu’un writer manipule la structure de données, il ne peut y avoir aucun autre writer ni de reader qui accède à cette structure de données. Sinon, la concurrence des opérations de lecture et d’écriture donnerait un résultat incorrect.
Une première solution à ce problème est d’utiliser un mutex et un sémaphore [Courtois+1971].
pthread_mutex_t mutex;
sem_t db; // accès à la db
int readcount=0; // nombre de readers
sem_init(&db, NULL, 1).
La solution utilise une variable partagée : readcount. L’accès à cette variable est protégé par mutex. Le sémaphore db sert à réguler l’accès des writers à la base de données. Le mutex est initialisé comme d’habitude par la fonction pthread_mutex_init(3posix). Le sémaphore db est initialisé à la valeur 1. Le writer est assez simple :
void writer(void)
{
while(true)
{
prepare_data();
sem_wait(&db);
// section critique, un seul writer à la fois
write_database();
sem_post(&db);
}
}
}
Le sémaphore db sert à assurer l’exclusion mutuelle entre les writers pour l’accès à la base de données. Le fonctionnement des readers est plus intéressant. Pour éviter un conflit entre les writers et les readers, il est nécessaire d’empêcher aux readers d’accéder à la base de données pendant qu’un writer la modifie. Cela peut se faire en utilisant l’entier readcount qui permet de compter le nombre de readers qui manipulent la base de données. Cette variable est testée et modifiée par tous les readers, elle doit donc être protégée par un mutex. Intuitivement, lorsque le premier reader veut accéder à la base de données (readcount==0), il essaye de décrémenter le sémaphore db. Si ce sémaphore est libre, le reader accède à la base de données. Sinon, il bloque sur sem_wait(&db); et comme il possède mutex, tous les autres readers sont bloqués sur pthread_mutex_lock(&mutex);. Dès que le premier reader est débloqué, il autorise en cascade l’accès à tous les autres readers qui sont en attente en libérant pthread_mutex_unlock(&mutex);. Lorsqu’un reader arrête d’utiliser la base de données, il vérifie s’il était le dernier reader. Si c’est le cas, il libère le sémaphore db de façon à permettre à un writer d’y accéder. Sinon, il décrémente simplement la variable readcount pour tenir à jour le nombre de readers qui sont actuellement en train d’accéder à la base de données.
void reader(void)
{
while(true)
{
pthread_mutex_lock(&mutex);
// section critique
readcount++;
if (readcount==1)
{ // arrivée du premier reader
sem_wait(&db);
}
pthread_mutex_unlock(&mutex);
read_database();
pthread_mutex_lock(&mutex);
// section critique
readcount--;
if(readcount==0)
{ // départ du dernier reader
sem_post(&db);
}
pthread_mutex_unlock(&mutex);
process_data();
}
}
Cette solution fonctionne et garantit qu’il n’y aura jamais qu’un seul writer qui accède à la base de données. Malheureusement, elle souffre d’un inconvénient majeur lorsqu’il y a de nombreux readers. Dans ce cas, il est tout à fait possible qu’il y ait en permanence des readers qui accèdent à la base de données et que les writers soient toujours empêchés d’y accéder. En effet, dès que le premier reader a effectué sem_wait(&db);, aucun autre reader ne devra exécuter cette opération tant qu’il restera au moins un reader accédant à la base de données. Les writers par contre resteront bloqués sur l’exécution de sem_wait(&db);.
En utilisant des sémaphores à la place des mutex, il est possible de contourner ce problème. Cependant, cela nécessite d’utiliser plusieurs sémaphores. Intuitivement, l’idée de la solution est de donner priorité aux writers par rapport aux readers. Dès qu’un writer est prêt à accéder à la base de données, il faut empêcher de nouveaux readers d’y accéder tout en permettant aux readers présents de terminer leur lecture. Vous construirez ce mécanisme en séance de travaux dirigés.
Note
Read-Write locks
Certaines implémentations de la librairie des threads POSIX contiennent des Read-Write locks. Ceux-ci constituent une API de plus haut niveau qui s’appuie sur des sémaphores pour résoudre le problème des readers-writers. Les fonctions de création et de suppression de ces locks sont : pthread_rwlock_init(3posix), pthread_rwlock_destroy(3posix). Les fonctions pthread_rwlock_rdlock(3posix) et pthread_rwlock_unlock(3posix) sont réservées aux readers tandis que les fonctions pthread_rwlock_wrlock(3posix) et pthread_rwlock_unlock(3posix) sont utilisables par les writers. Des exemples d’utilisation de ces Read-Write locks peuvent être obtenus dans [Gove2011].
