ICAME 2001 Future Challenges in Corpus
Linguistics, Louvain-la-Neuve, Belgium, 16-20 May 2001
Conference Programme
Keynote
Papers
Charles Fillmore
Armchair linguistics vs. corpus
linguistics revisited
Christopher Tribble
Corpora and teaching: adjusting the
gaze
Yorick
Wilks
Natural Language Processing and
Corpus Linguistics
Paper Presentations and Work-in-Progress Reports
Bas Aarts, Evelien Keizer,
Mariangela Spinillo & Sean Wallis
Which or what? A study of
interrogative determiners in present-day English
Hajar Abdul Rahim & Harshita Aini Haroon
Code-switching patterns and lexical
borrowing in Malaysian English
Eric Atwell
A Corpus of German and Italian
English Language Learners’
(Mis)pronunciations for Project ISLE: Interactive
Spoken Language Education
Roumiana Blagoeva
Personal reference and other
cohesive relations in learner writing: a
Mia Bostrom Aronsson
On clefts and information
structure in Swedish EFL writing
Nicholas Brownlees
Extending the ZEN Corpus (1641-1650): A Progress Report
Claudia Claridge
Sylvie De Cock
Recurrence and phraseology in learner
and native corpora of speech and writing
Roberta Facchinetti
The modal
verb MAY in contemporary British English: a study of the ICE-GB
Gaëtanelle Gilquin
Causative
‘cause’, ‘get’, ‘have’ and ‘make’: A preliminary study
Maurizio Gotti
SHALL and
WILL as first person future auxiliaries in a corpus of early
Natalia Gvishiani & Oksana Gerwe
From Non-Idiomatic to Idiomatic
Phraseology: A Contrastive Analysis of
Learner and Native Speaker Corpora.
Sebastian Hoffmann
Complex Prepositions Revisited:
Definitions and Corpus-Data
Hitoshi
Isahara, Toyomi Saiga & Emi Izumi
The TAO Japanese Learner Corpus of
Spoken English (The TAO Corpus)
Randall L.
Jones
Problems of Frequency Count in
a Corpus of German
Przemyslaw Kaszubski
GIVE and TAKE: towards overcoming of the bottlenecks in
learner corpus
linguistics
Bernhard
Kettemann
Göran Kjellmer
Natalie
Kübler
Corpora in Terminology and Translation Teaching: Methodological Approach
Uta Lenk
Time and time again - More and more stabilized expressions with ‘time’
Gunter Lorenz
Standard English in the Light of Corpus Evidence:
Aspect Rules or
Probabilities?
Fanny Meunier &
Inge de Mönnink
Assessing the success
rate of EFL learner corpus tagging
Dieter Mindt
Joybrato Mukherjee
A functional corpus analysis of prosody-syntax interactions in spoken English
JoAnne
Neff, Emma Dafouz, Honesto Herrera, Francisco Martínez,
Juan Pedro Rica, Mercedes Díez, Rosa
Prieto & Carmen Sancho
Contrasting Learner Corpora: The Use of Modal and Reporting Verbs in the Expression of Writer Stance
Bernard
Normier
Using corpora to construct dictionaries for information retrieval and text
mining applications
Arja Nurmi
‘I must let you knowe’: Modal
auxiliary must in Early Modern correspondence
Nelleke Oostdijk
Disfluencies in spoken
language data
Pascual Pérez-Paredes
Networking learner oral
corpora: integration perspectives
Susan Pintzuk & Ann Taylor
The effect of
quantification on verb-object order in Old and Middle English
Antoinette Renouf
WebCorp: providing a
renewable energy source for corpus linguistics
Geoffrey Sampson
Structural data on the
acquisition of writing skills
Josef Schmied
Learning English
prepositions in the Chemnitz Internet Grammar
Kristina Schneider
Extending the
Rostock Newspaper Corpus: Contrastive Analysis of German
Noëlle Serpollet
A contrastive
analysis of “mandative constructions” in two genres of the
French-English
Parallel Corpus INTERSECT: Is the health of the
‘mandative
subjunctive’ sustained by American English?
Robert Sigley & Janet Holmes
Looking at girls in English corpora
Nicholas Smith & Geoffrey Leech
Progress Report:
Grammatical Change in Recent Written English, based on
Patrick Studer & Peter Schneider
Classifying Newspaper
Headings in the ZEN Corpus
Irma Taavitsainen, Päivi Pahta &
Martti Mäkinen
Corpus of Early
English Medical Writing 1375-1750
Elena Tognini Bonelli
Towards a Corpus-driven
Approach
Gunnel Tottie & Hans Martin Lehmann
‘As’ as a relativizer
after ‘same’ in Standard English
Joe Trotta & Mats
Johansson
How big of a corpus is a
big enough corpus?
Åke Viberg
The verbs of
possession in Swedish from a crosslinguistic perspective (with
Anne Wichmann
Studying
attitudinal intonation: can corpora help?
Poster Presentations
Chris Allen
Niek Brom, Inge de Mönnink & Nelleke Oostdijk
An evaluation of the MF/MD method
Andreas
Eriksson
Advanced Swedish Learners' Use of
Tense, Mood and Aspect in English Argumentative Writing
Monika
Hägglund
The use of English phrasal verbs
in the (written and spoken) language of
Tomoko
Kaneko
A study on LINDSEI Japanese Data
Alexander
Kautzsch
The changing shape of English:
non-finite verb forms
Mikko Laitinen
Extending the Corpus of Early
English Correspondence to the 18th century
Ilka Mindt
Syntactic
constituents in main clauses
Vladimira Miňovská
What have our students learnt from
ICLE?
Lene
Nordrum
Nominal and verbal style in
English, Norwegian and Swedish Expository Prose
Pam
Peters & Adam Smith
Textual structure and segmentation
in online documents
Caren
Sanders
New structural text classification
patterns in the ZEN Corpus
Anna-Brita
Stenström
Ann
Taylor, Anthony Warner, Susan Pintzuk & Frank Beths
The York-Helsinki Parsed Corpus of Old
English
Shunji
Yamazaki
Syntactic Characteristics of
Adjectives
Maria Teresa Prat Zagrebelsky
‘Even if’ or ‘even though’? A
corpus-based investigation of the Italian-ICLE subcorpus
Software Demonstrations
Michael Barlow
ParaConc: A
Parallel Concordancer
Estelle Dagneaux, Sylviane Granger, Fanny Meunier, Stephanie
Petch-Tyson
& Xavier Vilret
A web
interface to the International Corpus of Learner English
Knut
Hofland
Charles Meyer
Paul
Rayson
Wmatrix: a
web-based corpus processing environment
Sean
Wallis
Performing scientific experiments in parsed corpora with ICECUP
3.1
Martin
Wynne & Oliver Mason
Charles
Fillmore (University of California at Berkeley / International Computer Science
Institute, USA)
Armchair
linguistics vs. corpus linguistics revisited
A decade ago I offered some pronouncements on
the opposition between reliance on corpus data for discovering and supporting
linguistic generalizations, on the one hand, and the need to appeal to the
intuitive knowledge of native speakers on the other hand1. In that context I had in mind
people who were quite sure that only corpus evidence, or only introspection,
was valid for doing proper empirical linguistics. My peace-making position was
that one couldn't succeed in the language business without using both
resources: any corpus offers riches that introspecting linguists will never
come upon if left to their meditations; and at the same time, every native
speaker has solid knowledge about facets of their language that no amount of
corpus evidence, taken by itself, could support or contradict.
In the meantime I have been forced to face
these same issues in the course of a six-year research project dedicated to
learning facts about the English lexicon; in this project, corpus evidence is
the main tool, and researchers who are speakers of English are hired to work with
this resource and decide how to use what it gives us. Since for our purely
lexicographic purposes, corpus evidence and our ability to interpret it provide
more lexically specific information than can be found in dictionaries or
lexical descriptions known to us, we are daily rewarded with insights about our
language that introspection alone, however disciplined, could never direct us
to. The limitation to lexical observations, of course, allows us to escape
larger-scale and "deeper" kinds of linguistic facts: our work can
proceed with "canonical" examples of the uses of the lexical units we
target for study.
In this paper I will describe a
lexicon-building effort called FrameNet and I will discuss some of the tensions
my colleagues and I face between (a) the need for labor-intensive (and slow)
work by linguistically sensitive trained annotators, and (b) the desire to
maximize the use of computational means for organizing the material,
facilitating the coding process, assigning tentative annotations, enhancing the
editing and correcting activities, and collecting and summarizing results from
the annotations. The project is dedicated to creating a "frame-based"
lexicon cum thesaurus of modern English in which each lexical unit is described
in terms of the semantic frame which underlies its interpretation and is
provided with descriptions of its semantic and syntactic combinatorial
properties, as attested by examples taken from the British National Corpus. I
will sketch the most important aspects of the procedure and will characterize
the database of annotated sentences as well as the means of deriving the
combinatorial descriptions automatically from the annotations.
My discussion will cover the evolution of the
project's goals from a fairly simply-defined starting place that emphasized
governors and the nature of their dependents to a system that should allow us
to provide useful information about implicit arguments, support verbs,
selectionally transparent nouns (names of parts, types, aggregates, and quantities),
frame inheritance and frame blending (where semantic frames are seen as
complexes or blends of other frames), and more.
Christopher
Tribble (King's College, London University, United Kingdom)
Corpora
and teaching: adjusting the gaze
When we look at a corpus in order to find answers to
questions, what is the nature of the thing we are observing, and what do we
focus on? To date, the development of corpus linguistics has been largely
motivated by the interests of descriptive linguists, lexicographers and
grammarians, and literary scholars, along with language engineers and the
natural language processing community. Although language teachers have
indirectly benefited from the fruits of the labours of these different groups
through the publication of new dictionaries and grammars, there has, as yet,
been relatively little direct use of corpus data by language teachers and
students in real language classrooms (despite earlier, highly sanguine
predictions by distinguished corpus linguists - e.g.
Sinclair 1991). In this paper, I shall outline some of the reasons why corpus
data might, or might not, be being used in language teaching, summarise what
has been achieved in this area despite possible problems (notably through the
work of Tim Johns at Birmingham University), discuss why so relatively little
use of corpora has been made in language classrooms to date, and outline ways
in which corpora might make a greater contribution to language teaching in the
future.
In developing this argument, I shall first have to
assess the extent to which corpus data is an appropriate resource for language
learners. In so doing I will re-visit a significant moment in the development
of the relationship between language teaching and corpus linguistics (an
exchange between H.G. Widdowson and J.M. Sinclair in the early 1990s (Widdowson
1991, Sinclair 1991, 1997). I shall also have to consider later arguments
around which model (if any) of the English language is most appropriate for bilingual
students (Amon 2000, Granger 1998, Pennycook 1999, Phillipson 2000, Seidlhofer
2000 & forthcoming, Jenkins forthcoming) and the implications that
decisions in this area have for corpus design for language learners. This move is essential as I strongly hold
that an uncritical adoption of corpus data per se is an insufficient stance
when considering the needs of students and teachers of foreign or second
languages.
Having established a position in relation to whether
corpus linguistics might have something to say to language learners and
teachers, and what corpus resources language learners and teachers might
require to achieve their ends, I shall then demonstrate some of the areas in
which I feel corpus linguistics can make a contribution to language learning
and teaching. In this part of my presentation, I shall take as examples recent
work by Ken Hyland (Hyland, 2000), Joanna Channell (Channell 2000), and some of
my own work with Paul Thompson (Thompson, P. and C. Tribble forthcoming) and
develop a case for the use of corpus resources and tools in general and special
purposes language teaching - a case which asks corpus linguists to
adjust their gaze if they wish to take into account the needs of the millions
of students who are currently studying English.
In the last section of the paper, I shall present
results from a recent email survey which assesses the extent to which language
teachers do and do not use corpora in their teaching, and gives some insights
into the reasons for what I consider to be a surprising under use of a valuable
resource. I shall then propose some principles which teachers and students
might use when considering using corpora in their own endeavours.
References
Ammon,
U.
(2000) Towards more fairness in international English: linguistic rights of
non-native speakers? In Phillipson, R. (ed.) Rights in language.
Lawrence and Erlbaum, London.
Channell
J.
(2000) Corpus based analysis of evaluative lexis. In Hunston, S. and Thompson,
G. (eds) Evaluation in text. Oxford University Press, Oxford.
Granger, S. (ed.) (1998) Learner
English on Computer. Longman, Harlow.
Hyland,
K.
(2000) Disciplinary discourses: social interactions in academic writing.
Longman, Harlow.
Jenkins,
J.
(forthcoming) A sociolinguistically-based, empirically researched pronunciation
syllabus for English as an international language, Applied Linguistics.
Pennycook,
A.
(1999) Pedagogical implications of different frameworks for understanding the
global spread of English. In Grutzmann, C. (ed.) Teaching and
learning English as a global language. Staufenburg
Verlag, Tübingen.
Phillipson,
R. (ed) (2000) Integrative comment: living with vision and commitment. In
Phillipson, R. (ed.) Rights in Language. Lawrence and Erlbaum: London.
Seidlhofer, B. (2000) Mind the gap,
English as a mother tongue vs. English as a lingua Franca, Views 9(1):
51-68.
Seidlhofer,
B.
(forthcoming) Closing a conceptual gap: the case for a description and pedagogy
of English as a lingua franca, Applied Linguistics.
Sinclair,
J.M. (1997) Corpus Evidence in Language Description. In Wichmann, A.,
Fligelstone, S., McEnery, T. and Knowles, G. (eds) Teaching and language
corpora.: Longman, London and New York, pp. 27-39.
Sinclair,
J.M. (1991) Shared knowledge. In Alatis, J.E. (ed.) Linguistics and
language pedagogy: the state of the art. Georgetown University Press,
Washington D.C., pp. 489-500.
Thompson,
P. and
Tribble, C. (forthcoming) Looking at citations: using corpora in English
for academic purposes. In Tribble, C. and Barlow, M. (eds) Special issue on
corpora in language learning and teaching, Language Learning and Technology
5(3) http://llt.msu.edu/.
Widdowson,
H.G. (1991) The description and prescription of language. In Alatis, J.E.
(ed.) Georgetown University round table on languages and linguistics 1991.
Georgetown University Press, Washington, D.C., pp. 11-24.
