Ordonnancement (Scheduling)
Nous avons vu dans le chapitre précédent qu’un système d’exploitation comme Linux pouvait supporter de nombreux threads (appartenant à divers processus) avec un nombre limité (ou même unique) de processeur(s). Un processeur n’exécute pourtant qu’un seul thread à la fois. Le partage des processeurs est rendu possible par un mécanisme de partage de temps : le système d’exploitation peut basculer de l’utilisation d’un processeur par un thread à une utilisation par un autre thread. L’enchaînement rapide de l’exécution des différents threads sur les processeurs donne l’illusion à l’utilisateur que ceux-ci s’exécutent simultanément. Le mécanisme permettant le partage de temps est le changement de contexte. Nous l’avons décrit dans les chapitres précédents.
La mise en œuvre du partage de temps illustre bien le principe de séparation entre mécanisme et politique, un objectif important poursuivi lors de la conception d’UNIX et de Linux. Le mécanisme de changement de contexte permet en effet d’assurer la transition entre les threads sur un ou plusieurs processeur(s), mais il ne dit pas quel thread doit être privilégié pour obtenir un processeur, ou quand un thread utilisant un processeur doit le libérer pour laisser la place à un autre thread. Ces décisions sont du ressort de la politique d’ordonnancement ou scheduler. L’avantage de séparer les décisions sur l’accès aux processeurs pour les différents threads, du mécanisme permettant d’acter ces décisions, est sa grande flexibilité. Un même mécanisme peut être utilisé avec des politiques différentes sur des systèmes aussi dissemblables qu’un super-calculateur ou une montre connectée, pour prendre des exemples de systèmes utilisant le noyau Linux.
Modèle d’exécution des threads et bursts CPU
Un thread exécute ses instructions par phases, alternant deux types d’opérations :
- Lorsqu’il obtient le processeur, un burst CPU (rafale d’utilisation du processeur en français) pendant lequel le processeur exécute des instructions du thread de façon continue;
- Ce burst CPU se termine par l’utilisation d’une opération bloquante, comme une demande d’entrée/sortie ou une opération de synchronisation.
À la suite de l’appel bloquant, le thread ne peut pas faire de progrès tant que le résultat de l’opération n’est pas disponible.
La longueur des burst CPUs, et la fréquence des opérations bloquantes comme les entrée/sorties, peut varier fortement d’une application à l’autre. Ceci est illustré par la figure suivante.
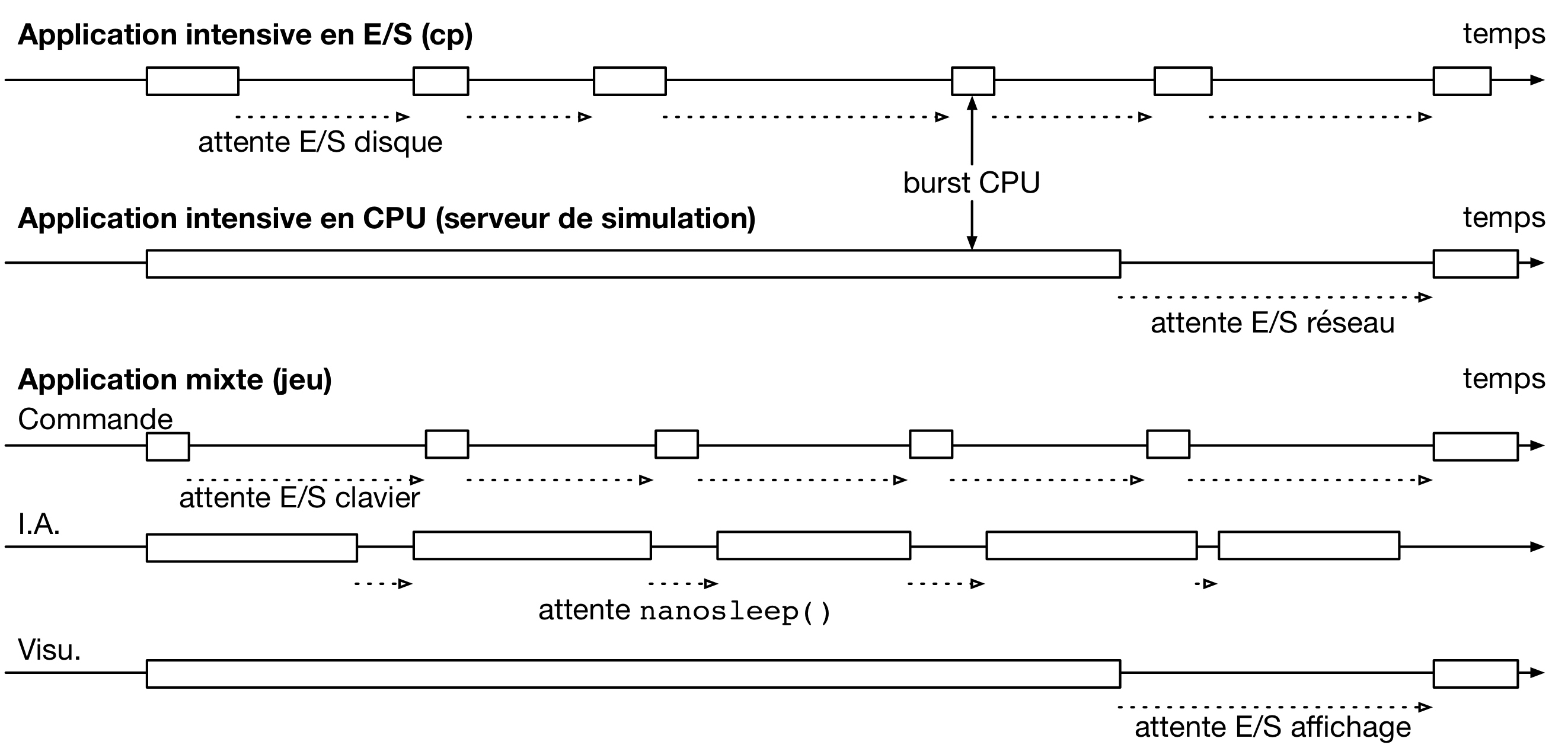
Dans cet exemple, une application de copie de fichier comme cp(1) [http://sites.uclouvain.be/SystInfo/manpages/man1/cp.1.html] effectue de nombreuses opérations d’entrée/sortie pour lire et écrire un fichier à copier en utilisant le système de fichiers, entremêlées de bursts CPU courts. Une application de calcul numérique présentera, au contraire, des bursts CPU très longs avec des entrée/sorties seulement au début et à la fin des calculs.