Compléments sur les threads POSIX¶
Il existe différentes implémentations des threads POSIX. Les mécanismes de coordination utilisables varient parfois d’une implémentation à l’autre. Dans les sections précédentes, nous nous sommes focalisés sur les fonctions principales qui sont en général bien implémentées. Une discussion plus détaillée des fonctions implémentées sous Linux peut se trouver dans [Kerrisk2010]. [Gove2011] présente de façon détaillée les mécanismes de coordination utilisables sous Linux, Windows et Oracle Solaris. [StevensRago2008] comprend également une description des threads POSIX mais présente des exemples sur des versions plus anciennes de Linux, FreeBSD, Solaris et MacOS.
Il reste cependant quelques concepts qu’il est utile de connaître lorsque l’on développe des programmes découpés en threads en langage C.
Variables volatile¶
Normalement, dans un programme C, lorsqu’une variable est définie, ses accès sont contrôlés entièrement par le compilateur. Si la variable est utilisée dans plusieurs calculs successifs, il peut être utile d’un point de vue des performances de stocker la valeur de cette variable dans un registre pendant au moins le temps correspondant à l’exécution de quelques instructions [2]. Cette optimisation peut éventuellement poser des difficultés dans certains programmes utilisant des threads puisqu’une variable peut être potentiellement modifiée ou lue par plusieurs threads simultanément.
Les premiers compilateurs C avaient pris en compte un problème similaire. Lorsqu’un programme ou un système d’exploitation interagit avec des dispositifs d’entrée-sortie, cela se fait parfois en permettant au dispositif d’écrire directement en mémoire à une adresse connue par le système d’exploitation. La valeur présente à cette adresse peut donc être modifiée par le dispositif d’entrée-sortie sans que le programme ne soit responsable de cette modification. Face à ce problème, les inventeurs du langage C ont introduit le qualificatif volatile. Lorsqu’une variable est volatile, cela indique au compilateur qu’il doit recharger la variable de la mémoire chaque fois qu’elle est utilisée.
Pour bien comprendre l’impact de ce qualificatif, il est intéressant d’analyser le code assembleur généré par un compilateur C dans l’exemple suivant.
int x=1;
int v[2];
void f(void ) {
v[0]=x;
v[1]=x;
}
Dans ce cas, la fonction f est traduite en la séquence d’instructions suivante :
f:
movl x, %eax
movl %eax, v
movl %eax, v+4
ret
Si par contre la variable x est déclarée comme étant volatile, le compilateur ajoute une instruction movl x, %eax qui permet de recharger la valeur de x dans un registre avant la seconde utilisation.
f:
movl x, %eax
movl %eax, v
movl x, %eax
movl %eax, v+4
ret
Le qualificatif volatile force le compilateur à recharger la variable depuis la mémoire avant chaque utilisation. Ce qualificatif est utile lorsque le contenu stocké à une adresse mémoire peut être modifié par une autre source que le programme lui-même. C’est le cas dans les threads, mais marquer les variables partagées par des threads comme volatile ne suffit pas. Si ces variables sont modifiées par certains threads, il est nécessaire d’utiliser des mutex ou d’autres techniques de coordination pour réguler l’accès en ces variables partagées. En pratique, la documentation du programme devra spécifier quelles variables sont partagées entre les threads et la technique de coordination éventuelle qui est utilisée pour en réguler les accès. L’utilisation du qualificatif volatile permet de forcer le compilateur à recharger le contenu de la variable depuis la mémoire avant toute utilisation. C’est une règle de bonne pratique qu’il est utile de suivre. Il faut cependant noter que dans l’exemple ci-dessus, l’utilisation du qualificatif volatile augmente le nombre d’accès à la mémoire et peut donc dans certains cas réduire les performances.
Variables spécifiques à un thread¶
Dans un programme C séquentiel, on doit souvent combiner les variables globales, les variables locales et les arguments de fonctions. Lorsque le programme est découpé en threads, les variables globales restent utilisables, mais il faut faire attention aux problèmes d’accès concurrent. En pratique, il est parfois utile de pouvoir disposer dans chaque thread de variables qui tout en étant accessibles depuis toutes les fonctions du thread ne sont pas accessibles aux autres threads. Il y a différentes solutions pour résoudre ce problème.