Yorick Wilks (University of Sheffield, United Kingdom)
Natural Language
Processing and Corpus Linguistics
So far
has Natural Language Processing (NLP) moved in the last ten years that the
title of this talk now has a strong semantic redundancy, far removed from the
days when (according to a recent posting) Chomsky could say that there was no
such thing as corpus linguistics, a sentiment that many in NLP might then have
echoed, even if they had agreed with Chomsky on virtually nothing else! I grew
up within the Artificial Intelligence (AI)/NLP tradition as a passionate
anti-Chomskyan who was happy to satirise Chomsky’s remarks about the
irrelevance of data but did not do a great deal of data gathering myself.
However, that was not for any reasons of principle but rather that data was
hard to store on primitive machines and, even when it was available, there was
insufficient processing power for interesting computations. A classic example
would be Sparck Jones’ (1966) thesis on Semantic Classification, which
reclustered the data of Roget’s Thesaurus, but which actually contained no
computational results because the matrices required by the clumping theory she
used could not be fully computed in those days. Nonetheless, the thesis was,
rightly, highly influential. My own thesis, contemporary with hers and from the
same research laboratory, computed only over ten small philosophical texts and
ten randomly chosen newspaper editorials as controls; an absurdly small sample
by today’s standards but near the limit of what was feasible at the time.
Within that
historical anecdote is a contrast of kinds of corpus, which will be important later
in the talk: between prose corpora (what is normally meant by the word corpus)
and corpora that are dictionaries or thesauri. All are man-made and consisting
only of words, but the latter are in some sense metacorpora, and one looks in
them not for usage but for facts about usage, based on observation and
intuition.
The
talk begins with a listing of NLP modules, or separable tasks, that are
responsive to some form of learning over corpora (in the standard sense above),
and which use supervised or unsupervised methods or both. Some classic corpora
are named, and a word of caution is given about the use of ‘unsupervised’ which
is sometimes extended from its proper meaning as (roughly): learning from data
but without the provision of correct target structures for that data’. In that
sense, machine translation (MT) would be learned in a supervised manner when
exposed only to parallel (translated) corpora, but if MT could be learned
(which is highly doubtful and never yet demonstrated) only from a range of
monolingual texts in various languages, that would be unsupervised learning.
This issue is sometimes muddled up with that of provided corpora marked up in a
sophisticated manner for supervised learning: such as marking each content word
with its appropriate word-sense against some dictionary sense list, so as to
train word-sense disambiguation (WSD). This is a highly labour intensive task
and researchers yearn for easier methods of acquiring training data, though
this is not the same as lack of supervision. For example, those same parallel
language texts could be used to tag the senses of one word against those in
another but this would not be unsupervised learning, just cheap supervision
(e.g. if ‘duty’ were tagged by occurring opposite translations Œdevoir vs.
‘impot’ in French). To put the matter as Manning and Schuetze do (1999):
unsupervised learning is a clustering task and supervised learning a
classification one.
There
is still much mileage, to judge from bulletin board postings, of new forms of
the old opposition of generative and corpus linguistics, but I would suggest
that, if we leave aside the wholly unreformed Chomskyans, where any kind of
objective evidence is concerned, then that opposition may be correlated with
access to the two sorts of corpora I distinguished above: corpora and
metacorpora (i.e. electronic dictionaries and thesauri). I then describe a
small piece of recent work with a colleague (1998) where we first calculated
what kinds of links of WSD to part-of-speech tagging were possible from the
distribution of homographs in LDOCE. We then checked against a small text
corpus which we had hand tagged with senses to see what level of facts we
actually found. The distinction between the two stages, computation over a
lexicon then a corpus, corresponds roughly to a Gedankenexperiment and then an
experiment, and also to a form of generative vs. corpus linguistics distinction
where generativity is expressed in a dictionary or metacorpus.
One
can see a stronger form of this by moving from the WSD to the issue of novel
senses in text and asking the question as to whether novel sense detection can
ever be linked to corpus methods: can it even in principle be marked up for in
training and test texts by humans? In some sense the answer must be no by
definition, although we might seek the presence of a new sense where a tagger
had been unable to assign any existing sense to a word. It might be interesting
to consider this within the Generative Lexicon paradigm (GL, Pustejovsky 1995),
which is very much a generative approach in the sense of being (a) prescient
about real corpora and (b) attempting to compact lexicons by full intuitive
compactions of their content. We ask how much of novel sense, with which
Pustejovsky claims to deal, is of this type and cite a recent computation over
LDOCE by Kilgarriff (2001) that tries to show that virtually no novel sense is
captured by GL. Is this a real or a Gedanken experiment? Is it fair to GL?
Finally, we look
at a different, brute force approach, to attempting to locate novel sense in
corpora -- an area hitherto unexplored we believe -- this time unsupervised, by
asking how many of the agent noun + verb combinations in the BNC are unique --
uniqueness, or at least very low frequency being a place where novel sense
might be expected to emerge. We then look at these numbers -- which are
surprisingly large, at least to me -- and ask which of them are comprised of
nouns and verbs which are themselves frequent in the BNC. I then display what
we get and ask if it has any significance for the issue of constraints on
possible levels of WSD.
Bas Aarts, Evelien Keizer, Mariangela
Spinillo & Sean Wallis (University College London, United Kingdom)
‘Which’
or ‘what’? A study of interrogative determiners in present-day English
The determiner slot in English interrogative Noun Phrases allows for
three possible occupants, namely which,
what and whose, and their
variants ending in -ever: whichever, whatever and whosever. In this paper we will be
looking only at the first two of these, which
and what, in structures like the
following: Which films do you like? /
What films do you like? These expressions are close in meaning, so the
question arises as to what factors influence the choice of one over the other
determiner. Our aim in this paper is twofold: first we will demonstrate how
interrogative NPs such as those exemplified above can be retrieved from the
British component of the International Corpus of English (ICE-GB), using Fuzzy
Tree Fragments (FTFs). The second aim of the paper is to show how the search
results can be used to investigate what determines the choice of determiner in
NPs like those shown above.
Our findings show that although the accounts found in the grammar
books regarding the choice of which or
what as interrogative determiners
seem to be valid in most cases, some modifications are necessary. We have found
that while the use of what implies a
choice of answers from a seemingly unlimited set, the set may in fact have an
upper or lower bound, or both. We have also found that pragmatic factors can
play a role, such as speaker and hearer expectations. Finally, there are a
number of instances that simply defy the rules. Given the examples from ICE-GB
that we examined, the standard accounts of the use of which and what as
interrogative determiners are probably best regarded as expressing a tendency,
which may be influenced, or superseded, by a variety of factors.
Hajar Abdul
Rahim & Harshita Aini Haroon (Universiti Sains Malaysia, Malaysia)
Code-switching
patterns and lexical borrowing in Malaysian English
Odlin (1989) differentiates two kinds of language
mixing: borrowings from a second language into the native language and code-switching,
a systematic interchange of words, phrases, and sentences of two or more
languages. Whilst Odlin considers borrowings as a kind of language mixing,
Hatch & Brown (1995) stress the need to distinguish between borrowings and language
mixing. In borrowing, the words become part of the language used by
speakers of that language, as though they were native words such as garage
(French) and pizza (Italian). In mixing and switching, the words are
momentarily borrowed by individual speakers in order to create effects.
Code-switching/language mixing between Malay and
English is prevalent in Malaysian English, a variety of English spoken by
Malaysians. Another important feature in Malaysian English is borrowing. This
paper, based on a corpus study of Malaysian English, attempts to describe the
language mixing patterns and the linguistic (semantic and pragmatic) features
of borrowings (from Malay) in Malaysian English.
The study
analysed a set of 11 Malay words extracted from a 60,000-word Malaysian English
corpus. The corpus comprises 6 text-types (2 spoken and 4 written). The spoken
texts are classroom lessons and broadcast news whilst the written texts are
student essays, press news reports, press editorials and non-academic writing.
Each text type was compiled in 5 files of 2,000 words each. The WordSmith Tools
(1998) package was employed to locate the Malay words in the corpus. A wordlist
was initially generated from which the 11 Malay words were extracted.
The words
analysed are balik kampung, changkuls,
ikan kembong, jahanamkan, malu, nabi, padi, pahala, rakyat, samsu and ummah. The words and their meanings in
English are listed below:
Balik kampung
The word balik means ‘return’ whilst kampung means ‘village or where one comes from’. The compound balik
kampung means ‘going home’, not to one’s residence but
to the place where one’s parents and family are.
Changkuls
The English
pluralised form of the word changkul, which is Malay for ‘hoe’.
Ikan kembung
The word ikan means ‘fish’, and ‘kembong’ literally means ‘bloated’.
The compound ikan kembong is a species of mackerel common in
Malaysia.
Jahanamkan
The root form jahanam which
means ‘ruin/ complete damage or destruction’ is borrowed from Arabic. The word jahanamkan means
‘to ruin or damage completely’.
Malu
The senses of malu include ‘shy, ashamed, embarrassed’.
Nabi
Borrowed from
Arabic, nabi means ‘prophet’.
Padi
Rice which is
growing or still in the husk / paddy.
Pahala
‘Reward’ in the
religious context.
Rakyat
‘The people’ or
‘citizens of a state’.
Samsu
The word refers to
‘a low-grade alcohol, similar to toddy, produced locally’.
Ummah
‘People’in the
religious context [+ Muslim] and [+brotherhood].
The 11
items analysed above turned out to be words that occur in the written texts
only. An analysis of the meanings of the words suggests that the Malay items
could be categorised as follows:
1.
1.
Words that have no English
equivalent.
2.
2.
Words that have a close
English equivalent.
3.
3.
Words that have an English
equivalent (same semantic content).
The words in the first category are balik kampung, samsu and ummah. They
contain cultural information that is peculiar to the Malaysian social/cultural
context: balik kampung- peculiar initially to Malays, it has become a Malaysian
phenomenon particularly around holidays. samsu- this locally produced alcohol
is popular among certain socio-economic groups; ummah– this is used particulary
to refer to people of the Islamic faith.
The words that fall into the second category are ikan kembong, jahanamkan, malu, and pahala. Although there are near
equivalents that sufficiently provide the basic semantic content of the words,
the inclination to use the Malay words is due to various reasons. The use of ikan
kembong instead of ‘mackeral’ is a case of familiarity of term within the
social group. The use of pahala instead of ‘reward’ is very likely motivated by
the semantic information [+religious] and [- material] inherent in pahala, but
which is not included in the meaning of ‘reward’.
Words that fall into the third category, i.e. those
that have English equivalents, are changkul,
nabi, padi, and rakyat. The
insistence on using Malay words when there are English equivalents may be
attributed to the language choice of users and the interpretation of the
message. Although the English equivalents have the same conceptual meaning, the
use of the Malay words is possibly motivated by the pragmatic effects the
connotations of the words have in the interpretation of the message.
The study has used a limited number of words
extracted from a small corpus. One needs to consider this limitation before any
conclusions could be made on the 1) language mixing patterns and 2) the
linguistic features of borrowings in Malaysian English. However, based on the
data obtained and the assumption that borrowing is a long-term process within
the language of a social group and mixing is a momentary individual phenomenon,
it is suggested that words that have no English equivalent are borrowed in
Malaysian English. The words that have the English equivalent and near
equivalent are used as a code-switching/mixing strategy.
In all three categories of words, the semantic
content of the Malay words is not altered in the context of Malaysian English.
The semantic content is maintained as it contributes towards the interpretation
of the message. The pragmatic information of the words in all categories is
also maintained in the Malaysian English context. However, the pragmatic
content seem to be more necessary in the cases of words that have the English
equivalent.
References
Hatch,
E.
and Brown, C. (1995) Vocabulary, Semantics, and Language Education.
Cambridge University Press, Cambridge.
Odlin, T. (1989) Language
Transfer. Cambridge University Press, Cambridge.
WordSmith Tools Version 3.0. Oxford
University Press.
Eric Atwell
(University of Leeds, United Kingdom)
The goal of project ISLE (Interactive Spoken Language Education) was to exploit available speech
recognition technology to improve the performance of computer-based English
language learning systems. The ISLE project also collected a corpus of audio
recordings of German and Italian learners of English reading aloud selected
samples of English text and dialogue, to train the speech recognition and
pronunciation error-detection modules. Speech recordings were collected from
non-native, adult, intermediate learners of English: 23 German and 23 Italian
learners. In addition, data from two native English speakers was collected for test
calibration purposes. The corpus contains 11484
utterances; 1.92 gigabytes of WAV files; 17 hours, 54 minutes, and 44 seconds
of speech data. The corpus is based on 250 utterances selected from typical
second language learning exercises. It has been annotated at the word and the
phone level, to highlight pronunciation errors such as phone realisation
problems and misplaced word stress assignments.
In addition to
the blocks of individual speaker data, we created five pseudo-speaker blocks of
data by selecting some utterances covering all speakers, in order to be able to
check inter and intra-annotator consistency. Overall, agreement rates were low: at best, annotators agreed in only 55%
of cases when deciding where and what an error is. Even localisation of the
error alone, deciding where the error is but not what the correction should be,
shows at best a 70% agreement between annotators. In some cases this was
because annotators flagged errors in the same word but not the same exact
location (phoneme). Given the poor inter-annotator agreement on the exact
location and nature of errors, the target one might reasonably set for
diagnosis programs should be limited to only those errors which annotators
agree on; this applies not only to the ISLE system but to other pronunciation
correction systems.
Statistics
extracted from the error-annotated corpus allow us to see which are the most
common sources of English pronunciation errors for native speakers of Italian
and German. For both Italian and German native speakers, we have empirical
evidence on which are the most difficult
phones and which phones account for most errors (equivalent to the type/token
distinction in corpus frequency counts), and which words account for the most
errors. The Italian speakers made an average of 0.54 phone errors per
word with a standard deviation of 0.75, while the Germans made an average of
0.16 phone errors per word with a standard deviation of 0.42. This difference
may be partly due to the greater phonological similarities between German and
English than between Italian and English. Examples of pronunciation errors at
each level are given, with an indication of whether these are expected (owing
to L1 interference and attested in the EFL literature) or
unpredictable/idiosyncratic.
We welcome corpus re-use by other researchers,
who can acquire a copy (on 4 CDs) from ELDA. At the end of the project, system
development stopped at the Demonstrator stage, and future prospects for
migration to a commercial ELT package are uncertain; however, we hope that the
ISLE Corpus may be a useful achievement of the project.