Un application peut tout à fait être composée de plusieurs threads présentant des caractéristiques différentes. Par exemple, dans un jeu, le thread chargé de prendre en compte les commandes du joueur (à l’aide du clavier ou d’une manette) présentera souvent des bursts CPU courts et de longues périodes d’attente, tandis que le thread en charge de l’intelligence artificielle du jeu pourra avoir des bursts CPU périodiques mais de durée régulière. Enfin, le thread en charge de l’affichage pourrait utiliser des bursts CPU longs pour préparer la visualisation d’une scène suivie de son envoi au dispositif d’affichage.
L’alternance entre les bursts CPU et les phases d’attente est mise en œuvre par l’alternance de chaque thread entre différents états, permis par le mécanisme de changement de contexte.
Évolution de l’état des threads
Le kernel maintient des structures de données à propos de tous les threads actifs. Comme nous l’avons vu précédemment, un thread peut être dans l’un des trois états suivants :
- Running : ce thread est en ce moment en train d’utiliser un des processeurs pour exécuter des instructions ;
- Ready : ce thread est en attente d’un processeur pour exécuter des instructions ;
- Blocked : ce thread ne peut pas s’exécuter pour l’instant car il est en attente d’une valeur de retour pour un appel système bloquant.
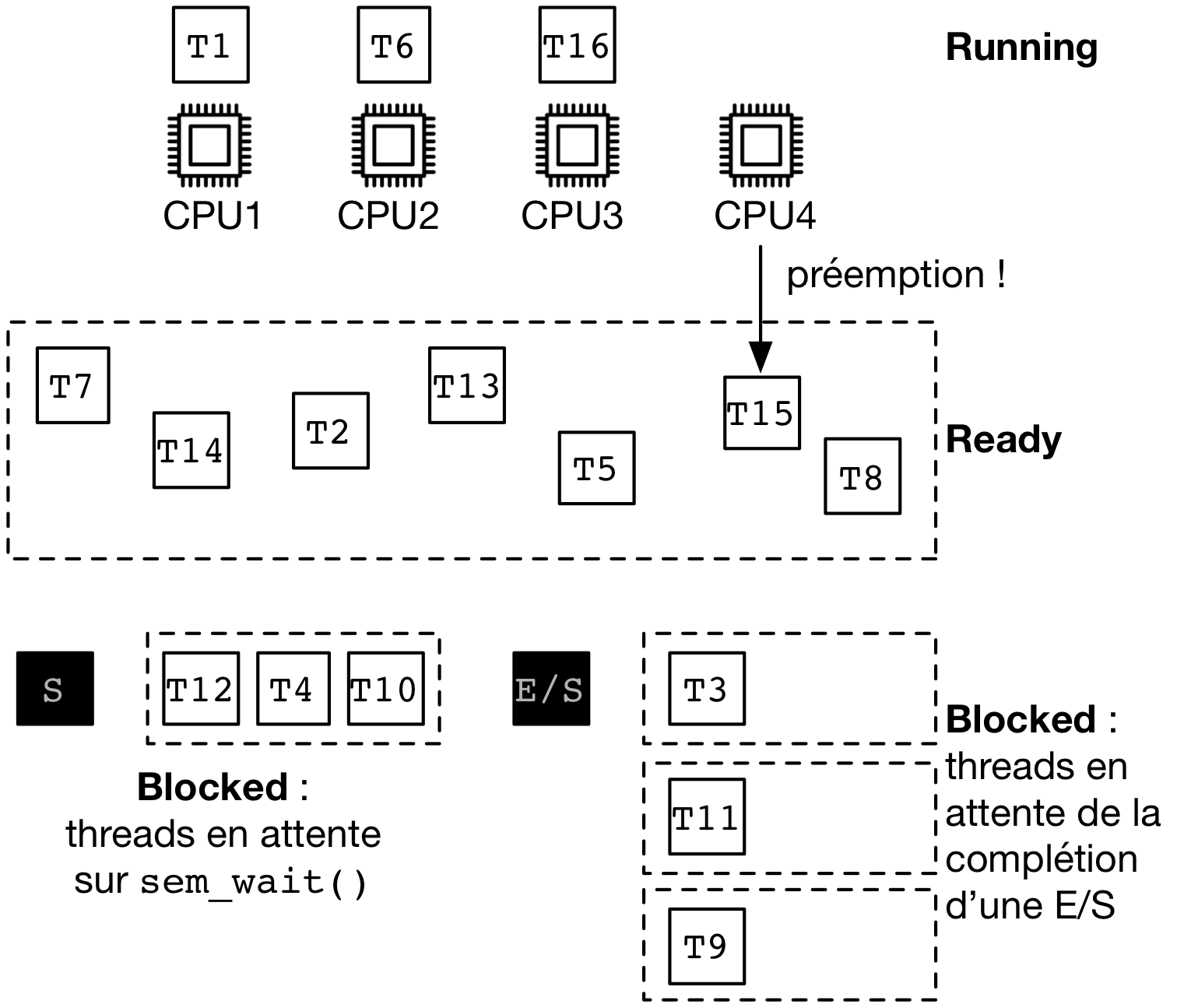
Un système fictif avec 16 threads et 4 processeurs est présenté dans l’illustration suivante.