Une première solution serait d’utiliser une zone mémoire qui est spécifique au thread et d’y placer par exemple une structure contenant toutes les variables auxquelles on souhaite pouvoir accéder depuis toutes les fonctions du thread. Cette zone mémoire pourrait être créée avant l’appel à pthread_create(3) et un pointeur vers cette zone pourrait être passé comme argument à la fonction qui démarre le thread. Malheureusement l’argument qui est passé à cette fonction n’est pas équivalent à une variable globale et n’est pas accessible à toutes les fonctions du thread.
Une deuxième solution serait d’avoir un tableau global qui contiendrait des pointeurs vers des zones de mémoires qui ont été allouées pour chaque thread. Chaque thread pourrait alors accéder à ce tableau sur base de son identifiant. Cette solution pourrait fonctionner si le nombre de threads est fixe et que les identifiants de threads sont des entiers croissants. Malheureusement la librairie threads POSIX ne fournit pas de tels identifiants croissants. Officiellement, la fonction pthread_self(3) retourne un identifiant unique d’un thread qui a été créé. Malheureusement cet identifiant est de type pthread_t et ne peut pas être utilisé comme index dans un tableau. Sous Linux, l’appel système non-standard gettid(2) retourne l’identifiant du thread, mais il ne peut pas non plus être utilisé comme index dans un tableau.
Pour résoudre ce problème, deux solutions sont possibles. La première combine une extension au langage C qui est supportée par gcc(1) avec la librairie threads POSIX. Il s’agit du qualificatif __thread qui peut être utilisé avant une déclaration de variable. Lorsqu’il est utilisé dans la déclaration d’une variable globale, il indique au compilateur et à la libraire POSIX qu’une copie de cette variable doit être créée pour chaque thread. Cette variable est initialisée au démarrage du thread et est utilisable uniquement à l’intérieur de ce thread. Le programme ci-dessous illustre cette utilisation du qualificatif __thread.
#define LOOP 1000000
#define NTHREADS 4
__thread int count=0;
int global_count=0;
void *f( void* param) {
for(int i=0;i<LOOP;i++) {
count++;
global_count=global_count-1;
}
printf("Valeurs : count=%d, global_count=%d\n",count, global_count);
return(NULL);
}
int main (int argc, char *argv[]) {
pthread_t threads[NTHREADS];
int err;
for(int i=0;i<NTHREADS;i++) {
count=i; // local au thread du programme principal
err=pthread_create(&(threads[i]),NULL,&f,NULL);
if(err!=0)
error(err,"pthread_create");
}
for(int i=0;i<NTHREADS;i++) {
err=pthread_join(threads[i],NULL);
if(err!=0)
error(err,"pthread_create");
}
return(EXIT_SUCCESS);
}
Lors de son exécution, ce programme affiche la sortie suivante sur stdout. Cette sortie illustre bien que les variables dont la déclaration est précédée du qualificatif __thread sont utilisables uniquement à l’intérieur d’un thread.
Valeurs : count=1000000, global_count=-870754
Valeurs : count=1000000, global_count=-880737
Valeurs : count=1000000, global_count=-916383
Valeurs : count=1000000, global_count=-923423
La seconde solution proposée par la librairie POSIX est plus complexe. Elle nécessite l’utilisation des fonctions pthread_key_create(3posix), pthread_setspecific(3posix), pthread_getspecific(3posix) et pthread_key_delete(3posix). Cette API est malheureusement plus difficile à utiliser que le qualificatif __thread, mais elle illustre ce qu’il se passe en pratique lorsque ce qualificatif est utilisé.
Pour avoir une variable accessible depuis toutes les fonctions d’un thread, il faut tout d’abord créer une clé qui identifie cette variable. Cette clé est de type pthread_key_t et c’est l’adresse de cette structure en mémoire qui est utilisée comme identifiant pour la variable spécifique à chaque thread. Cette clé ne doit être créée qu’une seule fois. Cela peut se faire dans le programme qui lance les threads ou alors dans le premier thread lancé en utilisant la fonction pthread_once(3posix). Une clé est créée grâce à la fonction pthread_key_create(3posix). Cette fonction prend deux arguments. Le premier est un pointeur vers une structure de type pthread_key_t. Le second est la fonction optionnelle à appeler lorsque le thread utilisant la clé se termine.