The
ISLE project consortium included: Dida*el S.r.l. (Milan, Italy), Entropic
Cambridge Research Laboratory Ltd. (Cambridge, UK), Ernst Klett Verlag
(Stuttgart, Germany), University of Hamburg (Germany), University of Leeds
(UK), University of Milan Bicocca (Italy). Project ISLE was supported by the European
Commission under the 4th framework of the Telematics Application
Programme (Language Engineering Project LE4-8353). The corpus is distributed
for non-commercial purposes through the European Language Resources
Distribution Agency (ELDA).
Acknowledgements
This paper reports on a
collaborative research project; I gratefully acknowledge contributions of
number of collaborators, principally: Wolfgang
Menzel, Dan Herron, and Patrizia Bonaventura, University of Hamburg (Germany);
Steve Young and Rachel Morton, Entropic Cambridge Research Laboratory Ltd.
(Cambridge, UK); Jurgen Schmidt, Ernst Klett Verlag (Stuttgart, Germany); Paulo
Baldo, Dida*el S.r.l. (Milan, Italy); Roberto Bisiani and Dan Pezzotta,
University of Milan Bicocca (Italy); and last but definitiely not least, my
colleagues at the University of Leeds (UK), Peter Howarth and Clive Souter. This research was
supported by the European Commission under the 4th framework of the
Telematics Application Programme (Language Engineering Project LE4-8353). The
corpus is distributed for non-commercial purposes through the European Language
Resources Distribution Agency (ELDA).
I am particularly endebted
to Wolfgang Menzel for setting up and leading the ISLE project; and to Uwe Jost
for proposing Leeds University as a contributor to the project. I am also grateful that the ISLE project as
allowed me to achieve a long-standing ambition to contribute my own linguistic
data to a Corpus!
References
Atwell, E. (1999) The
Language Machine. British Council, London.
Atwell,
E., Howarth, P., Souter, C., Baldo, P., Bisiani, R., Pezzotta, D., Bonaventura,
P., Menzel, W., Herron, D., Morton, R., and Schmidt, J.
(2000) User-Guided System Development in Interactive Spoken Language Education,
Natural Language Engineering Journal 6(3-4):229-241, Special
Issue on Best Practice in Spoken Language Dialogue Systems Engineering, Cambridge
University Press, Cambridge.
Eisen, B., Tillmann, H., and Draxler, C. (1992) Consistency of
Judgements in Manual Labelling of Phonetic Segments: The Distinction between
Clear and Unclear Cases. In: Proceedings of ICSLP’92: International
Conference on Spoken Language Processing, pp. 871-874.
Herron, D., Menzel, W., Atwell, E., Bisiani, R., Daneluzzi, F., Morton,
R.
and Schmidt, J. (1999) Automatic localization and diagnosis of
pronunciation errors for second language learners of English. In Proceedings
of EUROSPEECH'99: 6th European Conference on Speech Communication and
Technology, vol. 2, pp.855-858. Budapest, Hungary.
Hunt, J. (1996) The
Ascent of Everest. Ernst Klett Verlag, English Readers Series,
Stuttgart.
Menzel, W., Atwell, E., Bonaventura, P., Herron, D., Howarth, P.,
Morton, R., and Souter, C. (2000) The ISLE Corpus of non-native spoken
English. In Gavrilidou, M.,
Carayannis, G., Markantionatou, S., Piperidis, S. and Stainhaouer, G. (eds) Proceedings
of LREC2000: Second International Conference on Language Resources and
Evaluation, vol. 2, pp.957-964. Athens, Greece. Published and distributed
by ELRA - European Language Resources Association.
Young, S., Kershaw, D., Odell J, Ollason, D., Valtchev, V. and Woodland,
P. (1999) The HTK Book 2.2. Entropic, Cambridge.
Power, K., Morton, R., Matheson, C., and Ollason, D.
(1996) The Graphvite Book 1.1. Entropic, Cambridge.
Thomas,
J.
(2001) Negotiating meaning: a pragmatic analysis of indirectness in
political interviews. Invited plenary paper, Corpus Linguistics 2001
Conference, Lancaster University, UK.
Weisser,
M.
(2001) A corpus-based methodology for comparing and evaluating different
accents. In: Rayson, P., Wilson, A., McEnery, T., Hardie, A. and Khoja,
S. (eds) Proceedings of the Corpus Linguistics 2001 Conference,
pp.607-613. UCREL: University Centre for computer corpus Research on Language,
Lancaster University, UK.
Roumiana
Blagoeva (Sofia University, Bulgaria)
Personal
reference and other cohesive relations in learner writing: a corpus-based
analysis.
As part of a
wider investigation of cohesion in learner writing this paper discusses some
aspects of personal reference in argumentative essays of non-native advanced
learners of English. The study is comparative, based on data drawn from three
electronic corpora of about 100,000 words each: a learner corpus of
argumentative essays written by Bulgarian university students of English
language and literature, compiled within the framework of the ICLE project for
collecting interlanguage data from advanced learners of English of different
mother tongue backgrounds; a native-speaker written corpus of authentic English
non-fiction texts, which are used as teaching materials with the contributors to
the learner corpus; and a relevant corpus of Bulgarian texts from a variety
of sources.
The work
reported on here is concerned with the occurrences of personal pronouns in the
learner written production and their function as reference items for the construction
of coherent texts. On the basis of comparisons with the target language and the
native language of the learners an attempt is made to offer explanations of the
learners’ preferences for certain discourse patterns.
The frequency
lists produced for all personal pronouns in the learner and native corpora
showed a striking overuse of all items in the learner production in English.
The greatest differences, however, were observed in the use of third person
singular personal pronouns in the nominative (subjective) case. The analysis
focuses on the different functions and uses of it where the ratio between its occurrences in the native and the
learner corpora is 1:2,5.
To explore the
reasons underlying this phenomenon similar searches were applied to the
Bulgarian corpus with the aim of revealing characteristic features of Bulgarian
personal pronouns and their possible influence on the acquisition of English by
Bulgarians. Here it seems pertinent to mention some similarities and
differences between the role of personals as cohesive devices in the TL and NL
of the learners. As far as textual relations are concerned, pro-forms in both
English and Bulgarian behave in a similar way. Being items void of conceptual
meaning they function in the surface text as elements indicating that
information about their meaning is to be retrieved from elsewhere: either from
the situation of the communication act thus relating exophorically to entities
in the world outside the text, or from the text itself when they refer
endophorically to preceding or following items expressing anaphoric or
cataphoric reference respectively. Two major dissimilarities, however, exist
between the systems of personals in English and Bulgarian, which are most
prominent in the third person singular. They arise from the different
expression of the category of gender and the opposition animate/inanimate in
the two languages, and from the inflectional character of Bulgarian which
allows the omission of pronouns. While in English a non-personal inanimate item
denoting an object or a thing is referred to most often with the pronoun it, the choice of a pronoun in Bulgarian
for the same inanimate entity will depend on the gender of the noun it
co-refers with. Therefore, the equivalents of the English it could be той
[toj] (masculine, animate/inanimate), тя
[tja] (feminine, animate/inanimate), and то [to] (neuter, animate/inanimate).
Furthermore,
all Bulgarian nouns and verbs are marked for gender and number through special
suffixes and it is quite natural for speakers of Bulgarian to avoid repetitions
of pronouns whenever possible. The explicit mention of personal pronouns in the
nominative is obligatory only if we need to disambiguate certain contexts or to
express emphasis.
In all
other cases it is a matter of personal choice on the part of the speaker to use
or not to use pronouns in the surface text. Such omissions are treated by most
authors not as ellipsis but as implicit/explicit expression of the pronoun.
Each of the
types of referential ties mentioned above is examined separately in terms of
quantity and quality and sample sentences from the three corpora are discussed.
The differences between Bulgarian and English personals are taken into
consideration and it is compared with
its three equivalents only when they express relations similar to those of it. The processing of the data at this
stage is done semi-automatically. The cases of implicit expression of third
person pronouns are not included in the investigation, first, because samples
cannot be retrieved automatically from the corpus, and more importantly,
because they cannot indicate L-1 induced overuse of these items. On the
contrary, the lack of formally expressed pronouns in Bulgarian would suggest
underuse of these items by Bulgarian learners of English.
It is quite
obvious, then, that the overuse of personals by learners of English is hardly
due to NL interference. The idea that there exist culture-specific patterns of
writing would also be of little value in providing a plausible explanation of
the differences between learner and native writing. At this stage of the
investigation into cohesion in learner writing one of the possible causes could
be sought in a communication strategy common to many advanced second language
learners, namely that at a certain point of FLA they feel confident enough to
communicate in the foreign language and “stop learning” in the sense that they
tend to stick to some language patterns fossilized at an earlier stage of
learning. Further corpus-based research in this area is likely to enhance our
understanding of intuitive judgements about learner production and point to
effective ways of developing interlanguages.
Mia Bostrom
Aronsson (Göteborg University, Sweden)
On
clefts and information structure in Swedish EFL writing
Learner writing
is known to differ from native speaker writing in several ways, for instance in
terms of frequency of certain words or structures. One type of construction
that is frequently overrepresented in Swedish advanced learners’ written
English is different types of cleft constructions. These are a type of focusing
device used to manipulate the thematic structure and the information structure
of a text. The overrepresentation of these constructions in Swedish advanced
learner writing is probably caused by several different factors. This paper
discusses some ways in which Swedish advanced learners’ use of it-clefts and pseudo-clefts, as in (1)
and (2), differs from native speaker use, some possible underlying causes of
the differences, and what effect the learners’ use of these constructions may
have on their texts.
(1) It was Tom who offered Sue a
sherry (Collins 1991:3)
(2) What Tom did was offer Sue a
sherry (Collins ibid)
It-clefts and
pseudo-clefts are flexible constructions that can be used to rearrange the
order of the sentence elements to make an element focal and/or thematic, which
would not be so in a regular declarative sentence. This is particularly useful
in writing, where prosody is not marked (Quirk et al. 1985: 1384). As can be
seen in example (1), for instance, the cleft construction places additional
focus on the subject Tom, which would
not be in focus in a regular declarative sentence (Tom offered Sue a sherry Collins 1991: 4). Example (3), which is an
authentic example from a native speaker text, illustrates how the use of an it-cleft can contribute to the
organization of the text in a paragraph in that the it-cleft makes it possible to focus on the subject these people…, which forms a cohesive
link to the previous sentence by means of the anaphoric reference to fight promoters and fighter managers, at
the same time as the focused noun phrase is placed early in the sentence.
(3) Naturally, there is the argument for keeping boxing. As I said
before, it has
developed into an extremely lucrative sport with
millions of pounds being offered for the elite to fight. The fight promoters
and fighter managers will all be receiving large sums of money. It is these people who are directly involved
with the sport who would defend it greatly. (LOCNESS-A-level-Boxing-B10,
italics added)
In addition to
the text organizing function of clefts, these constructions are also associated
with an exclusiveness implicature and an existential presupposition, which
entail that in an example such as (3), the cleft construction expresses
exclusively who would defend the sport and that it is a fact that someone would
defend it (see further Collins 1991: 69ff;
Huddleston 1984: 465ff; Johansson
1996: 129ff).
This study
compares the use of cleft constructions in argumentative essays written by
native Swedish students in their second year of university studies of English
with the use of these constructions in argumentative essays produced by native
speakers of English. The learner writing consists of material from the Swedish
component of the International Corpus of Learner English (ICLE), whereas the
native speaker material is taken from the LOCNESS corpus (Louvain Corpus of
Native English Essays). The study looks into how the learners’ use of cleft
constructions differs from native speakers’ use as regards the form of the
constructions and the function of the examples in their context. The analyses
of the form of the pseudo-clefts and of which elements are placed in focus of
pseudo-clefts indicate, among other things, that the differences between the
learner examples and the native speaker examples may reflect differences as
regards the argumentative styles of learners and native speakers and that these
differences may contribute to the high frequency of cleft constructions in
Swedish advanced learner writing.
A study of the
learner and native speaker examples in their context indicates that the learner
examples often appear unmotivated in their context, whereas this is not common
in native speaker writing. For instance, the learner examples often emphasize
elements that do not need to be emphasized, judging from the context. The
unmotivated use of cleft constructions may give an implication of exclusiveness
which is not relevant in the context. This may have a negative effect on the
coherence of the text. Moreover, the learner examples also place elements as
marked themes even though there is no need for the particular element to be thematic.
Rather, the fact that it is made thematic may have a negative effect on the
thematic development of the text. Thus the study of cleft constructions in
their context in Swedish advanced learner writing and native speaker writing
indicates that the learners’ use of cleft constructions reflects the fact that
Swedish advanced learners have problems with the distribution of information in
their texts.
References
Collins,
P. C. (1991) Cleft and Pseudo-Cleft
Constructions in English. Routledge, London.
Huddleston, R. (1984) Introduction to the Grammar of English. Cambridge University Press,
Cambridge.
Johansson, M. (1996) Contrastive data as
a resource in the study of English clefts. In Aijmer, K., Altenberg, B., and
Johansson, M. (eds). 1996. Languages in
Contrast: Papers from a Symposium on Text-based Cross-linguistic Studies. Lund
4-5 March 1994. Lund University Press, Lund, pp. 127-150.
Quirk,
R., Sidney G., Geoffrey L., and Svartvik, J. (1985) A Comprehensive Grammar of the English Language. Longman, Harlow.
Nicholas Brownlees (University of Florence, Italy)
Extending the ZEN Corpus (1641-1650): A
Progress Report
The ZENcomp
corpus is an addition to the full ZEN (Zurich English Newspapers) corpus. Whereas
the latter covers the period 1661-1800, ZENcomp incorporates the first four
decades of English newspaper publication. These years (1620-1660) saw English
newsbooks, as periodical news publications were then called, develop from
rough, badly translated newssheets to quite subtle, well-informed news texts.
The first decade to be included in the ZENcomp corpus is that of the Civil War
years (1641-1650). Like its parent corpus, ZENComp includes about 140,000 words
of newspaper text for each of the four decades (1620-1660) under review. Such a
figure is relatively ample for much of the seventeenth century, where newspaper
publication is generally quite uniform and frequently based around one central
publication (such as the London Gazzette for the period 1665-1688) but
decidedly more restrictive when measured against the plethora of highly diverse
publications of the Civil War period.