Passage de l’état Running à l’état Blocked
Le passage de l’état Running à l’état Blocked advient lors de l’exécution d’un appel système bloquant appelé par le thread. Cet appel système bloquant peut être, par exemple, une demande d’entrée/sortie (écrire ou lire depuis le système de fichiers) ou un appel à une primitive de synchronisation comme par exemple pthread_mutex_lock(3posix) [http://sites.uclouvain.be/SystInfo/manpages/man3/pthread_mutex_lock.3posix.html] ou sem_wait(3posix) [http://sites.uclouvain.be/SystInfo/manpages/man3/sem_wait.3posix.html]. Les threads en état Blocked sont associés à une structure de donnée du noyau, qui joue le rôle de salle d’attente. Certaines de ces structures d’attente n’ont d’utilité que pour un seul thread, par exemple lorsque ce thread a demandé une lecture vers le système de fichiers. D’autres peuvent contenir plusieurs threads en attente. C’est le cas, par exemple, d’une structure d’attente pour un sémaphore. Il peut y avoir effectivement plusieurs threads ayant appelé sem_wait(3posix) [http://sites.uclouvain.be/SystInfo/manpages/man3/sem_wait.3posix.html] (T12, T4 et T10). Un appel à sem_post(3posix) [http://sites.uclouvain.be/SystInfo/manpages/man3/sem_post.3posix.html] va libérer l’un de ces threads, qui passera alors en état Ready.
Note
Pas de garantie d’ordre sur le passage de l’état Blocked à l’état Ready !
De manière générale, on ne peut pas faire d’hypothèse sur l’ordre dans lequel les threads en attente dans une structure d’attente commune vont être sélectionné pour passer dans l’état Ready, lorsque la condition d’attente sera remplie. Par exemple, si plusieurs threads appelent sem_wait(3posix) [http://sites.uclouvain.be/SystInfo/manpages/man3/sem_wait.3posix.html] sur le même sémaphore S dans un ordre donné, par exemple T12, puis T4, puis T10, il n’y a pas de garantie que lors des appels à sem_post(3posix) [http://sites.uclouvain.be/SystInfo/manpages/man3/sem_post.3posix.html] par d’autres threads ceux-ci passent en état Ready dans ce même ordre : le premier appel à sem_post(3posix) [http://sites.uclouvain.be/SystInfo/manpages/man3/sem_post.3posix.html] peut tout à fait passer T4 ou T10 en mode Ready avant T12.
Passage de l’état Running à l’état Ready
Un thread passe de l’état Running à l’état Ready lorsqu’il libère le processeur sur lequel il exécute actuellement des instructions.
On observe qu’avec uniquement les mécanismes définis précédemment, un thread qui ne génère aucun appel système pourrait rester dans l’état Running indéfiniment. C’est le cas, par exemple, d’un thread bloqué dans une boucle infinie ne comportant pas d’appel à la librairie standard. Si tous les processeurs venaient à être bloqués par des threads dans cette situation, alors la machine devient inutilisable. Par ailleurs, sans même considérer des boucles infinies, le temps d’occupation du processeur par le thread en cours d’exécution (son CPU burst) pourrait être particulièrement long, ce qui peut être problématique lorsque d’autres threads sont sujets à des contraintes de réactivité (par exemple, la réaction aux commandes utilisateurs ou la visualisation).
Les systèmes comme Linux utilisent donc une source d’interruption matérielle périodique (une horloge système) pour permettre de redonner le contrôle au système d’exploitation. À l’occasion de ces traitements d’interruption, il est possible de reprendre un processeur à un thread en état Running, en provoquant un changement de contexte. On dit alors que le thread a subit une préemption. C’est le cas de T15 sur notre exemple.
Passage de l’état Ready à l’état Running
La dernière transition consiste à restaurer l’état précédemment sauvegardé d’un thread en état Ready sur un processeur, et à reprendre son exécution.
Mise en œuvre du scheduler
La politique d’ordonnancement, que nous appellerons par la suite uniquement le scheduler par simplicité, est donc en charge de la prise de décision aux deux moments suivants :
- Lorsqu’un processeur devient disponible, suite au passage d’un thread en mode Blocked, le scheduler doit sélectionner un thread dans l’état Ready et le promouvoir à l’état Running sur ce processeur.
- Lorsqu’une interruption périodique est traité, le scheduler doit décider si un thread actuellement en état Running doit être préempté pour passer en état Ready.
Un scheduler qui prend des décisions pour les deux occasions (1) et (2) est dit préemptif (car il utilise la préemption d’un thread pour récupérer le processeur avant la fin de son CPU burst). Un scheduler qui ne prend de décision que lors de l’occasion (1) est non-préemptif. Il dépend d’appels réguliers par les threads à des appels systèmes bloquants, mais les threads ont la garantie que leurs CPU burst ne seront pas interrompus.
Objectifs
Il n’existe pas de scheduler parfait convenant à toutes les applications. Pour s’en convaincre, considérons les deux applications que sont la copie de fichier et l’application de calcul dans notre exemple précédent.
La priorité de l’application de copie de fichier est de subir le moins d’attente possible entre la disponibilité d’une valeur de retour d’un appel système vers le système de fichier, et l’envoi du prochain appel système pour continuer la copie, et éviter de ralentir l’opération de copie dans son ensemble. Pour ce thread, le délai d’attente entre sa mise en état Ready et l’obtention d’un processeur doit être la plus faible possible.