Il faut noter que la fonction pthread_key_create(3posix) associe en pratique le pointeur NULL à la clé qui a été créée dans chaque thread. Le thread qui veut utiliser la variable correspondant à cette clé doit réserver la zone mémoire correspondante. Cela se fait en général en utilisant malloc(3) puis en appelant la fonction pthread_setspecific(3posix). Celle-ci prend deux arguments. Le premier est une clé de type pthread_key_t qui a été préalablement créée. Le second est un pointeur (de type void *) vers la zone mémoire correspondant à la variable spécifique. Une fois que le lien entre la clé et le pointeur a été fait, la fonction pthread_getspecific(3posix) peut être utilisée pour récupérer le pointeur depuis n’importe quelle fonction du thread. L’implémentation des fonctions pthread_setspecific(3posix) et pthread_getspecific(3posix) garantit que chaque thread aura sa variable qui lui est propre.
L’exemple ci-dessous illustre l’utilisation de cette API. Elle est nettement plus lourde à utiliser que le qualificatif __thread. Dans ce code, chaque thread démarre par la fonction f. Celle-ci crée une variable spécifique de type int qui joue le même rôle que la variable __thread int count; dans l’exemple précédent. La fonction g qui est appelée sans argument peut accéder à la zone mémoire créée en appelant pthread_getspecific(count). Elle peut ensuite exécuter ses calculs en utilisant le pointeur count_ptr. Avant de se terminer, la fonction f libère la zone mémoire qui avait été allouée par malloc(3). Une alternative à l’appel explicite à free(3) aurait été de passer free comme second argument à pthread_key_create(3posix) lors de la création de la clé count. En effet, ce second argument est la fonction à appeler à la fin du thread pour libérer la mémoire correspondant à cette clé.
#define LOOP 1000000
#define NTHREADS 4
pthread_key_t count;
int global_count=0;
void g(void ) {
void * data=pthread_getspecific(count);
if(data==NULL)
error(-1,"pthread_getspecific");
int *count_ptr=(int *)data;
for(int i=0;i<LOOP;i++) {
*count_ptr=*(count_ptr)+1;
global_count=global_count-1;
}
}
void *f( void* param) {
int err;
int *int_ptr=malloc(sizeof(int));
*int_ptr=0;
err=pthread_setspecific(count, (void *)int_ptr);
if(err!=0)
error(err,"pthread_setspecific");
g();
printf("Valeurs : count=%d, global_count=%d\n",*int_ptr, global_count);
free(int_ptr);
return(NULL);
}
int main (int argc, char *argv[]) {
pthread_t threads[NTHREADS];
int err;
err=pthread_key_create(&(count),NULL);
if(err!=0)
error(err,"pthread_key_create");
for(int i=0;i<NTHREADS;i++) {
err=pthread_create(&(threads[i]),NULL,&f,NULL);
if(err!=0)
error(err,"pthread_create");
}
for(int i=0;i<NTHREADS;i++) {
err=pthread_join(threads[i],NULL);
if(err!=0)
error(err,"pthread_create");
}
err=pthread_key_delete(count);
if(err!=0)
error(err,"pthread_key_delete");
return(EXIT_SUCCESS);
}
En pratique, on préférera évidemment d’utiliser le qualificatif __thread plutôt que d’utiliser une API explicite lorsque c’est possible. Cependant, il ne faut pas oublier que lorsque ce qualificatif est utilisé, le compilateur doit introduire dans le programme du code permettant de faire le même genre d’opérations que les fonctions explicites de la librairie.
Fonctions thread-safe¶
Dans un programme séquentiel, il n’y a qu’un thread d’exécution et de nombreux programmeurs, y compris ceux qui ont développé la librairie standard, utilisent cette hypothèse lors de l’écriture de fonctions. Lorsqu’un programme est découpé en threads, chaque fonction peut être appelée par plusieurs threads simultanément. Cette exécution simultanée d’une fonction peut poser des difficultés notamment lorsque la fonction utilise des variables globales ou des variables statiques.