The years in
question were as unique in seventeenth century newspaper history as they were
in English politics and society. Periodical news publications had begun in
England in 1620, but it was only in 1641, with the breakdown of royal
authority, that they began to report domestic matters. Furthermore, as
centralised political power waned, and political and religious controversy
deepened, the number of publishers tempted to enter the world of newsbook
publication increased. In no other decade of the seventeenth century is the
English press so free, politically relevant, numerically significant and
stylistically heterogenous. As can be imagined, for the corpus creator such a
situation is both highly stimulating and very problematic. Out of the hundreds
of separate publications available which ones should be selected for the corpus
and why1?
Hard choices
need to be made and selection necessarily depends on thematic and linguistic
objectives. The first question is whether to include only a part or all of
separate newspaper publications. As Civil War newsbooks were generally between
8 to 12 quarto pages long, it was decided that the advantages of having
complete newspapers in the corpus overrode a decrease in thematic and stylistic
representation. The 1641-1650 period will only include about 45 different
newspaper publications but at least these will be complete texts with all the
consequential advantages for macro- as well as microlinguistic analyses.
The next
important question concerns the kind of newspapers selected for inclusion.
Civil War newspapers range from one political extreme to another, one register
to another, and while some titles survived a number of years others died a few
days after birth. How inclusive should a Civil War corpus attempt to be?
Furthermore, apart from the nature of the publication, how much importance, if
any, should be given to the date of publication? The decade in question was
momentous, but some dates particularly stand out - for example, the Battle of
Naseby in 1645 and the execution of Charles I in 1649. Decisions have to be
made as to whether such dates should be highlighted, avoided, or regarded as
inconsequential. In the progress report I shall expand on these sampling issues
and indicate some of the principal linguistic characteristics a corpus of
ZENcomp's dimensions can highlight.
Claudia Claridge (University
of Greifswald, Germany)
What are Prepositional Verbs?
The
English language features some verbal constructions, which can variously be
treated as multi-word lexical units or as syntactic sequences with a more or
less loose connection between the individual elements. Among them are
verb-preposition sequences, some of which have been classified as prepositional
verbs, i.e. lexemes in their own right (e.g. Quirk et al. 1985, Vestergaard
1977, Diensberg 1990). However, neither the precise extent of membership in
this class nor even its very existence (e.g. Huddleston 1984, Götz/Herbst 1989)
has remained undisputed.
This paper looks
at verb-preposition sequences in the BNC Sampler in order to establish
both the outer limits of a class 'prepositional verbs' as well as its possible
internal sub-divisions. As verb-preposition sequences are extremely frequent,
the following somewhat restricted search procedures have been used: (i) base
form of verb (VV0), third person verb (VVZ) and past tense form of verb (VVD)
followed by general preposition (II), either immediately, and with one/two
words intervening, (ii) past participle (VVN) followed immediately by general
preposition as well as (iii) general preposition followed by whom, who,
whose, which and what. This approach is intended to yield, apart
from straightforward verb-preposition sequences, instances of prepositional
passives/preposition stranding, pied-piping and inserted adverbials, all of
which features have played a role in the discussion of this construction so
far.
The search
results were then weeded out according to the following principles. If the
preposition is to be more closely connected to the verb, which is a
precondition for prepositional verb status, the noun following it must be an
independent role-playing participant in the clause. Thus all cases where the
preposition introduces a phrase functioning as a circumstantial element of
extent and location in time and space, manner (means, quality and comparison),
cause, contingency, accompaniment, role and angle (cf. Halliday 1994: 151) were
excluded. Furthermore, instances of phrasal-prepositional verbs (e.g. look
forward to), verb-noun combinations (e.g. give way to, fall in
love), and cases where a direct object was present or possible (as
intervening word, e.g. turn N into N) were also discarded. Cases
of preposition stranding, on the other hand, were always retained regardless of
their behaviour regarding the criteria just mentioned.
The remaining
examples are then examined with regard to the following aspects:
- the exact nature of the noun
following the verb-preposition sequence. The fact that the noun is a
role-playing participant need not necessarily imply that the verb and
preposition indeed form a close unit. Verbs which can optionally omit their
direct object (e.g. write to N) are of interest in this respect, for
example.
- collocational fixity, i.e. the (lack
of) commutability of the verb and especially the preposition making up the
sequence. Here, verbs with variable prepositional usage (e.g. consist of/in), and verbs occurring with
or without the preposition (e.g. decide/decide on) will have to be looked at more closely. The stronger
the collocational bond, the more likely the existence of a prepositional verb.
- syntactic tests which can be helpful in
establishing either an SVA- or an SVO-analysis for sentences with
verb-preposition sequences, such as look
into a problem, live on little money, and sleep in a bed. Among them are the possibility of the
passive-transformation, the extent of preposition stranding or of pied-piping,
and the insertion of adverbials between verb and preposition. None of them have
been regarded as conclusive so far. However, the occurrence of these syntactic
features may show up some valid tendencies.
- semantic opacity/non-compositionality,
in particular whether this should be taken as a criterion at all. Here, the
semantic content of the preposition and its concrete vs. abstract use (cf. arrive at the station/arrive at a conclusion)
will play a role. Many potential prepositional verbs seem to be (fairly)
'literal' (e.g. insist on, believe in), while the more opaque ones (e.g.
set about, come by) have even been classified as phrasal verbs by some
researchers (e.g. Dixon 1992) – an approach that ignores the syntactic
differences between these two verb types.
- the type of verbs occurring in
prepositional verbs. It might be relevant whether the verb is of Romance or
Germanic origin and how integrated it is into the core of the lexicon.
Combinations such as look into, come by, call on have a different
flavour from, e.g. rely on, relate to and insist on, with the
former being more versatile and semantically more akin to phrasal verbs.
- the use of preposition as a pure
affix/casemarker, as in look at a picture, or as a meaning-modifying
element, e.g. play at politics, know
about something. While the preposition as part of a prepositional verb has
been seen to have very little or no meaning of its own independent of the verb
and stand in no opposition to other prepositions, in the latter use the
preposition does make a semantic contribution. It modifies the nature of the
action denoted by the verb, not the meaning or status of the following noun.
This paper will
argue that, while the criteria can be conflicting in cases, it is nevertheless
possible to distinguish a class of prepositional verbs, with the status of the
following noun, the nature/indispensability of the preposition and the
collocational bond probably being the primary criteria. Furthermore, three
types of prepositional verbs are proposed, namely (i) verbs which need the
prepositional affix to introduce their object and where the preposition is
semantically unimportant (e.g. rely on), (ii) verbs which enter into a
close semantic relationship with the preposition, producing an idiomatic and/or
opaque combination (e.g. look into) and (iii) verbs which in some uses
add a preposition which produces a semantic modification (e.g. play at)
(cf. also Goyvaerts 1973, for whom only (ii) are clearly prepositional verbs).
References
Diensberg,
B.
(1990) A syntactic analysis of English prepositional verbs, Tromsø Studies in Linguistics 11:
Tromsø Linguistics in the Eighties: 85-109.
Dixon,
R. M. W. (1992) A New Approach to English
Grammar, on Semantic Principles. Clarendon Press, Oxford.
Götz,
D.
and Thomas, H. (1989) Language description and language teaching: The
London School and its latest grammar, Die
Neueren Sprachen 88: 220-235.
Goyvaerts,
D. L. (1973) Some observations about the verb+particle construction in
English, Revue de Langues Vivantes: 549-562.
Halliday,
M.A.K. (1994) An Introduction to Functional Grammar. 2nd
ed. Arnold, London.
Huddleston,
R.
(1984) Introduction to the Grammar of
English. Cambridge University Press, Cambridge.
Quirk,
R., Greenbaum, S., Leech, G. and Svartvik, J. (1985) A Comprehensive Grammar of the English Language. Longman, London.
Vestergaard,
T.
(1977) Prepositional Phrases and
Prepositional Verbs. A Study in Grammatical Function. Mouton, The
Hague/Paris.
Sylvie De Cock (Université catholique de Louvain,
Belgium)
Recurrence and phraseology in learner and native corpora of speech and
writing
In his well-known 1991 article, Kjellmer puts forward the
hypothesis that learners of English, unlike native speakers, tend to construct
utterances from individual words, rather than sequences of words, that their
‘building material is individual bricks rather than prefabricated sections’.
However, findings from a corpus-driven study of ‘repetitive phrasal chunkiness’
(Lancashire 1996) in native and learner speech and writing (De Cock 2000) seems
to contradict this hypothesis, revealing that the learners used more continuous
recurrent n-grams (i.e. sequences of n orthographic words) than
comparable native speakers, both in speech and more especially in writing.
The aim of the present study is to provide a
qualitative follow-up to this quantitative study of continuous recurrent
n-grams through an analysis of fully comparable corpora of native speaker and
learner informal interviews and native speaker and learner non-professional
argumentative essay writing. I set out to investigate the nature of recurrence
in these specific genres and to determine the extent to which native speakers
and learners use similar recurrent sequences.
As is clear from the lists of automatically
extracted recurrent n-grams, not every frequently recurring sequence can be
considered as a well-established phraseological expression. Sequences such as there’s a, in the, the the the, but er and I don’t know if are all high frequency sequences without being
‘phraseological expressions’ as such. As Moon (1998) points out, recurrence
does not automatically indicate phraseological status. In other words, there
are different types of recurring sequences.
A model
for the description of the various kinds of continuous n-grams in the corpora
is put forward and the proportion of these different kinds of sequences is
assessed for each combination length (both in terms of types and tokens) to
find out whether and to what extent the same types of recurrent n-grams are
used in the spoken and written genres under investigation and in the native and
learner varieties. Particular attention is paid to the question of whether
learners’ overuse of recurrent n-grams in speech and especially in writing
noted in De Cock (2000) can be attributed to an overuse of one or more specific
(sub)categories.
Among the major types of recurrent sequences
that can be distinguished, there are, at one level, phraseological multi-word
lexical units, which can be seen to display varying degrees of
non-compositionality, restricted collocability and restricted flexibility. They
are often presented as typically native-like (Pawley and Syder 1985, Granger
1998) and as particularly common in speech (Aijmer 1996, Altenberg and Olofsson
1990). They include, for example, the complex preposition because of, the complex connectors of course and on the other
hand or the comment clauses I mean
and you know. I will attempt to
discover whether these recurrent phraseological expressions make up a larger
proportion of the recurrent strings in the native than in the learner corpora
and if so, if this tendency is more significant in the spoken than in the
written corpus.
Beside these multi-word lexical units, there
is a series of structurally complete multi-word sequences (phrases and
clauses), the majority of which are not strictly phraseological but which, just
like phraseological multi-word lexical units, can nevertheless be labelled as
‘preferred building blocks’ (Altenberg 1998). They can be seen to reflect what
Béjoint (2000) calls ‘tendencies in the encoding of text’, tendencies which he
regards as part of the ‘mastery of language’. Strings like I don’t think so, most of the
time or away from home are
arguably also part of the idiomaticity of English taken in the wide sense, i.e.
in the sense of Pawley and Syder’s (1983) ‘native-like selection’ or of
Sinclair’s (1991) ‘idiom principle’.
At another level, there are structurally incomplete
sequences or ‘phrase or clause fragments’ such as of the, because of the, one of the, but I, there is a, the high
frequency of most of which is largely due to the very high frequency of the
words which compose them. Some of these sequences can be described using
terminology/categories from Altenberg’s (1998) investigation of recurrent word
combinations in the London-Lund Corpus of Spoken English (cf. ‘multiple clause
constituents’ and more especially ‘frames’, ‘onsets’ and ‘stems’).
At yet another level, there are what we could
call ‘speech-specific n-grams’, i.e. n-grams that contain what have been
referred to as performance errors. ‘Speech-specific n-grams’ contain
reduplication (the the, I I I) and/or hesitation items such as er or erm (and er, er the the).
Although it may be tempting to dismiss phrase or clause fragments and speech
specific n-grams as not worthy of study, a preliminary analysis reveals that it
is important to include them in our description as they are part and parcel of
the phenomenon of recurrence. The study reveals, among others, that learners’
overuse of recurrent n-grams in speech (De Cock 2000) is in fact largely due to
an overuse of speech specific n-grams.
The question arises as to whether the apparent
contradiction between Kjellmer’s statement and the overuse of recurrent
sequences noted in De Cock (2000) still holds when speech-specific n-grams and
some types of phrase/clause fragments are discarded.
References
Altenberg, B. (1998) On the Phraseology of spoken English:
the evidence of recurrent word combinations. In Cowie, A.P. (ed.) Phraseology: theory, analysis and
applications. Oxford University Press, Oxford, pp. 101-122.
Altenberg, B. and Eeg-Olofsson,
M. (1990) Phraseology in Spoken English: Presentation
of a Project. In Aarts, J. and Meijs, W. (eds) Theory and Practice in Corpus Linguistics. Rodopi,
Amsterdam/Atlanta, pp. 1-26.
Béjoint,
H. (2000) Modern
Lexicography: An Introduction. Oxford University Press, Oxford.
De Cock, S. (2000) Repetitive phrasal chunkiness and advanced EFL speech and
writing. In Mair, C. and Hundt, M. (eds) Corpus
Linguistics and Linguistic Theory. Papers from the Twentieth International
Conference on English Language Research on Computerized Corpora (ICAME 20)
Freiburg im Breisgau 1999. Rodopi, Amsterdam and Atlanta, pp. 53-68.
Granger, S. (1998) Prefabricated patterns in advanced EFL writing: Collocations and
formulae. In Cowie, A. P. (ed.) Phraseology:
theory, analysis and applications. Oxford University Press, Oxford.
Kjellmer, G. (1991) A mint of phrases. In Aijmer, K. and Altenberg, B. (eds) English Corpus Linguistics. Longman,
London/New York, pp. 111-127.
Lancashire, I. (1996) Phrasal Repetends in Literary Stylistics: Shakespeare’s Hamlet
III.1. In: Hockey, S. and Ide, N. (eds) Research
in Humanities Computing 4. Selected Papers from the ALLC/ACH Conference, Christ
Church, Oxford, April 1992. Calderon Press, Oxford, pp. 34-68.