Pour l’application de calcul, le plus important est de pouvoir exécuter les instructions du long CPU burst avec le moins d’interruptions possibles. En effet, un changement de contexte est du temps perdu pour réaliser des opérations utiles (i.e., progresser dans la simulation). Par ailleurs, un thread qui est interrompu et replacé plus tard sur le processeur sera soumis à un phénomène de cache froid : les données qui étaient dans le cache, et donc accessibles avec un temps d’accès faible avant le changement de contexte, ont pu être remplacées par des données à des adresses différentes, utilisées par le thread qui a obtenu le processeur entre temps. Peupler de nouveau le cache avec les données nécessaire au calcul peut nécessiter de coûteux accès en mémoire principale et ralentir l’exécution.
Si l’on décide de privilégier l’application de copie, il est souhaitable d’interrompre le thread de l’application de calcul, mais cela va au détriment de ce dernier. À l’inverse, si on choisit de privilégier l’opération de calcul, alors l’opération de copie sera ralentie.
On peut définir cinq principaux critères pour mesurer la performance d’un scheduler :
- Du point de vue du système dans son ensemble tout d’abord :
- On veut pouvoir maximimiser l’utilisation du ou des processeur(s), c’est à dire la proportion du temps où ceux-ci exécutent des instructions des applications. Les opérations de changement de contexte ne sont évidemment pas considérées comme du travail utile pour ce critère.
- On peut vouloir maximiser le débit applicatif, c’est à dire le nombre de processus qui peuvent terminer leur exécution en une unité de temps donné (par exemple en une heure).
- D’autres critères sont applicables, cette fois-ci du point de vue de chaque application individuellement. On pourra par ailleurs s’intéresser à la distribution de ces métriques pour l’ensemble des applications, afin de savoir s’il existe un déséquilibre entre la métrique telle que perçue par une application et la même métrique perçue par une autre application :
- Une application peut souhaiter minimiser son temps total d’exécution, entre la création du processus et sa terminaison. Ce critère n’est pas nécessairement valide pour tous les types d’applications, par exemple il n’a que peu de sens pour une application interactive (par exemple, un shell), mais il est important pour des applications de calcul ou l’exécution d’un script par exemple.
- Ensuite, une application peut souhaiter minimiser le temps d’attente moyen, c’est à dire le temps écoulé entre la mise en état Ready (par exemple après la fin d’une entrée/sortie) et l’obtention d’un processeur. Cette métrique est particulièrement importante pour les applications interactives, comme un jeu ou une interface graphique.
- Enfin, une application voudra minimiser son temps de réponse, qui correspond à la somme entre le temps d’attente et le temps nécessaire pour terminer l’exécution de son burst CPU.
Nous allons dans la suite de ce chapitre décrire plusieurs scheduler classiques, en commençant par les scheduler non préemptifs, puis les schedulers préemptifs, et enfin les schedulers hybrides combinant plusieurs stratégies.
Note : Nous considérerons pour la présentation des schedulers uniquement le cas d’un seul processeur pour des raisons de simplicité, mais les algorithmes présentés ici peuvent être aisément étendu pour fonctionner avec plusieurs processeurs.
Le scheduler FCFS (First-Come-First-Serve)
Une première approche est d’exécuter les CPU bursts des threads dans l’ordre exact dans lequel ils ont obtenu l’état Ready (premier arrivé, premier servi). Ce scheduler n’étant pas préemptif, chaque CPU burst s’exécute intégralement avant de libérer le processeur pour un autre thread. Le temps de réponse avec un scheduler non préemptif est toujours égal au temps d’attente plus la durée du burst CPU, donc nous nous intéresserons principalement à ce premier critère.
L’exemple ci-dessous montre deux exécutions possibles pour 4 threads disponibles en état Ready simultanément, mais pour lesquels l’ordre d’ajout en état Ready a été effectué dans un ordre différent (T1, T2, T3, puis T4 dans un premier cas; et T2, T3, T4 puis T1 dans le deuxième cas).