Pour comprendre le problème, il est intéressant de comparer plusieurs implémentations d’une fonction simple. Considérons le problème de déterminer l’élément maximum d’une structure de données contenant des entiers. Si la structure de données est un tableau, une solution simple est de le parcourir entièrement pour déterminer l’élément maximum. C’est ce que fait la fonction max_vector dans le programme ci-dessous. Dans un programme purement séquentiel dans lequel le tableau peut être modifié de temps en temps, parcourir tout le tableau pour déterminer son maximum n’est pas nécessairement la solution la plus efficace. Une alternative est de mettre à jour la valeur du maximum chaque fois qu’un élément du tableau est modifié. Les fonctions max_global et max_static sont deux solutions possibles. Chacune de ces fonctions doit être appelée chaque fois qu’un élément du tableau est modifié. max_global stocke dans une variable globale la valeur actuelle du maximum du tableau et met à jour cette valeur à chaque appel. La fonction max_static fait de même en utilisant une variable statique. Ces deux solutions sont équivalentes et elles pourraient très bien être intégrées à une librairie utilisée par de nombreux programmes.
#include <stdint.h>
#define SIZE 10000
int g_max=INT32_MIN;
int v[SIZE];
int max_vector(int n, int *v) {
int max=INT32_MIN;
for(int i=0;i<n;i++) {
if(v[i]>max)
max=v[i];
}
return max;
}
int max_global(int *v) {
if (*v>g_max) {
g_max=*v;
}
return(g_max);
}
int max_static(int *v){
static int s_max=INT32_MIN;
if (*v>s_max) {
s_max=*v;
}
return(s_max);
}
Considérons maintenant un programme découpé en plusieurs threads qui chacun maintient un tableau d’entiers dont il faut connaître le maximum. Ces tableaux d’entiers sont distincts et ne sont pas partagés entre les threads. La fonction max_vector peut être utilisée par chaque thread pour déterminer le maximum du tableau. Par contre, les fonctions max_global et max_static ne peuvent pas être utilisées. En effet, chacune de ces fonctions maintient un état (dans ce cas le maximum calculé) alors qu’elle peut être appelée par différents threads qui auraient chacun besoin d’un état qui leur est propre. Pour que ces fonctions soient utilisables, il faudrait que les variables s_max et g_max soient spécifiques à chaque thread.
En pratique, ce problème de l’accès concurrent à des fonctions se pose pour de nombreuses fonctions et notamment celles de la librairie standard. Lorsque l’on développe une fonction qui peut être réutilisée, il est important de s’assurer que cette fonction peut être exécutée par plusieurs threads simultanément sans que cela ne pose de problèmes à l’exécution.
Ce problème affecte certaines fonctions de la librairie standard et plusieurs d’entre elles ont dû être modifiées pour pouvoir supporter les threads. A titre d’exemple, considérons la fonction strerror(3). Cette fonction prend comme argument le numéro de l’erreur et retourne une chaîne de caractères décrivant cette erreur. Cette fonction ne peut pas être utilisée telle quelle par des threads qui pourraient l’appeler simultanément. Pour s’en convaincre, regardons une version simplifiée d’une implémentation de cette fonction [3]. Cette fonction utilise le tableau sys_errlist(3) qui contient les messages d’erreur associés aux principaux codes numériques d’erreur. Lorsque l’erreur est une erreur standard, tout se passe bien et la fonction retourne simplement un pointeur vers l’entrée du tableau sys_errlist correspondante. Par contre, si le code d’erreur n’est pas connu, un message est généré dans le tableau buf[32] qui est déclaré de façon statique. Si plusieurs threads exécutent strerror, ce sera le même tableau qui sera utilisé dans les différents threads. On pourrait remplacer le tableau statique par une allocation de zone mémoire faite via malloc(3), mais alors la zone mémoire créée risque de ne jamais être libérée par free(3) car l’utilisateur de strerror(3) ne doit pas libérer le pointeur qu’il a reçu, ce qui pose d’autres problèmes en pratique.
char * strerror (int errnoval)
{
char * msg;
static char buf[32];
if ((errnoval < 0) || (errnoval >= sys_nerr))
{ // Out of range, just return NULL
msg = NULL;
}
else if ((sys_errlist == NULL) || (sys_errlist[errnoval] == NULL))
{ // In range, but no sys_errlist or no entry at this index.
sprintf (buf, "Error %d", errnoval);
msg = buf;
}
else
{ // In range, and a valid message. Just return the message.