Moon, R. (1998) Fixed Expressions and Idioms in English.
Clarendon Press, Oxford.
Pawley, A. and Syder, F. (1983) Two puzzles for linguistic theory: nativelike selection and
nativelike fluency. In: Richards, J. and Schmidt, R. (eds) Language and
Communication. Longman, London, pp. 191-226.
Sinclair,
J. (1991) Corpus, Concordance, Collocation. Oxford University Press, Oxford.
Roberta Facchinetti (University of Verona,
Italy)
The
modal verb MAY in contemporary British English: a study of the ICE-GB corpus
0.
0. Introduction
Over the past few decades, scholars have written extensively on
English modality and on modal verbs in particular. A quick overview of only a
few studies carried out and/or published in the year 2000 shows how research
has thrived particularly in the field of Present-day English modal verbs
(Facchinetti 2000, Leech forthcoming, Palmer forthcoming, Papafragou 2000a,
2000b, Winford 2000) and of their historical development (Krug 2000, Vihla
2000, Myhill forthcoming) MAY is among the most targeted modals, due to the
dramatic semantic changes it has undergone through the centuries, but also to
the values and functions it conveys in Present-day English.
Faithful to this long-lasting research tradition, and in the hope of
contributing to enlightening some still shaded tessellas in the mosaic of MAY,
I will also carry out a corpus-based study of this modal, with the aim of
charting its distribution and semantic/pragmatic values in British English.
To do so, I will analyse the British
Component of the International Corpus
of English (ICE-GB), which
contains a total of 1 million running words distributed among a wide range of
textual types (Greenbaum 1996).
1.
1. Quantitative distribution
A total of 1219 instances of MAY have been recorded in the corpus
under scrutiny. Their distribution widely confirms the generally acknowledged
view the MAY is employed with much higher frequency in the written medium than
in the spoken medium (frequency per ten thousand words: 6,5 in speech vs. 19 in
writing). The formality constraints and the semantic/pragmatic values of the
modal strongly affect its distribution among the textual categories represented
in the corpus, the most blatant discrepancies being the following[1][1]:
·
· within public dialogue: 'broadcast interviews' (4,1) vs.
'parliamentary debates' (12,3) and
'legal-cross examinations' (13,2);
·
· within monologue: 'spontaneous commentaries' (3,3) vs. 'legal
presentations' (13,8);
·
· within non-professional writing: 'untimed student essays' (15) vs.
'student examination scripts' (22,6);
·
· within correspondence: 'social letters' (8,7) vs. 'business letters'
(16,1);
·
· within printed texts: 'instructional writing' (38,5) vs. 'news
reports (12,8).
Other sociolinguistic variables, pertaining to the age, the gender,
and the level of education of the speaker/writer, have been taken into
consideration in the present analysis, but only the level of education has
yielded statistically relevant results with reference to the distribution of MAY,
since speakers/writers with a university level of education appear to use MAY
more frequently than people who have a secondary school level of education.
2.
2. Semantic and pragmatic values
Unsurprisingly, MAY is mostly associated with epistemic modality,
but deontic and dynamic values have also been recorded, though to a much more
limited extent, as shown in Figure 1:
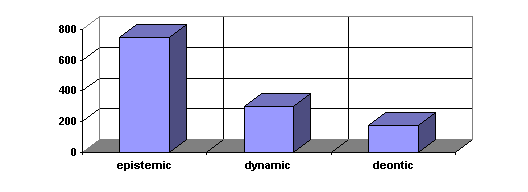
Figure 1: semantic values
of MAY in ICE-GB
2.1. Epistemic modality:
possibility
A total of 746 occurrences (61%) express 'epistemic possibility' and
are particularly frequent in the following textual types:
·
· private conversations
·
· business transactions
·
· spontaneous commentaries
·
· broadcast news/talks/discussions
·
· social letters
·
· academic writings - humanities
·
· non-academic writings - humanities, social sciences
·
· press news reports/editorials
The large majority of these instances are positive, as in (1), while the 59 negative[2][2] instances all exhibit main verb negation,
as in (2):
(1)
(1) _S1B_064_106> It is possible that they may have seen my advertisement as well
(2)
(2) _S1A_069_271> Uhm so I think he may not
have the confidence to go ahead as it were
2.2. Dynamic modality:
possibility
In the corpus under scrutiny, 'dynamic modality' is expressed in 300
cases (25% of the total), which are particularly concentrated in formal,
technical, scientific contexts, such as the following:
·
· academic writing - natural sciences
·
· non-academic writing - natural sciences
·
· non-academic writing - technology
Unlike instances of epistemic possibility, where the speaker/writer puts
forward his/her point of view quite overtly, in the occurrences of dynamic
possibility, the speaker/writer is merely relating a state of fact, made
possible/impossible by external circumstances, as in (3):
(3)
(3) _W2D_014_18> The dimensions of the antenna are
directly related to the wavelength of the signal you intend to receive and the
elements of the antenna are set at right-angles to the transmitter, and may
be aligned vertically or, more commonly, horizontally, to match the polarity of
the transmitted signal.
Only 7 occurrences of MAY NOT conveying dynamic possibility have
been recorded in the corpus, 6 of which exhibit main verb negation, as in (4),
while only 1 is an instance of modal verb negation, namely (5):
(4)
(4) _S2A_058_139> And this collagen may or may not
have fibroblasts in it
(5) (5) _W2A_012_39>
This is not to say that large, well-organized, and long-established long
established religions may not be monolithic - history clearly shows us
that they can be, but it is to suggest that the more established a religion is
in a pluralistic society, the more 'internal pluralism' it is likely to
display.
2.3. Deontic modality
The 173 instances of deontic modality (14% of the total) occur most
often in 'parliamentary debates', 'legal cross-examinations', 'business
letters', and 'administrative/regulatory writing'. Four different speech acts
are encoded in these deontic values: 'regulation', 'request', 'permission', and
'wish':
·
· regulation:
(6) (6) _W2D_006_79>
NO BOOK OR OTHER PROPERTY OF THE BRITISH LIBRARY AND NO MATERIAL TEMPORARILY IN
THE CARE OF THE BRITISH LIBRARY MAY BE REMOVED FROM THE ROOM IN WHICH IT
WAS ISSUED.
·
· request:
(7)
(7) _S1B_053_2> May I ask her whether she
thinks, that the eleven are not now both isolated and intransigent in relation
to, agricultural policy
·
·
permission:
(8)
(8) _S1B_062_2> If you wish to be seated you may
with My Lord 's permission
·
· wish:
(9) (9) _S2B_041_51>
My lords and members of the House of Commons I pray that the blessing of
Almighty God may rest upon your counsels
3. Conclusion
The present
paper has focussed on the modal verb MAY as it occurs in the British Component of the International
Corpus of English. However, an exhaustive picture of this verb can only be
drawn if we do not lose sight of the wider canvas of the whole modal system,
which will involve studying other verbal and non-verbal realizations of the
same semantic and pragmatic values that have been discussed for MAY. Moreover,
a consistent study of any modal verb is bound to tackle also the knotty issue
of the different types of modality, since the epistemic and deontic categories
cover only part of the semantic realm, while a third type of modality,
generally labelled with the term 'dynamic', is needed to qualify the linguistic
realizations of a number of modal elements. Hence, rather than being intended
as a self-contained study, the present analysis should also be considered as a
means to further qualify the field and the boundaries of the types of modality,
including dynamic modality itself, which has often been excluded from the
semantic realm pertaining to MAY.
References
Aarts, B. and Meyer,
C.F. (eds.) (1995) The Verb in
Contemporary English. Cambridge University Press, Cambridge.
Aijmer, K. (1997)
Epistemic Modality as a Discourse Phenomenon - a Swedish-English Cross-Language
Perspective. In Fries, U., Müller, V. and Schneider, P. (eds.),
pp.215-226.
Biber, D.,
Johansson, S., Leech, G., Conrad, S. and Finegan, E.
(1999) Longman Grammar of Spoken and
Written English. Longman, London.
Bybee, J. and Fleischmann,
S. (eds.) (1994) Modality in Grammar
and Discourse. Benjamins, Amsterdam.
Coates, J. (1995) The
Expression of Root and Epistemic Possibility in English. In Aarts, B. and
Meyer, C. F. (eds.), pp.145-156.
Facchinetti, R. (2000) Be able to in Present-day British English. In Mair, C. and Hundt,
M. (eds.), pp. 117-130.
Fries, U., Müller, V. and Schneider, P.
(eds.) (1997) From Ãelfric
to the New York Times. Studies in English Corpus Linguistics. Rodopi, Amsterdam.
Greenbaum, S. (ed.) (1996) Comparing
English Worldwide: The International Corpus of English. Clarendon Press,
Oxford.
Groefsema, M. (1995) Can, May,
Must and Should: A Relevance Theoretic Account, Journal of Linguistics 31: 53-79.
Kirk, J. (ed.) (2000) Corpora
Galore. Analyses and Techniques in Describing English. Papers from the 19th
International Conference on English Language Research on Computerised Corpora
(ICAME1998). Rodopi, Amsterdam.
Klinge, A. (1993) The
English Modal Auxiliaries: From Lexical Semantics to Utterance Interpretation, Journal of Linguistics 29:
315-357.
Krug, M. (2000) Emerging English Modals: A Corpus-Based
Study of Grammaticalization. [Topics in English Linguistics]. Mouton de
Gruyter, Berlin.
Leech, G. (forthcoming) Diachronic
Linguistics across a Generation Gap: From the 1960s to the 1990s. Paper
presented at Grammar and Lexis,
University College London, 21st July 2000.
Lichtenberk, F. (1994) Apprehensional
Epistemics In Bybee, J. and Fleischmann, S. (eds.), pp. 293-327.
Mair, C. and Marianne,
H. (eds.) (2000) Corpus Linguistics and Linguistic Theory. Papers
from the Twentieth International Conference on English Language Research on
Computerized Corpora (ICAME 20) Freiburg im Breisgau 1999. Rodopi, Amsterdam.
Myhill, J. (forthcoming)
Themes in the Historical Development of American English Modals: From Social to
Individual to Impersonal. Paper presented at 11th International Conference on English Historical
Linguistics, Santiago de Compostela, 7-11 September 2000.
Palmer, F. R. (1990) Modality and the English Modals. (2nd
ed.) Longman, London.
Palmer, F. R. (1994) Negation
and the Modals of Possibility and Necessity. In Bybee, J. and Fleischmann, S.
(eds.), pp. 453-471.
Palmer, F. R. (forthcoming) Negation and
the Modal Verbs in English. Paper presented at Grammar and Lexis, University College London, 21st July
2000.
Papafragou, A. (2000a) Modality: Issues in the Semantics-Pragmatics
Interface. Elsevier, Amsterdam.
Papafragou, A. (2000b) On
Speech-Act Modality, Journal of
Pragmatics 32: 519-538.
Vihla, M. (2000) Epistemic
Possibility: A Study Based on a Medical Corpus. In
Kirk, J. (ed.), pp.209-224.
Winford, D. (2000) Irrealis
in Sranan: Mood and Modality in a Radical Creole, Journal of Pidgin and Creole Languages 15(1): 63-126.
Gaëtanelle Gilquin (Université catholique de Louvain, Belgium)
Causative
‘cause’, ‘get’, ‘have’ and ‘make’: A preliminary study
Although there is
a plethora of studies from various linguistic trends devoted to causative
constructions (e.g. Shibatani 1975, 1976, Ritter & Rosen 1993, Song 1996),
there is scope for further research in the field. This study has two
distinctive features. First, it does not deal with ‘the causative construction’
in general, but exclusively focuses on four causative verbs, viz. cause, get, have and make, the most frequent periphrastic
causatives with no or little semantic content on their own, apart from the
causative meaning of ‘bringing about’ (unlike for instance force, which, besides causation, also clearly expresses coercion).
Although these verbs are dealt with in most grammars, no satisfactory account
is given of the circumstances in which each of them should be used, nor the
consequences of the use of a particular type of complement (infinitive, past
participle or present participle). Second the study is based on corpus data, so
that it should give a better idea of how causative verbs behave in authentic
present-day English (precise meaning, frequency, diatypic variation,
combinatorial properties, etc.).
This presentation will fall into two parts. First, I
will show how causative constructions such as John made her laugh or I had my
watch repaired can be retrieved from corpora (semi-) automatically. More
specifically, I will compare the results achieved with a concordancer like XKwic,
a piece of software developed at the University of Stuttgart which can carry
out highly refined and specialised linguistic searches, and with ICECUP 3.0,
the program designed to query the International Corpus of English (ICE) and
working on the basis of ‘Fuzzy Tree Fragments’ representing the grammatical
structure of sentences. This comparison will highlight the fact that, although ICECUP
has higher precision and recall rates, as long as it cannot be used in
conjunction with other (larger) corpora, a more ‘classical’ concordancer will
be needed to thoroughly investigate relatively rare phenomena such as
periphrastic causative constructions.
Secondly, I will
present the preliminary results reached on the basis of ICE-GB (1,000,000-word
corpus), the British component of ICE. Following the functional ‘one meaning,
one form’ principle, I put forward the hypothesis that there must be differences
between the four causative verbs cause,
get, have and make. In order to
test this hypothesis, the causative sentences retrieved were examined both
quantitatively and qualitatively with respect to a number of syntactic,
stylistic and semantic parameters. The syntactic survey focused on the types of
structures that are available for each causative (bare infinitive or to-infinitive, present participle, main
clause or subclause passivization). From a stylistic point of view, I
investigated whether the four verbs and their non-finite complements were
stylistically differentiated by comparing their frequencies in speech and
writing, as well as in the different genres of ICE (e.g. novels/stories,
business letters, face-to-face conversations, etc.). Semantically speaking,
finally, I followed Fillmore and his theory of Frame Semantics (cf. the
FrameNet Project) in viewing causative constructions as made up of three ‘Frame
Elements’, viz.
The
explosion caused the
temperature to rise.
Cause Affected Effect
Each Frame
Element can be described in terms of various features, such as animacy of the
Cause and the Affected, volitionality of the Effect, or degree of coercion
involved. The semantic study is complemented with a collocational analysis,
whose aim is to determine the preferential lexical company kept by each
causative verb. It should be emphasised, however, that these results are based
on a relatively small number of instances (40 constructions with cause, 101 with get, 77 with have and 150
with make) and therefore need to be
substantiated by further and more extended research.