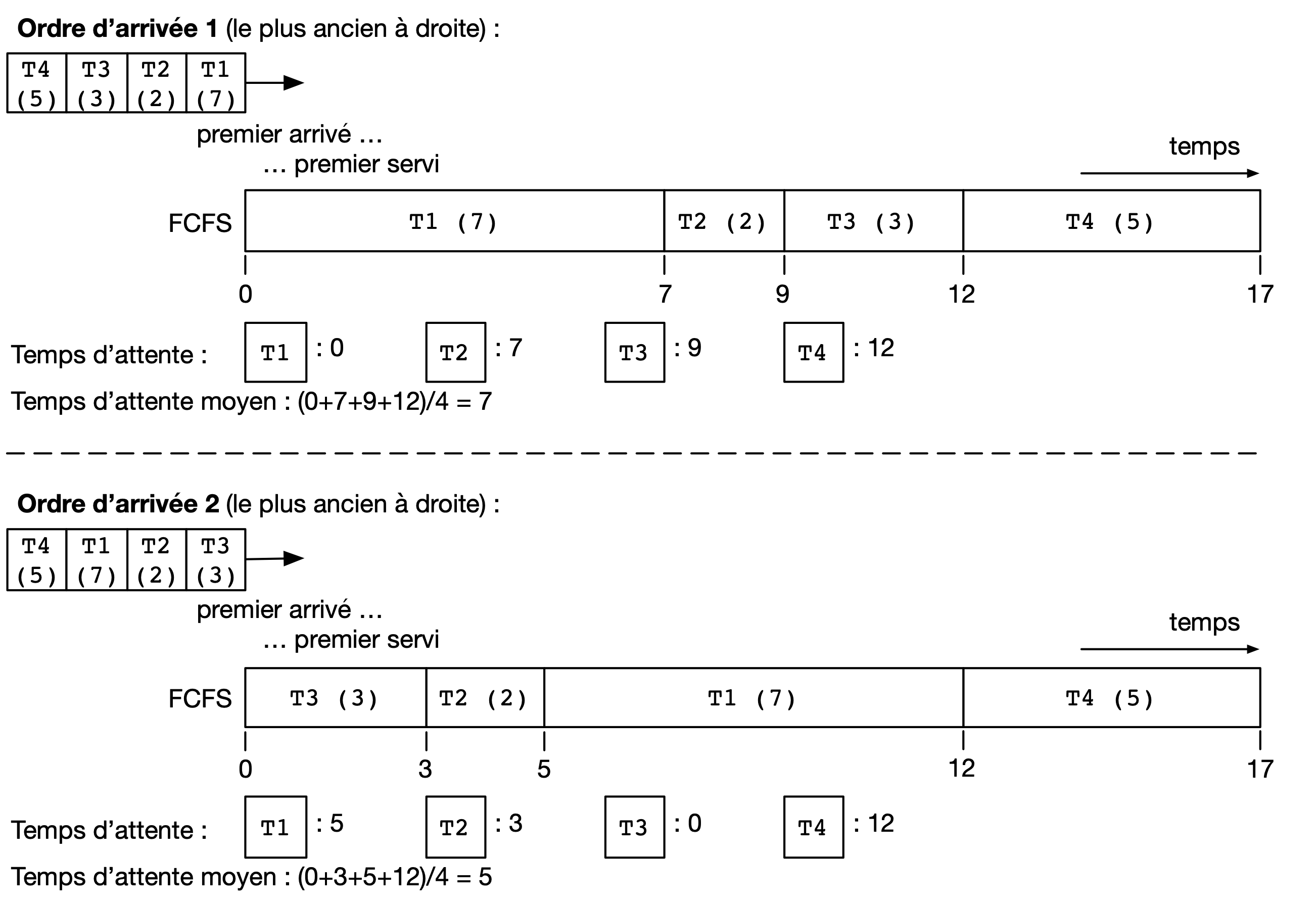
Ces figures présentent des diagrammes de Gantt, où le temps d’exécution de chaque CPU burst est représenté au cours du temps. En terme de débit applicatif et d’utilisation du processeur, cet algorithme est optimal, car il n’y a que trois changements de contexte : le temps perdu pour ces changements de contexte est donc minimal.
En revanche, si on considère le temps d’attente moyen pour chacun des threads, on observe que celui-ci diffère grandement entre le premier ordre d’arrivée et le second (de 7 unités de temps à 4.75 unités de temps). La raison est que dans la première configuration des CPU bursts courts (typiques des applications interactives ou utilisant de nombreuses entrées/sorties) se retrouvent coincées derrière un CPU burst long. Ce phénomène est appelé l’effet convoi (convoy effect en anglais). Il pénalise principalement les applications ayant des besoins d’interactivité.
Le scheduler SJF (Shortest Job First)
Le scheduler SJF (Shortest Job First) est un scheduler non préemptif qui a pour objectif de prévenir l’effet convoi. Lorsque plusieurs threads sont disponibles, le thread choisi est celui qui a le CPU burst à venir qui est le plus court. La figure ci-dessous montre le diagramme de Gantt où les threads obtiennent le processeur dans l’ordre du plus courte au plus long CPU burst.
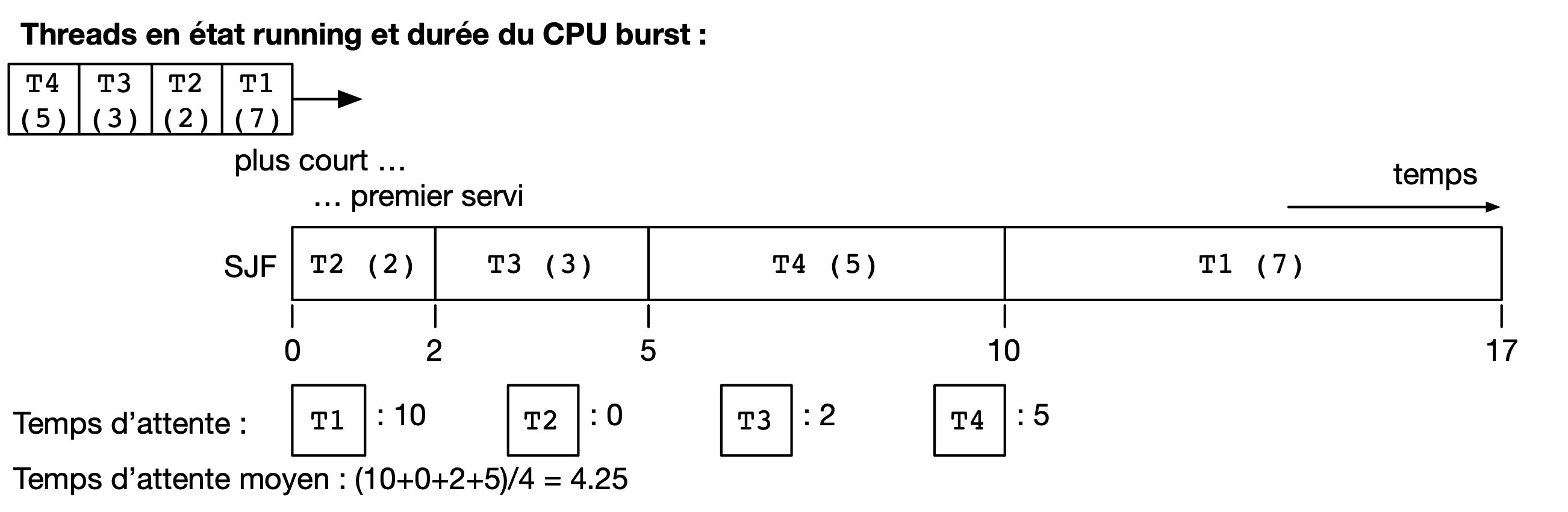
On peut facilement montrer que le temps d’attente moyen avec le scheduler SJF est le meilleur possible : toute permutation d’ordre ne peut qu’augmenter ce temps d’attente moyen. Toutefois, cet algorithme n’est pas réalisable en pratique et ne peut donc servir que de mètre étalon pour analyser la performance d’autres algorithmes. Il n’est en effet pas possible de connaître à l’avance la durée d’un CPU burst, car celle-ci dépend de l’exécution du code du thread, et donc de ses boucles, conditionnelles, appels de fonctions, etc.