msg = (char *) sys_errlist[errnoval];
}
return (msg);
}
La fonction strerror_r(3) évite ce problème de tableau statique en utilisant trois arguments : le code d’erreur, un pointeur char * vers la zone devant stocker le message d’erreur et la taille de cette zone. Cela permet à strerror_r(3) d’utiliser une zone mémoire qui lui est passée par le thread qu’il appelle et garantit que chaque thread disposera de son message d’erreur. Voici une implémentation possible de strerror_r(3) [4].
strerror_r(int num, char *buf, size_t buflen)
{
#define UPREFIX "Unknown error: %u"
unsigned int errnum = num;
int retval = 0;
size_t slen;
if (errnum < (unsigned int) sys_nerr) {
slen = strlcpy(buf, sys_errlist[errnum], buflen);
} else {
slen = snprintf(buf, buflen, UPREFIX, errnum);
retval = EINVAL;
}
if (slen >= buflen)
retval = ERANGE;
return retval;
}
Lorsque l’on intègre des fonctions provenant de la librairie standard ou d’une autre librairie dans un programme découpé en threads, il est important de vérifier que les fonctions utilisées sont bien thread-safe. La page de manuel pthreads(7) liste les fonctions qui ne sont pas thread-safe dans la librairie standard.
Loi de Amdahl¶
En découpant un programme en threads, il est théoriquement possible d’améliorer les performances du programme en lui permettant d’exécuter plusieurs threads d’exécution simultanément. Dans certains cas, la découpe d’un programme en différents threads est naturelle et relativement facile à réaliser. Dans d’autres cas, elle est nettement plus compliquée. Pour s’en convaincre, il suffit de considérer un grand tableau contenant plusieurs centaines de millions de nombres. Considérons un programme simple qui doit trouver dans ce tableau quel est l’élément du tableau pour lequel l’application d’une fonction complexe f donne le résultat minimal. Une implémentation purement séquentielle se contenterait de parcourir l’entièreté du tableau et d’appliquer la fonction f à chacun des éléments. A la fin de son exécution, le programme retournera l’élément qui donne la valeur minimale. Un tel problème est très facile à découper en threads. Il suffit de découper le tableau en N sous-tableaux, de lancer un thread de calcul sur chaque sous-tableau et ensuite de fusionner les résultats de chaque thread.
Un autre problème est de trier le contenu d’un tel tableau dans l’ordre croissant. De nombreux algorithmes séquentiels de tri existent pour ordonner un tableau. La découpe de ce problème en thread est nettement moins évidente que dans le problème précédent et les algorithmes de tri adaptés à une utilisation dans plusieurs threads ne sont pas une simple extension des algorithmes séquentiels.
Dans les années 1960s, à l’époque des premières réflexions sur l’utilisation de plusieurs processeurs pour résoudre un problème, Gene Amdahl [Amdahl1967] a analysé quelles étaient les gains que l’on pouvait attendre de l’utilisation de plusieurs processeurs. Dans sa réflexion, il considère un programme P qui peut être découpé en deux parties :
- une partie purement séquentielle. Il s’agit par exemple de l’initialisation de l’algorithme utilisé, de la collecte des résultats, ...
- une partie qui est parallélisable. Il s’agit en général du coeur de l’algorithme.
Plus les opérations réalisées à l’intérieur d’un programme sont indépendantes entre elles, plus le programme est parallélisable et inversement. Pour Amdahl, si le temps d’exécution d’un programme séquentiel est T et qu’une fraction f de ce programme est parallélisable, alors le gain qui peut être obtenu de la parallélisation est \(\frac{T}{T \times( (1-f)+\frac{f}{N})}=\frac{1}{ (1-f)+\frac{f}{N}}\) lorsque le programme est découpé en N threads. Cette formule, connue sous le nom de la loi de Amdahl fixe une limite théorique sur le gain que l’on peut obtenir en parallélisant un programme. La figure ci-dessous [#famdahl]_ illustre le gain théorique que l’on peut obtenir en parallélisant un programme en fonction du nombre de processeur et pour différentes fractions parallélisables.