Acknowledgement
I wish to acknowledge the
support of the Belgian National Fund for Scientific Research.
References
Fillmore,
C.J., The FrameNet Project, University of California at Berkeley (http://www.icsi.berkeley.edu/~framenet/)
Gilquin,
G. (1999)
Causative ‘make’: A corpus-based study. Unpublished M.A.
dissertation, Université catholique de Louvain.
Gilquin,
G.
(2000) Periphrastic causative verbs ‘get’ and ‘have’. Towards a systematic
description. Unpublished M.A. dissertation, Lancaster University.
ICECUP 3.0 (1999) Survey of English Usage,
London.
Ritter,
E. and Rosen, S.T. (1993) Deriving
Causation, Natural
Language and Linguistic Theory 11: 519-55.
Shibatani,
M. (1975) A Linguistic Study of Causative
Constructions. Ph.D.
Dissertation. Indiana University Linguistics Club, Bloomington.
Shibatani, M. (ed.) (1976) The Grammar of Causative
Constructions. Syntax & Semantics 6. Academic Press, New
York/San Francisco/London.
Song,
J.J. (1996) Causatives and Causation. A Universal-Typological
Perspective. Longman, London/New York.
Xkwic, IMS, Stuttgart (http://www.ims.uni-stuttgart.de/projekte/CorpusWorkbench)
Maurizio Gotti
(Universita di Bergamo, Italy)
SHALL and WILL as first
person future auxiliaries in a corpus of early modern English texts
This paper aims to
analyse the use of SHALL and WILL for the formation of the first person subject
future tense in a corpus of Early Modern English texts. The period taken into
consideration is 1640-1710 and the texts analysed are those included in the
third section of the Early Modern English part of The Helsinki Corpus of
English Texts.
The use of the future tense
formed with SHALL and WILL has been the object not only of various previous
analyses, but also of specific rules pointed out in several of the grammar
books published in the seventeenth century. As regards the former, one of the
first studies carried out on the subject is Fries (1925), whose investigation
is based on a survey of the usage of SHALL and WILL in fifty English dramas
from 1560 to1915 (two dramas of roughly the same date were selected for
approximately every decade in that period). In examining these texts, Fries
divided the instances into three groups: (1) WILL and SHALL in independent
declarative statements; (2) WILL and SHALL in questions; (3) WILL and SHALL in
subordinate clauses. As regards the first group, with first person subjects
WILL has been found to be more frequently used than SHALL (with average
percentages of respectively 80% vs 20% in the period taken into consideration
here). On the other hand, in direct questions SHALL overwhelmingly predominates
(97% vs 3%); even in the few instances in which WILL occurs in the first
person, the majority of cases consists of ‘echo-questions’, in which WILL
repeats the use of the same modal auxiliary in the previous sentence. As
regards subordinate clauses, the data are fairly well-balanced, with a slight
majority of shall-forms (53.4% vs 46.6%).
In her analysis of a corpus
of texts taken from a wider section of the Helsinki Corpus than ours, Merja Kytö
(1991) finds an initial increase in the use of WILL with first person subjects,
reaching a peak from the 1570s to the 1640s; this increase in the use of WILL
is particularly noticeable in colloquial language (e.g. private letters) and
speech-based texts (e.g. sermons and trial proceedings). Later the use of WILL
decreases, probably owing to the regulating influence of grammarians, who
started advocating SHALL in first person and WILL in second and third person
uses. As regards the period taken into consideration here, the use of the two
modal auxiliaries with first person subjects is quite well-balanced, with a
slight majority for SHALL (51.7% vs 48.3%); WILL, however, occurs more
frequently with dynamic uses of the main verb (in 71% of all cases), while
SHALL is the auxiliary favouring stative uses (in 66% of all cases). In direct
questions, instead, first person SHALL is dominant (100% of all cases).
The results of these studies
will be compared to the rules of usage pointed out in a few 17th-century
grammars, namely Wallis (1653), Cooper (1685), Miege (1688) and Aickin (1693).
The analysis of these grammars will help to outline the main uses of the two
auxiliaries in future contexts identified by early English grammarians, while a
careful analysis of the two previous studies will provide important points of
comparison with the data found in our research.
Our analysis
will focus on the uses of SHALL and WILL with first person subjects both in
interrogative and non-interrogative sentences, and will examine their
occurrences (both from a quantative and a qualitative point of view) in
different text types and for the performance of various pragmatic functions
(e.g. prediction, intention, promise, proposal).
The analysis of the
corpus will show that the rules laid down by the grammars of the period taken
into consideration oversimplify the range of uses of the two modal auxiliaries;
indeed, first person future expressions with SHALL do not merely denote
prediction or declaration, nor do those with WILL only express promise, intention or resolution.
SHALL is used in
interrogative sentences to express various pragmatic functions, such as asking
for the addressee's opinion, giving suggestions, requesting advice, and
inquiring about the addressee's wishes. In addition to these uses, questions
starting with shall-forms perform a
predictive function; occasionally they are used as rhetorical devices to serve
argumentative purposes. In non-interrogative sentences SHALL mainly indicates
prediction; indeed, for the expression of this pragmatic use this modal
auxiliary is employed in almost an exclusive way. Shall-forms are also used to express intention, representing an
alternative to the use of will-forms;
however, the quantitative difference between the two modals is relevant.
WILL is very
seldom used to express prediction in first person subject statements; as this
use has only been found in one text, its occurrence may be due to the author's
idiosyncratic behaviour rather than general usage. The most widespread
pragmatic function performed by first person subject will-forms is that of intention; for the expression of this
function WILL has a much higher percentage than SHALL. In particular, a
comparison in the use of the two modal auxiliaries in homogeneous contexts
points to the adoption of WILL where a more marked degree of intentionality is
to be denoted.
First person
subject will-forms are also used to
express promise; indeed, they represent the main form of expression of this
pragmatic function. Some occurrences of first person WILL statements represent
instances of proposals, a speech act which relies exclusively on this modal.
For the expression of this speech act SHALL is used in questions starting with Shall we, but no instances of shall-forms have been found in
non-interrogative sentences with this purpose.
References
Aickin, J. (1693) The English Grammar, London.
Cooper,
C.
(1685) Grammatica Linguae Anglicanae,
London.
Fries,
C. C. (1925) The Periphrastic Future with Shall and Will in Modern
English. In Publications of the Modern
Language Association of America, XL, pp. 963-1024.
Kytö,
M.
(1991) Variation and Diachrony, with
Early American English in Focus. Peter Lang, Frankfurt am
Main.
Miege, G. (1688) The English Grammar, London.
Wallis,
J.
(1653) Grammatica Linguae Anglicanae,
London.
Natalia Gvishiani &
Oksana Gerwe (Moscow State University, Russia)
1.1
Introduction. The problem of idiomaticity has been
traditionally perceived as one of the greatest challenges in the field of
linguistics and foreign language teaching, and is particularly true of
analytical languages like English which tends to 'isolate' its units not only
structurally but also semantically. In spite of a wide range of construction
types of idioms represented in the English language, the term 'idiom' has been
largely applied without distinction to pattern. It is mostly viewed as a semantic
matter manifested in much the same way in expressions of different structural
types. What makes a particular expression idiomatic is its semantic globality
which is difficult to interpret in terms of the meanings of its constituent
words. Idioms vary from opaque to relatively transparent, they are not divided
as a small water-tight category being related to non-idioms along a scale or
continuum (A.P. Cowie The Treatment of Collocations and Idioms in Learner's
Dictionary).
The view taken in
the present paper is that in text reality we are faced with the rich diversity
of established phrases which present both lexical and syntactic units. They
fall under the notion of phraseology
because "one is first struck by the fixity and regularity of phrases, then
by their flexibility and variability" (John Sinclair Corpus Concordance
Collocation, OUP, 1991, p.104). Some of such phrases or word-combinations
are characteristic not so much of the system of language (lexical units) but of
speech tendencies accounting for the 'naturalness', recurrence, and utility of
particular items (syntactic units).
The dichotomic
division of all word-combinations into 'free' and idiomatic is seldom
justified. This relationship is observable as a gradation in degree of
idiomaticity: every time we concern ourselves with the particular sequence of
words it is never a static assignment of this or that phrase to either part of
the above dichotomy but the dynamic unity of colligation and collocation.
Phraseology covers both idiomatic units proper and those which without being
truly global semantically still remain 'fixed', 'set' or recurrent reflecting
the typical lexical and syntactic choices. Hence the division into idiomatic and non-idiomatic phraseology.
1.2. The aim of the present paper is to try and approach the problem of
idiomaticity ('choice and arrangement of words') through a contrastive
corpus-based analysis of most typical phraseological choices made by Russian
learners of English as compared to those of native speakers.
To cope with the
large number and great diversity of word-combinations the following semantic
criteria (categories) have been elaborated:
·
· connotativeness -
non-connotativeness - accounting for the word-combinations performing the emotive
function as distinct from the referential one;
·
· cliché-ed expression - revealing the opposition
of set expressions and those created anew for the particular situation;
·
· idiomaticity - showing a chain-like
gradation in degree of 'opaqueness' from idioms to non-idioms;
·
· conceptual integrity - considering the
referential basis of word-combinations;
·
· cultural and
sociolinguistic determination - addressing the extralinguistic or
cognitive nature of linguistic items.
A contrastive
analysis of idiomatic phraseology used by native and non-native (Russian)
speakers of English was carried out on the basis of three components of the
International Corpus of Learner English (ICLE): British Component (95,695
words); American Component (153,348 words) and Russian Component (228,846
words).
In order to
investigate the peculiarities of various types of idiomatic expressions
realized in speech production we focus on the Adjective + Noun combinations
which present the classic example of the word combination and display the basic
properties of this kind of construction.
From the chosen corpora we have retrieved the following number of
word-combinations:
|
Component
of ICLE |
Total number of Adj + N
word-combinations |
|
British |
4170 |
|
American |
7381 |
|
Russian |
9204 |
2.1. A contrastive analysis of the Russian and the Native Speaker
(British and American) components of the International Corpus of Learner
English (ICLE) has yielded the following results:
1)
1)
High frequency Adj + N word-combinations
with the frequency band of 111 – 10, on the one hand, reflect thematic
peculiarities of the corpora which consist predominantly of student essays. On
the other hand, such expressions represent not only the subject matter of each
corpus but also the sociolinguistic features characteristic of a particular
speech community. Thus, the most frequent items in the American Component, for
example, are United States (111 occurrences); ethnic American (76);
American literature (63); public schools (57) and capital
punishment (50) while in the British Component the top five
word-combinations include: bad faith (54); prime minister (53);
single Europe (44); European community (35) and philosophical
optimism (31).
2)
2)
The data have shown a much stronger tendency on the
part of native speakers to use idiomatic (for example, at the same time,
a great deal, common sense) and cliché-ed expressions (such as natural
disasters, free trade, racial prejudice) as compared to the Russian
students of English:
|
Component
of ICLE |
Idiomatic
expressions (% of occurrences) |
Cliché-ed
expressions (% of
occurrences) |
British
|
15% |
68% |
|
American |
10% |
79% |
|
Russian |
7% |
52% |
3)
3)
British, American and Russian components of ICLE
include a certain amount of word-combinations which cannot be characterized either
as idiomatic or cliché-ed. The difference between the Native and Non-native
speaker corpora in this case lies in the semantic and functional peculiarities
of the word-combinations under consideration. In the British and American
components such expressions reflect occasional and/or context-bound
uses of words, such as overnight visitation, symbolic interactions,
exigent circumstances, etc. In the Russian Learner Corpus, however, these
are the word-combinations which in most cases, though conceptually integral and
understandable, are not found in common use and therefore can be described as collocational
errors or literal translation from the mother tongue. For example, good
purposes, broad education, material things, good sides, pure feelings, etc. The availability of these data reflecting
different tendencies of native and non-native speakers to use word-combinations
with various degrees of idiomaticity appears to be quite instrumental in the
area of English language teaching.
Sebastian Hoffmann
(University of Zurich, Switzerland)
Complex Prepositions Revisited: Definitions
and Corpus-Data
Complex
prepositions are traditionally considered to be fixed units that are
indivisible both in terms of syntax and in terms of meaning. Thus, they form
the head of a prepositional phrase (PP) and need not be analysed into smaller
constituents (e.g. PP -> P + NP + P (+ NP)). Typical examples are shown in
(1) and (2):
(1) They went swimming in
spite of the rain.
(2) In breach of the protocol, he left the
banquet early.
However, most
complex prepositions allow the insertion of further elements such as
premodifying adjectives or determiners (e.g. in hot pursuit of X). Quirk et al's "scale of cohesion"
(1985:671f.) takes account of this fact and lists nine possible types of
internal variability, with the prototypical preposition in spite of at the one extreme - allowing none of the variations -
and the syntactically much less restricted on
the shelf by at the other end of the scale (and allowing all 9 types of
variation). While this clearly offers a convincing descriptive approach to
complex prepositions, it does not address the question of how the concept of a
syntactically indivisible unit can be reconciled with clear indications of an
internal grammatical structure.
This point was
taken up by Seppänen et al. (1994), who applied four standard constituency
tests to the constructions in question: coordination, interpolation, fronting
and ellipsis. Consider examples (3) - (6):
(3) It will undoubtedly need further refinement and
modification in the light of
consultations and of experience. BNC:ANS:349
(4) In spite,
therefore, of the transformations, basic
comfort was lacking. BNC:ANR:478
(5) The debate centred around the issue of state control of education,
of which Williams was in favour , and in particular the
Aristotelian view on the issue. BNC:GXG:2158
(6) A:
In the light of what you've said, I
agree to the changes.
B:
Of what I've said! Don't put the onus
on me! Seppänen et al. (1994:
21)
Each of the
sentences in (3) to (6) suggests that there is in fact a constituent boundary
between the noun and the second preposition in complex prepositions. After
presenting a whole range of examples for both 2-word and 3-word complex
prepositions, Seppänen et al. conclude: "Introduced into the grammar on
the basis of an untenable analysis, the class of complex prepositions as
defined by Quirk et al. is empty, and the term itself is thus not helpful in
the description of English" (1994: 25).