En revanche, il est possible de tenter d’approcher cet algorithme en partant de l’observation suivante : la durée des CPU bursts pour un thread donné a souvent tendance à être régulière dans le temps. C’est à dire qu’un thread utilisant le CPU pour de courtes périodes de temps régulièrement aura souvent tendance à répéter ce comportement (c’est le cas, par exemple, des trois threads du jeu présenté précédemment). À l’inverse, un thread utilisant régulièrement le CPU pour de longues périodes de temps sera souvent (mais pas toujours) plus susceptible d’avoir un prochain CPU burst qui sera long.
Un scheduler estimant SJF pourrait ainsi conserver dans une structure de données la durée des x derniers CPU bursts de chaque thread. En appliquant une moyenne sur cette durée, le scheduler peut alors tenter de prédire la durée du prochain CPU burst, et choisir le thread dont la durée prédite est la plus courte.
On note toutefois que, si SJF est optimal en terme de temps d’attente moyen, il n’offre que peu de propriétés d’équité. Si il existe de nombreux threads avec des CPU bursts à venir courts (ou prédits comme tels) alors un thread avec un CPU burst long (ou prédit comme tel) pourrait ne jamais avoir accès au processeur, ou bien n’y avoir accès que bien plus tard.
Le scheduler préemptif RR (Round Robin)
Un scheduler préemptif peut choisir de préempter un thread en cours d’exécution sur un processeur, c’est à dire de passer ce thread en état Ready pour libérer le processeur pour un autre thread. Une décision de préemption peut être prise lorsque le système d’exploitation reprend la main sur le processeur lors de l’arrivée d’une interruption. Une horloge système dédiée à cet usage génère une interruption matérielle (tick) de manière périodique.
Un premier scheduler préemptif est le scheduler RR (Round Robin), expression anglaise que l’on pourrait traduire en français par “chacun son tour” [1]. Les threads en mode Ready sont placé dans un ordre arbitraire, sur laquelle on boucle (une fois la fin de cet ordre atteint, on recommence avec le premier thread, et ainsi de suite). À chaque tick d’horloge, le scheduler décide de systématiquement préempter le thread en cours d’exécution, sauf s’il n’existe aucun autre thread en état Ready. Le thread choisi pour passer en état Running est alors le suivant dans la liste. Celui-ci peut alors exécuter une fraction de son burst CPU avant d’être lui même préempté. La figure suivante illustre ce principe avec les mêmes threads que dans les exemples précédents, et avec un tick d’horloge toutes les deux unités de temps.
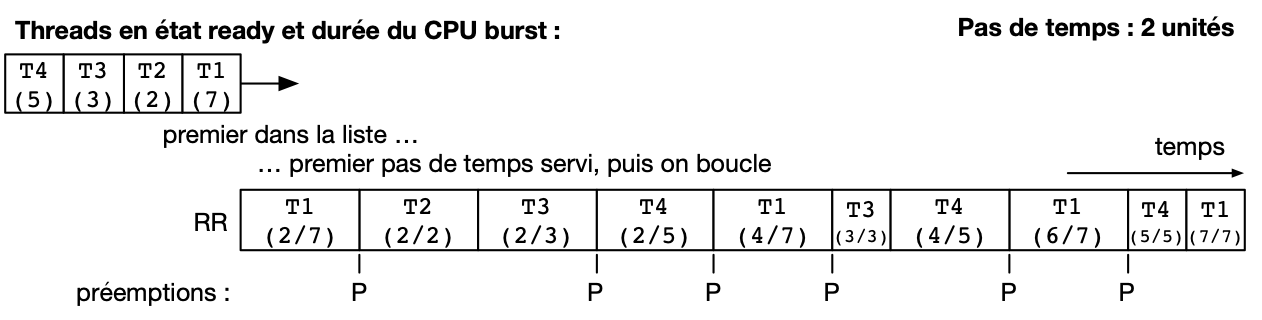
On observe que le thread T1 n’exécute que deux unités de temps sur les 7 de son burst CPU avant d’être préempté pour laisser la place à T2, qui laisse la place à T3 et ainsi de suite. Le troisième accès du thread T3 au processeur permet à ce thread de terminer son burst par une opération bloquante. .. On suppose dans cet exemple que le système d’exploitation remet l’horloge à 0 suite à la fin du thread en cours (ce n’est pas obligatoire).
Le scheduler RR permet à chaque thread d’accéder au processeur équitablement : même si un thread comme T1 ou T4 a un burst CPU long, les threads avec des bursts CPU courts comme T2 ou T3 auront accès au processeur de la même manière. En d’autres termes, le temps d’attente pour un thread sera toujours borné par le nombre de threads en état Ready multiplié par le durée du pas de temps.