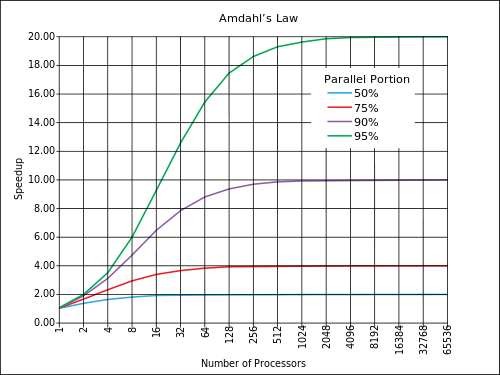
Loi de Amdahl (source wikipedia)
La loi de Amdahl doit être considérée comme un maximum théorique qui est difficile d’atteindre. Elle suppose que la parallélisation est parfaite, c’est-à-dire que la création et la terminaison de threads n’ont pas de coût en terme de performance. En pratique, c’est loin d’être le cas et il peut être difficile d’estimer a priori le gain qu’une parallélisation permettra d’obtenir. En pratique, avant de découper un programme séquentiel en threads, il est important de bien identifier la partie séquentielle et la partie parallélisable du programme. Si la partie séquentielle est trop importante, le gain dû à la parallélisation risque d’être faible. Si par contre la partie purement séquentielle est faible, il est possible d’obtenir théoriquement des gains élevés. Le tout sera de trouver des solutions efficaces qui permettront aux threads de fonctionner le plus indépendamment possible.
En pratique, avant de s’attaquer à la découpe d’un programme séquentiel en threads, il est important de bien comprendre quelles sont les parties du programme qui sont les plus consommatrices de temps CPU. Ce seront souvent les boucles ou les grandes structures de données. Si le programme séquentiel existe, il est utile d’analyser son exécution avec des outils de profiling tels que gprof(1) [Graham+1982] ou oprofile. Un profiler est un logiciel qui permet d’analyser l’exécution d’un autre logiciel de façon à pouvoir déterminer notamment quelles sont les fonctions ou parties du programmes les plus exécutées. Ces parties de programme sont celles sur lesquelles l’effort de paraléllisation devra porter en pratique.
Dans un programme découpé en threads, toute utilisation de fonctions de coordination comme des sémaphores ou des mutex, bien qu’elle soit nécessaire pour la correction du programme, risque d’avoir un impact négatif sur les performances. Pour s’en convaincre, il est intéressant de réfléchir au problème des producteurs-consommateurs. Il correspond à de nombreux programmes réels. Les performances d’une implémentation du problème des producteurs consommateurs dépendront fortement de la taille du buffer entre les producteurs et les consommateurs et de leur nombre et/ou vitesses relatives. Idéalement, il faudrait que le buffer soit en moyenne rempli à moitié. De cette façon, chaque producteur pourra déposer de l’information dans le buffer et chaque consommateur pourra en retirer. Si le buffer est souvent vide, cela indique que les consommateurs sont plus rapides que les producteurs. Ces consommateurs risquent d’être inutilement bloqués, ce qui affectera les performances. Il en va de même si le buffer était plein. Dans ce cas, les producteurs seraient souvent bloqués.
Footnotes
| [1] | Les systèmes Unix supportent également des sémaphores dits System V du nom de la version de Unix dans laquelle ils ont été introduits. Dans ces notes, nous nous focalisons sur les sémaphores POSIX qui ont une API un peu plus simple que les es sémaphores System V. Les principales fonctions pour les sémaphores System V sont semget(3posix), semctl(3posix) et semop(3posix). |
| [2] | Les premiers compilateurs C permettaient au programmeur de donner des indications au compilateur en faisant précéder les déclarations de certaines variables avec le qualificatif register [KernighanRitchie1998]. Ce qualificatif indiquait que la variable était utilisée fréquemment et que le compilateur devrait en placer le contenu dans un registre. Les compilateurs actuels sont nettement plus performants et ils sont capables de détecter quelles sont les variables qu’il faut placer dans un registre. Il est inutile de chercher à influencer le compilateur en utilisant le qualificatif register. Les compilateurs actuels, dont gcc(1) supportent de nombreuses options permettant d’optimiser les performances des programmes compilés. Certaines ont comme objectif d’accélérer l’exécution du programme, d’autres visent à réduire sa taille. Pour les programmes qui consomment beaucoup de temps CPU, il est utile d’activer l’optimisation du compilateur. |
| [3] | Cette implémentation est adaptée de http://opensource.apple.com/source/gcc/gcc-926/libiberty/strerror.c et est dans le domaine public. |
| [4] | Cette implémentation est adaptée de https://www-asim.lip6.fr/trac/netbsdtsar/browser/vendor/netbsd/5/src/lib/libc/string/strerror_r.c?rev=2 et est Copyright (c) 1988 Regents of the University of California. |