My paper is at
least in part intended as an extension of Seppänen et al.'s work. The authors
do not offer corpus-based evidence for their claims but rely on native-speakers
as informants (Joe Trotta, personal communication). I do, however, believe that
corpus data can offer some new insights that may in fact lead to a somewhat
different evaluation of the argumentation presented. For this purpose, I will
provide data from the 100-million word British National Corpus (BNC).
My study is
based on the 25 most frequent complex prepositions in the BNC. Together, they
account for just over 60,000 tokens in the whole corpus and thus cover about 60
per cent of all constructions commonly held to be complex prepositions. I will
be concentrating on two of the four constituency tests discussed in Seppänen et
al., namely coordination and interpolation.
Coordination
If two strings can be coordinated, they must be constituents, and
must normally be identical functionally and usually even categorically.
(Seppänen et al. 1994: 13)
The following
three variants of coordination with complex prepositions can be found:
(7a) In terms of household income and the
number of working hours per week ...
(7b) In terms of household income and in terms of the number of working hours
per week ...
(7c) In terms of household income and of the number of working hours per week
...
The data
gathered from the BNC shows that constructions (7a) and (7b) account for the
overwhelming majority of instances. Although this does not per se invalidate the argumentation presented in Seppänen et al.,
it nevertheless suggests that when given a choice, speakers will treat complex
prepositions as a unit1. I will
also draw on further data from a subclass of coordination - correlative
coordination - in order to present a more complete picture of the choices made
by users of the language.
Interpolation
When elements are added to a structure, the new elements may be
inserted at some of the constituent boundaries of the clause, with heavy restrictions
depending on the particular case in question, but such interruption is totally
impossible with items which, in spite of rich internal structure, function as
single units with no syntactic constituent boundaries between them. (Seppänen
et al. 1994: 13)
The data for
interpolation shows a more evenly distributed picture for the different choices
available to speakers of English and thus offers less conclusive evidence for
any preferences taken. I will discuss interpolation as an indicator of constituent
boundaries and show with the help of corpus data that this test is less
relevant for the present context than is suggested by Seppänen et al.
Following this general discussion of constituency tests, I will show
that only a few types of complex prepositions (most importantly in terms of) make up the bulk of the
sentences supportive of Seppänen et al.'s argumentation and will discuss the
extent to which this, too, necessitates a re-evaluation of their approach.
Finally, I also hope to present the first results of a
collocation-based approach to the retrieval of complex prepositions, extending
the common formulae for the calculation of collocational strength from simple
node - collocate pairs to constructions with two or more collocates (e.g. the node
in followed by a noun which itself is
followed by a preposition within a certain number of words, such as in (...) pursuit (...) of). The data
will be used as a testbed for the claims presented in the literature.
References
Seppänen,
A., Bowen, R. and Trotta, J. (1994) On the So-called Complex Prepositions, Studia Anglica Posnaniensia 29:
3-29.
Hitoshi
Isahara, Toyomi Saiga (TAO1 /CRL2, Japan) & Emi Izumi (CRL, Japan)
The TAO Japanese
Learner Corpus of Spoken English (The TAO Corpus)
This is a
work-in-progress report of a project launched in 1999 for compiling a
one-million word speech corpus of Japanese learners of English. One of the main
characteristics of the TAO Corpus is that the corpus data is entirely based
upon the audio-recordings of an English oral proficiency interview test called
the Standard Speaking Test (SST). Based on the well-known ACTFL OPI (Oral
Proficiency Interview), this 15-minute interview test consists of several tasks
including picture description, role-playing, and story telling. One of the
unique features of the corpus is that each speaker's data includes his/her
proficiency profile based on the SST evaluation schemes, SST Level 1 to 9.
We are planning
to make this corpus open to the public so that teachers and researchers of many
kinds can use it for their own research interests: SLA, syllabus design, or
natural language processing (NLP), etc. Our purpose, as an NLP research group,
is to create a computerized pedagogical tool which can process inputs containing
learners’ errors. We will do this mainly by analysing learners’ errors from
each proficiency level with error tagging, then by constructing a model of
learner English across different proficiency levels.
In this report,
we will introduce this new Japanese CLE project, showing its data collection
procedure, the original tool for transcription, annotation schemes and also
explaining how to apply this data for the development of a pedagogical tool.
Randall L.
Jones (Brigham Young University, USA)
Problems of
Frequency Count in a Corpus of German
A language
corpus can be a useful tool for compiling information about word frequency.
Most software that is used for corpus analysis has tools that make it rather
simple to generate information about both relative and absolute frequency of
words in the corpus. Such information is useful, inter alia, for general
lexical research as well as for second language learning and teaching. It is
assumed that in the process of learning a new language frequency of usage is an
important criterion in the sequencing of vocabulary, i.e. the words used most
frequently by native speakers should be those that are learned first.
Vocabulary lists, instructional material, and even frequency dictionaries can
thus be based on this information.
Interest in
German word frequency dates back at least to the 19th Century, when
F. W. Kaeding published his monumental Häufigkeitswörterbuch der deutschen
Sprache. Festgestellt
durch einen Arbeitsausschuß der deutschen Stenographiesysteme in 1898. The work
is an object of wonder for several reasons, not the least of which is the fact
that it is based on a 10 million word corpus taken from 94 separate sources
before the advent of the computer. The nearly 700 word book which is full of
lists and charts was published by Kaeding himself. In 1928 Professor B.Q.
Morgan of the University of Wisconsin published a re-worked version of
Kaeding’s list intended for the teaching of German.
There have been
numerous frequency lists of German produced in the computer era, both published
and unpublished. One of the most useful was that of Professor J. Alan Pfeffer
of the University of Buffalo in 1964. It is based on his Grunddeutsch
material, which is a spoken corpus of German compiled in 1960 and consisting of
ca. 700,000 running words. It was the basis for vocabulary selection in many of
the elementary German text books published in the United States during the
1960s and 70s. Pfeffer’s list is the result of careful analysis and sorting. It
contains only headwords or lemmata, and not the numerous word forms.
Although the
computer is a marvelous tool for generating word frequency information, the raw
frequency data generated from a corpus is only the first step in the process of
compiling a useful pedagogical tool for vocabulary learning. Many of the words
must first be lemmatized and disambiguated. As is well known, lemmatization
means collecting all inflected forms of a word into a single headword or lemma,
e.g. German bin, bist, ist, etc. under the headword sein (to be).
The process of disambiguation separates homographs into their respective
meanings, e.g. sein (verb form and possessive pronoun), wohl
(particle and adverb), and heißen (verb form and adjective).
The processes of
lemmatization and disambiguation in German are not as straightforward as may at
first appear, especially if the corpus is not tagged. Many inflected forms of
verbs, adjectives and nouns can belong to one of several parts of speech, thus
a good deal of human intervention is necessary. For example, if one disregards
capitalization, the German form liebe can be a noun, a verb, or an
adjective. It becomes necessary to examine each form to see how to assign it to
its proper lemma. Even more difficult is the sorting out of homographs, as it
is not always obvious how many separate words a single form may represent, even
within the same word class.
This paper will
address these and other issues that are currently confronting the author in the
construction of a pedagogically oriented frequency dictionary of modern German.
It is based on his existing BYU Corpus of Spoken German as well as a written
German corpus which is now in the process of being compiled. The written corpus
comprises three million words and consists of a collection of printed material
containing samples in the three categories of journalism, literature, and
non-fiction prose, all published since 1990. One of the challenges of the
project is to balance the two corpora (700,000 vs. 3,000,000 words) as well as
control the range of the entries so that a word is not misrepresented because
of a preponderance of examples in a small number of texts. The final product
will be an annotated frequency dictionary of German that will contain the most
frequent 3,000 words in the corpus together with brief examples of their usage.
The examples will be authentic German based on the corpus material.
References
Jones,
R. L. (1997) Creating and Using a Corpus of Spoken German. In Wichmann, A., et al. (eds) Teaching and Language Corpora. London:
Longman, pp. 146-56
Kaeding, F. W. (1898) Häufigkeitswörterbuch
der deutschen Sprache. Festgestellt
durch einen Arbeitsausschuß der deutschen Stenographiesysteme. Selbstverlag
des Herausgebers, Steglitz bei Berlin.
Morgan,
B. Q. (1928) German Frequency Word Book. Based
on KAEDING’s Häufigkeitswörterbuch der deutschen Sprache.
McMillan,
New York.
Pfeffer,
J. A. (1964) Basic (Spoken) German Word List. Grundstufe.
Prentice-Hall, Englewood Cliffs
Przemyslaw Kaszubski (Adam Mickiewicz University, Poland)
GIVE and TAKE:
towards overcoming the bottlenecks in learner corpus linguistics
I would like to report in this
paper on some technical problems encountered in my recently completed PhD work
(http://main.amu.edu.pl/~przemka/rsearch.html).
In the project, I set out to examine the quantitative correlation between
several bands of proficiency in written English and relative frequency of use
of idiomatic and non-idiomatic expressions containing high-frequency primary
verbs. Findings for two such lemmas - GIVE and TAKE - will be cited in the
presentation to illustrate my points. The corpus network applied consisted of
small, argumentative/ expository collections (partly pooled from the International
Corpus of Learner English resource), featuring advanced and intermediate EFL
learner varieties, native English learner varieties, native English expert
writing, and contrastive native-tongue material (Polish).
Most learner-corpora projects tend
to rely on small, 'intimately known' text resources which are carefully read,
edited, annotated, etc. The necessity for a close relation with interlanguage
data is a methodological strength but also a serious drawback since many less
frequently distributed phenomena (such as specific collocations and idioms)
cannot then be studied convincingly with statistics. In my view, two major
kinds of factors, at least with respect to lexical studies, contribute to this
bottleneck: language- based and technical factors.
Language-based difficulties relate
to the quality of language in the investigated text corpora, often reflecting
the principles of corpus design and corpus compilation. Besides the statistical
question of representativeness, quantitative learner language research
typically relies on inter-corpus comparability, making it necessary to control
important variables, such as language task type; author age, proficiency and
demographic characteristics; text length; etc. Unfortunately, the more corpora
are involved in a project, the less easy it is to exercise control over their
linguistic and textual homogeneity, unless one chooses to exploit self-
compiled data only, which is usually not the case. One inescapable problem with
interlanguage corpora is their effective stratification according to
proficiency. With this, rough statistical measures, such as standardised
type-token ratios, may prove useful, as I will attempt to illustrate.
Many of the language-based
difficulties limit possibilities for computerised research. For instance,
although advanced students' writing has been found not to upset the
effectiveness of part-of-speech taggers (Meunier 1998: 21), comparison with
lower-level EFL texts, often fraught with misspellings, syntactic errors and
even punctuation irregularities, may be seriously hampered. In fact, the
error-margin left by a speech tagger may adversely affect even native English
findings, especially if the type of mistagging is consistent and goes
unnoticed. Distinguishing between verbal and non-verbal (nominal, adjectival,
auxiliary etc.) occurrences of English verbs can be helped but by no means
resolved by taggers, as the example of the passive vs. pseudo-passive vs
semi-passive differentiation can show only too well. Unfortunately, making such
fine distinctions is often essential in pedagogically oriented studies.
Collocational and phraseological
studies depend on other kinds of disambiguation as well. Correct word sense
disambiguation, although being developed e.g. through the Senseval Project, is
far from at an implementable stage. A different, Firthian way to finding out
about word meaning would be through building information about its
collocational network. However, automatic collocation extraction by means of
recurrent word strings or even collocation statistics (MI, z-score, e.g. in WordSmith
Tools or TACT 2.1) often produces too much noise in the outcome (low
precision), and is not very efficient for small corpora (low recall). Another
disadvantage of cooccurrence statistics is that often input cannot be
manipulated in the way the researcher wishes, and the values are calculated
from all rather than selected occurrences of wordforms or lemmas (a notable
exception is Oliver Mason’s QWICK).
In the end, an applied researcher
studying multi-word units in learner data is forced to find his own solutions
to faster annotation and retrieval of data. I would like to offer a few such
suggestions, based on my recent empirical work and the following resources: a
POS tagger/lemmatiser (TOSCA-ICLE Tagging Unit); corpus analysis tools (WordSmith
Tools, TACT), a text editor (Word97), a spreadsheet program (MS
EXCEL 5.0) and GNU UNIX-based text-editing programs ported to DOS (awk,
sed, cut etc.). At the end of the discussion, I will call for a more
universal concordance editing/extraction tool which, I believe, could serve to
ease many of the presented limitations in learner-corpus research.
The quick-and-dirty solutions may
comprise many levels of disambiguation, including:
a) the use of spell-checking
facilities and POS-tagging software for flagging and fixing undesirable
spelling, syntactic and other surface mistakes;
b) the use of GNU-UNIX text
analysis tools to target and edit unresolved ambiguities and heuristic tag
assignments, and thereby to preclude skewed statistics;
c) (less or more detailed) manual
disambiguation of concordance lines with the WordSmith Tools concordance
annotation facility;
d) (when collocations stats are planned):
saving (roughly) disambiguated concordance lines in text format to enable the
concordancer to re-read, and draw statistics for, the disambiguated set rather
than all the occurrences of a given family of wordforms;
e) assessing disambiguated
collocations / expressions and targeting statistically skewed types by
measuring standard deviation across the corpora, establishing a cut-off point
and double-checking for topic distribution in the textual data.
More enhancements could be added
if necessary. It seems that linguistically reliable studies of much larger
learner corpora could be possible if analysts had access to programs enabling
enhanced on-line editing from a set of concordance lines. Such
‘power-concordancers’ should allow editing both the original text AND POS tags
AND lemmatisation AND custom-made annotation. The results of completed
disambiguation processes should then be conveniently saved in a text file
(preferably pasted into the original corpus). They then could be called back
into the concordancing module for further analysis, e.g. for conducting
relevant statistical tests. Specifically for English phraseological studies,
the enhanced editing-concording package could be equipped with an on-line
dictionary of multi-word items to speed the process of disambiguation or inform
/ supplement the collocation statistics calculation.
The secret of successful learner
corpus analysis is in making the indispensable stage of manual editing as fast
as possible. This will not happen if there are no flexible and powerful tools available
that ordinary applied researchers, rather than dedicated corpus analysts or
programmers, can find accessible and useful.