On voit toutefois que ce scheduler n’est pas très efficace pour plusieurs raisons :
- Premièrement, il génère un grand nombre de changements de contexte (7 dans notre exemple). Comme discuté précédemment, non seulement ces changements de contexte nécessitent du temps processeur qui n’est pas utilisé pour des opérations utiles, mais ils entrainent surtout un phénomène de cache froid à chaque redémarrage d’un thread sur le processus à la suite d’un autre ayant rempli le cache avec ses propres données.
- Deuxièmement, comme le burst CPU d’un thread peut être interrompu avant sa complétion, il n’y a pas de relation directe entre le temps d’attente et le temps de réponse, et ce dernier peut devenir particulièrement long. Par exemple, bien que T3 ait un temps d’attente de 3 unités de temps, son temps de réponse (le temps entre son placement en état Ready et la fin de son burst CPU) est de 11 unités de temps.
- Enfin, il n’y a pas de distinction entre les threads ayant besoin du processeur pour des bursts courts ou ceux ayant des bursts longs, ce qui peut conjointement réduire la réactivité des threads interactifs ou effectuant de nombreuses entrées/sorties et diminuer la performance de ceux réalisant des calculs.
Note
Quelle fréquence pour l’horloge système ?
La fréquence de l’horloge système, qui génère les interruptions périodiques permettant au système d’exploitation de reprendre la main via la procédure de traitement d’interruption et (entre autres) de permettre au scheduler de préempter un processus en cours d’exécution, est un paramètre important pour la performance et la consommation d’énergie d’un système informatique. La valeur idéale dépend non seulement de l’architecture utilisée (mono- versus multi-processeur, machine alimentée par batterie ou non, etc.), de la configuration du système d’exploitation, mais aussi du type d’applications envisagées (application de type serveur, de type calcul intensif, applications interactives comme des jeux ou du traitement multimédia, etc.).
Par exemple, les versions initiales de Linux utilisaient une fréquence d’horloge de 100 Hz (100 interruptions par seconde) tandis que des versions ultérieures permettaient une fréquence plus élevée de 1.000 Hz. Une fréquence plus élevée permet de diminuer le temps d’attente moyen et augmente la réactivité du système. Elle entraîne une utilisation processeur par le système plus élevée, ce qui est particulièrement problématique pour les systèmes embarqués ou pour les ordinateurs portables alimentés par une batterie. Une fréquence élevée peut aussi augmenter le risque de pollution de caches dues aux préemptions plus important. Les versions modernes de Linux peuvent adapter la fréquence de l’horloge pour ne pas constamment réveiller un processeur lorsqu’il n’y a pas de tâche en état Ready, ou bien ne pas interrompre une tâche en état Running sur un processeur s’il n’y a pas de tâche en état Ready en attente pour le remplacer.
Schedulers à priorité
Dans un même système informatique, plusieurs applications cohabitent et toutes n’ont pas nécessairement la même priorité d’accès aux ressources. Par exemple, lors de l’utilisation d’une interface utilisateur en mode graphique, l’application actuellement utilisée par l’utilisateur local (par exemple un navigateur web) peut avoir besoin pour assurer une bonne réactivité d’accéder plus rapidement au processeur afin de limiter ses temps de réponses. À l’inverse, une opération de maintenance utilisée par le système d’exploitation, comme la mise à jour d’une base de données des fichiers pour permettre la recherche rapide par la suite, peut se contenter d’accéder au processeur uniquement lorsque celui-ci n’est pas sollicité par d’autres applications.
Un scheduler à priorité alloue à chaque thread un niveau de priorité donné. Lorsque le scheduler doit sélectionner un thread à exécuter, il commence d’abord par parcourir les threads ayant une haute priorité. En pratique, un scheduler à priorité maintiendra une liste circulaire pour chaque niveau de priorité. Lorsque le scheduler est appelé, il sélectionnera toujours le thread ayant la plus haute priorité et se trouvant dans l’état Ready. Si plusieurs threads ont le même niveau de priorité, un scheduler de type round-robin peut être utilisé dans chaque niveau de priorité. Il faut toutefois faire attention au problème de famine : si il existe toujours des threads de plus haute priorité qu’un thread donné, ce dernier pourrait ne jamais obtenir l’accès au processeur. Une solution simple à ce problème est de considérer une priorité de base, et une priorité courante. Au démarrage d’un cycle, les threads reçoivent leur priorité de base. Lorsqu’ils obtiennent l’accès au processeur, leur priorité courante décroit. Ceci donne une opportunité aux threads de priorité de base plus faible de s’exécuter. Un nouveau cycle commence lorsque tous les threads en état Ready ou Running ont atteint une priorité courante de 0.
On peut combiner le principe de priorité avec celui de préemption. Un thread qui passe dans l’état Running obtient alors un crédit de temps, ou quantum. Lors de l’allocation d’un processeur à un thread, le kernel démarre une temporisation avec ce quantum, correspondant à un certain nombre de clicks de l’horloge système (la longueur du quantum doit donc être un multiple de la période de cette horloge). Si un burst CPU atteint la fin de son quantum avant de réaliser une opération bloquante, celui-ci est préempté.
Les systèmes UNIX utilisent souvent des schedulers à priorité dynamique avec un round-robin à chaque niveau de priorité, en ajoutant par ailleurs des mécanismes adaptant la priorité de base des threads pour favoriser les threads interactifs. Par exemple, un thread qui termine toujours ses quantum de temps en étant préempté est considéré comme intensif en processeur (CPU-intensive). Il se verra allouer une priorité de base plus grande, mais avec un quantum de temps plus long. En revanche, un thread qui termine toujours ses bursts CPU avant la fin des quantum alloués est considéré comme intensive en entrées/sorties (interactive). Ce thread pourra obtenir une priorité de base plus élevé, mais associée à un quantum de temps plus court.
Note
Scheduler à priorité et synchronisation des threads
L’utilisation des primitives de synchronisation comme les mutex peut aller à l’encontre des priorités utilisées par le scheduler. Considérons par exemple le cas de deux threads TA et TB. TA doit répondre à des requêtes reçues depuis le réseau en mettant à jour une structure de données partagée, par exemple un graphe. Cette opération doit terminer le plus rapidement possible et ce thread est donc assigné à une priorité élevée. TB parcours de façon périodique la structure de données commune afin d’en extraire des statistiques (par exemple, toutes les 30 secondes). TB n’a pas de contrainte forte sur son temps de réponse mais l’opération qu’il exécute peut être assez longue. On assigne donc une priorité faible à TB. TA et TB accèdent à la structure de donnée en exclusion mutuelle, en utilisant un mutex m. On peut alors rencontrer la situation suivante : TB verrouille le mutex m en appelant pthread_mutex_lock(3posix) [http://sites.uclouvain.be/SystInfo/manpages/man3/pthread_mutex_lock.3posix.html] et commence son opération de parcours de la structure de données. TA passe alors de l’état Blocked à Ready à l’occasion de la réception d’une requête depuis le réseau. Le scheduler peut alors décider de préempter TB pour donner le processeur à TA, de plus grande priorité. Celui-ci va alors appeler pthread_mutex_lock(3posix) [http://sites.uclouvain.be/SystInfo/manpages/man3/pthread_mutex_lock.3posix.html], et être placé dans la file d’attente pour le mutex m. Si une attente active est utilisée, la situation est encore pire : le thread TA va alors boucler pour rien en attendant que son quantum de temps soit écoulé et que TB puisse récupérer un processeur pour terminer sa section critique. Cette situation où un thread de priorité élevé est bloqué en attente d’un thread de priorité faible pour accéder à une ressource exclusive comme un mutex est appelé une inversion de priorité. Une solution à ce problème est que lorsqu’un thread obtient un mutex sa priorité soit automatiquement augmentée pendant le temps d’utilisation de ce mutex, limitant ainsi les risques de préemption au milieu de la section critique. Une telle priorité dite plafond (priority ceiling) est associée à un mutex en utilisant l’appel pthread_mutexattr_setprioceiling(3posix) [http://sites.uclouvain.be/SystInfo/manpages/man3/pthread_mutexattr_setprioceiling.3posix.html]. Cette priorité doit être la priorité maximale accessible aux threads du processus courant, qui peut être obtenue avec l’appel sched_get_priority_max(3posix) [http://sites.uclouvain.be/SystInfo/manpages/man3/sched_get_priority_max.3posix.html].
Influencer la priorité des processus sous Linux
Les processus créés sous un système Linux ont une priorité qui s’applique par défaut à l’ensemble de leurs threads. La priorité originelle d’un processus dépend de la configuration du système et des droits du processus appelant l’appel système fork(2) [http://sites.uclouvain.be/SystInfo/manpages/man2/fork.2.html].
Il est possible d’influer sur la priorité d’un processus en utilisant la commande nice(1) [http://sites.uclouvain.be/SystInfo/manpages/man1/nice.1.html] ou la fonction nice(2) [http://sites.uclouvain.be/SystInfo/manpages/man2/nice.2.html] définie dans unistd.h. La commande nice(1) [http://sites.uclouvain.be/SystInfo/manpages/man1/nice.1.html] prend deux paramètres : un modificateur de priorité allant de +20 à -19, et la commande à exécuter. Une valeur élevée du modificateur (0 à +20) indique une priorité de plus en plus faible (la priorité avec +20 est la plus faible possible). On peut voir la valeur de nice comme une mesure de politesse, qui indique à quel point les threads de ce processus vont accepter de laisser passer les threads des autres processus devant eux pour l’accès au(x) processeur(s). Tout utilisateur peut utiliser une valeur de nice positive, car cela revient à réduire la facilité d’accès au processeur et non à s’octroyer des ressources supplémentaires. Une valeur négative (de -1 à -19) permet d’augmenter la priorité du processus. Leur utilisation nécessite en général des droits spécifiques, dits de super-utilisateur, afin d’éviter que des utilisateurs allouent systématiquement une priorité élevée à leurs programmes dans un environnement partagé, au détriment des autres utilisateurs.
L’exemple suivant montre le démarrage du programme ls(1) [http://sites.uclouvain.be/SystInfo/manpages/man1/ls.1.html] tout d’abord avec une valeur de nice de 15 (priorité faible) puis l’essai d’utilisation d’une valeur négative (priorité élevée) dont on voit qu’il est refusé par la commande pour cause de droits insuffisants.
utilisateur@systeme:~$ nice -15 ls -la .bash*
-rw------- 1 utilisateur groupe 64 Nov 16 21:33 .bash_history
-rw-r--r-- 1 utilisateur groupe 220 Jun 6 2018 .bash_logout
-rw-r--r-- 1 utilisateur groupe 3536 Oct 24 15:02 .bashrc
utilisateur@systeme:~$ nice --15 ls -la .bash*
nice: cannot set niceness: Permission denied
-rw------- 1 utilisateur groupe 64 Nov 16 21:33 .bash_history
-rw-r--r-- 1 utilisateur groupe 220 Jun 6 2018 .bash_logout
-rw-r--r-- 1 utilisateur groupe 3536 Oct 24 15:02 .bashrc
| [1] | L’expression Round-Robin a une origine intéressante : elle est un idiotisme de l’expression française “Ruban Rond” dont vous pouvez lire l’histoire sur Wikipedia [https://fr.wikipedia.org/wiki/Round-robin]. |