Bernhard
Kettemann (University of Graz, Austria)
The BNC and or versus the OED
This
paper examines the usefulness of the Oxford English Dictionary (the OED) in
relation to the British National Corpus (the BNC). I will try to find out how
they complement each other in a semantic analysis.
The semantic
analysis is concerned with the different meanings of the morpheme eco. Eco
is not only one of the most fashionable prefixes in English these days, in
times of the Kyoto protocol renunciation, BSE and foot and mouth disease,
everything eco seems also politically relevant.
1
Additive and contrastive analyses
Basically, we can take two routes if we have
two sources of data, we can do an additive analysis or a contrastive analysis.
Additive analysis
Additive analysis means that we simply add up the data from the two
sources so that we end up with a superordinate pool of data which we then
analyse.
Contrastive analysis
Contrastive
analysis means that we take both sources of data and analyse them separately
and then contrast the findings, taking into account the different natures of
the two sources.
It seems to make
more sense to embark on a contrastive analysis of eco in the OED and the
BNC. This, however, first requires a discussion of the actual differences
between these two kinds of sources.
2 The
BNC and the OED – two types of data
The most
interesting difference between corpora and dictionaries is that the eco-words in the
latter are filtered, which means that not all words that have been found are
entered. The selection is based on the criterion of institutionalization.
Institutionalization means that a lexeme has a widely accepted intersubjective
status.
The BNC cannot
distinguish between institutionalized and less widely accepted lexemes. A
dictionary, however, fulfils the purpose of representing institutionalized
words by being the product of a number of linguistically-trained or at least
highly language-conscious lexicographers filtering. It will therefore be
interesting to see whether there are crucial differences between the eco-words
found in the BNC and those in the OED.
3 The semantics of eco
The range of meanings
that eco- assumes as a prefix is directly linked to the meanings of the
neo-classical compound ecology and its derivates, particularly the
adjective ecological. This means that there are six meanings of eco:
1. 1.
pertaining to the study of the interactive relations
between organisms
2. 2.
pertaining to a more integrative study in any field
3. 3.
pertaining to the (balanced) interaction between
organisms / environment
4. 4.
pertaining to the (balanced) interaction of entities
within any field
5. 5.
pertaining to the ecological movement
6. 6.
environmentally friendly
4 Pertaining to the (balanced) interaction
between organisms / environment
Table 1 lists all eco-words in the BNC and the OED where the
prefix eco has the meaning 'pertaining to the interaction between
organisms/environment' and where the base is itself a word of Greek origin.
Those words that occur in both sources have been marked in bold print.
|
BNC |
OED |
|
ecosystem/eco-system/ecosystematic ecoclimate ecosphere eco-castrophe ecotype/ecotypic eco-balance eco-crisis |
ecosystem ecoclimate ecosphere ecocatastrophe ecotype ecoclimatology ecophene ecospecies ecotone |
Table 1: Eco-words with Greek base and
meaning 'pertaining to the (balanced) interaction of organisms/environment'
The facts that
three of the ten most frequent eco-words in the BNC are contained in
this group (ecosystem¸ ecotype, ecosphere) and that the
majority of the terms also occur in both sources leads to the assumption that
words of this pattern are relatively easily institutionalized. The reasons for
this may be that the Greek base may lead to a feeling that the two parts belong
closer together than in cases where the base is of a non-classical nature.
Words of this sort further are typical of the socially revered scientific
register.
In words such as eco-friendly, eco-sound(ly), eco-ok, eco-sensitive,
eco-conscious, and eco-aware, eco has the same function,
being added to a non-classical base meaning either ‘beneficial to’ or
‘conscious of’. Though according to the examples in the BNC, this seems a
common process, these words lack the institutionalized appearance of the
examples with the Greek / Latin bases as none of them occurs in the OED.
5 Environmentally friendly
Table 3 lists lexemes found in the BNC where eco has the
meaning 'environmentally-friendly'.
|
eco-dosing eco-energy ecofuel EcoGen* ecogenetic eco-management ecopetrol |
ecoproduct eco-tourism ecovalve Ecover* Ecowash* ecoWater* |
Table 2: Lexemes with eco in the sense of
‘environmentally friendly’ in the BNC
Eco in the meaning of ‘environmentally friendly’ is a highly productive
prefix, which shows in the high type frequency and the low token frequencies.
As not a single word from this group has, however, entered the OED, I assume
that the ‘environmentally friendly’ function is less likely to result in words
that are easily institutionalized. This might be a result of associations with
the discourse of advertising (note that all words marked with an asterisk are
in fact brandnames), which is so quick to renew itself that the life-cycle of a
word is not long enough to receive the honour of institutionalization.
6 Pertaining to the ecological movement
Eco with the meaning ‘pertaining to the
ecological movement’ is added to bases that are connected with politics. All
examples of this kind are listed in table 3.
|
BNC |
OED |
|
ecoaction ecoglasnost eco-class eco-citizen eco-dork eco-fashionable eco-freaks eco-politics/ecopolitical eco-terrorism/ero-terrorists eco-trendiness eco-vandalism eco-wars |
eco-activist ecofreak |
Table
3: Lexemes with the meaning ‘pertaining
to / associated with the ecological movement’ in the BNC and the OED.
Even though the
function of eco described above does not occur very often in the OED, it
is remarkable that it appears at all. Together with the high number of types in
the BNC this suggests that ‘pertaining to the ecological movement’ is a major
meaning of this prefix, primarily as a productive morpheme but also one that to
a certain extent also leads to institutionalization.
The
other three meanings 1., 2., and 4. are rarely used according to the evidence
provided by the BNC and the OED.
7 Conclusion
Of the
six possible meanings of eco, three are highly productive. Of these, eco
in the sense of ‘pertaining to the environment’, particularly if added to a
Greek or Latin base, is most likely to result in a lexeme that will be quickly
established. This is a result of the formal kinship of eco and the base,
and also of the fact that these new lexemes appear to be derived from a
scientific register. Eco in the sense of ‘pertaining to the ecological
movement’ may result in increasing lexicalization because it is often used by
the political establishment to attach a derogatory label to the relatively new
green movement. Eco meaning ‘environmentally friendly’ is least likely
to be accepted very quickly, perhaps because of its association with the
ever-changing discourse of advertising.
What
conclusions can we draw from our research question. "The BNC and or versus
the OED"? This paper has shown that their different functions offer
complementary insights into the semantics of English. For a complete analysis
we need both types of data. So the answer is: the BNC and the OED, not versus,
but apart.
References
Armstrong, S. (ed.) (1994) Using
Large Corpora. MIT Press, Cambridge.
Aston,
G.
and Burnard, L. (1998) The BNC Handbook. Edinburgh University
Press, Edinburgh.
Barnbrook, G. (1996) Language
and Computers. Edinburgh University Press, Edinburgh.
Barton, D. (1994) Literacy. An Introduction to the
Ecology of Written Language. Blackwell, Oxford.
Bauer, L. (1983) English
Word Formation, Cambridge University Press, Cambridge.
Biber,
D.
(1993), Using Register-diversified Corpora for General Language Studies. In
Armstrong, S. (ed.) (1994), pp. 219-241.
Crystal,
D.
(1995) The Encyclopedia of the English Language. Cambridge University
Press, Cambridge
Crystal,
D.
(1997, 2nd ed.) The Cambridge Encyclopedia of Language. Cambridge
University Press Cambridge.
Fill, A. (1993) Ökolinguistik. Eine Einführung.
Gunter Narr, Tübingen.
McEnery,
T.
and Wilson, A. (1996) Corpus Linguistics Edinburgh University
Press, Edinburgh.
Murison-Bowie, S. (1993) MicroConcord Manual. An Introduction to the Practices and
Principles of Concordancing in Language Teaching.
Oxford University Press, Oxford.
Owen, D. (1980), What
is Ecology? Oxford University Press, Oxford.
Prechtl, P.
and Burkard, F-P. (eds) (1996) Metzler Philosophie Lexikon. Begriffe
und Definitionen. Metzler, Stuttgart & Weimar.
Quirk, R. (1974) The
Linguist and the English Language, London: Edward Arnold.
Göran Kjellmer (Göteborg University, Sweden)
Lexical
Gaps
One of the characteristics of a natural language is that it is
largely systematic. This is what makes it an efficient communicative tool. As
syntacticians, particularly those of the generative persuasion, have shown us
so eloquently, the systematicity of language allows us both to say or write and
to understand sentences we have never heard or seen before. If the syntactic
module of language is thus clearly systematic, the lexical one is less clearly
so. Nevertheless, there are large areas in the lexicon where systematic
tendencies, not to say rules, obtain. This is the case in word formation. For
example, presented with adjectives like readable
or circular the native speaker
expects there to be the derived nouns readability
and circularity, perhaps in addition
to other nouns. Inversely, the nouns readability
and circularity presuppose the
existence of the adjectives readable
and circular. If this systematic bond
between adjective and derived noun should break - if, say, we were to find readability but not readable - there would be a gap, an empty place in the system.
It is the aim of the present paper to investigate the existence and
nature of lexical gaps with the help of corpus material. In order to do so all
the adjectives in the Cobuild Corpus ending in the suffixes -ar, -ary, -ent, -ible, -ish, -ive were
recorded along with their frequencies in the Corpus. For each such adjective
its nominal derivations, if any, were recorded, again with their frequencies.
The derived nouns ended in -arity, -ence,
-ency, -ibility, -ishness, -iveness and -ivity,
less frequently in -ariness, -aryism,
-arialism, -arianism, -ibleness and -ivism.
Whenever a noun with one of those suffixes was found, it was recorded, whether
or not the corresponding adjective was found. When later the two lists, one of
adjectives and one of derived nouns, were matched, it frequently turned out
that items in one list had no equivalents in the other. Not only were nouns
corresponding to the adjectives missing, the opposite case also occurred,
although less frequently, viz. de-adjectival nouns having no base adjectives.
Generally speaking, such gaps are to be expected in a corpus of whatever size,
since in the lower frequency registers it is largely a matter of chance whether
a word occurs or not. Therefore the cases considered to be of interest were only
the most frequent of the adjectives with no corresponding derived nouns, and
similarly only the most frequent of the nouns with no corresponding base
adjectives.
It should be pointed out that the term "lexical gap" is
here used in an operational sense, in that potentialities are not taken into
account. Any one of the adjectives selected as the basis of the investigation
has a potential noun derived from it (any adjective in, say, -al has a potential nominal derivation
in -ality, etc.); likewise, any one
of the de-adjectival nouns has a potential adjective as its base (any noun in -ality has a potential adjectival base
in -al , etc.). However, if such a
potential word does not occur in the Corpus, it, or rather its non-occurrence,
is considered a gap.
When the most obvious gaps had been sorted out in this way, it
appeared that a number of factors were operative in the field, some acting on
one particular type of adjective or noun and some acting on most or all. It
also became apparent that some of them work in conjunction. When the operative
factors, or some of them, had been identified, they could account for the great
majority of the gaps. Nevertheless, a few mystifying gaps remain to be
explained.
A few general conclusions are that many lexical gaps are formal
rather than functional, that at least some parts of the lexicon have a high
degree of systematicity, and, unsurprisingly, that the lexicon is a very
flexible component of language.
Natalie Kübler (Université Denis-Diderot Paris 7, France)
Corpora in Terminology and Translation Teaching: Methodological
Approach
This paper
presents a methodological approach to the teaching of terminology and specialized
translation that is completely corpus-based and corpus-driven. It takes into
account the significant impact corpus linguistics has come to have on
linguistic thinking and teaching over the last years in France especially. This
approach is dedicated to linguists, terminologists, and translators who are
discovering corpus linguistics.
Tools and Corpora
The tools we use
consist of a commercialized term extractor (Terminology Extractor), a home-made
Web-based concordancer using perl-like regular expressions, and a frequencer
using the same kind of regular expressions.
Several corpora
have already been collected, but this is a constantly ongoing process. Our
corpora are mainly in French and English. The following types are readily
available:
-
- comparable corpora in general English and French;
-
- comparable in two different English and French LSPs: computing and
digital cameras;
-
- parallel (or translation corpus) from English into French in the
same subject areas;
-
- monolingual specialized corpora either in French or in English.
Among others,
some corpora that are currently being collected are comparable and translation
corpora in genetic engineering, with texts that have been written in French and
translated into English.
Methodology
Translating LSP
text requires an in-depth terminological analysis, as existing glossaries are
often incomplete and do not contain enough information about phraseology, collocations,
and translations into the target language, especially in fast developing
subject areas, such as technical ones.
Our
methodological approach deals with several steps in which translation and term
extraction are intimately linked. Separating translation and terminology in the
domain of LSPs can lead to missing important linguistic information.
In terminology
and translation, a very general query must be made; this leads to various paths
that must be followed one after the other. The search is narrowed little by
little, using a list of criteria that have been isolated by scrutinizing
corpora.
The approach,
which will be sequentially described, step by step, involves a constant coming
and going between monolingual, bilingual, general language, and LSPs corpora.
Monolingual corpora in the
source language
The first step
consists in collecting a list of potential terms in the source language, using
the Terminology Extractor on the texts to be translated. It is then necessary
to query the specialized corpus in the source language with the following aims:
-
- understanding the meaning of the various terms;
-
- spotting multi-word terms that have not been highlighted by
Terminology Extractor;
-
- extracting as much information as possible about syntactic
information and semantic classes;
-
- analysing the textual environment in which terms appear; this step
is most useful when the translation into the target language is difficult to
find;
-
- beginning to seek working hypotheses about possible translations.
A monolingual
corpus of general language serves the purpose of checking whether a term is
specialized or not, i.e. the term can have syntactic structures that do not
exist in the general language.
Parallel corpora and
monolingual corpora in the target language
Parallel corpora
are used to find possible translations in the target language. Not all
translations can be found in this way. That is why the first step is most
important: the context around a term can help to find a possible translation in
the monolingual target corpus.
Another
necessary step consists then in comparing possible translations in the target
corpus with their equivalents in the source text.
Example 1
The translation
of “activate a link” is in French “activer un lien”. However, adopting a
systematic approach, one discovers other verbs governing the term “link”, which
, in these cases is not translated into “lien” in French:
EN FR
Any other link comes up n’importe
quelle liaison démarre
After the link comes up une
fois que la connexion est lancée
Various
arguments are also found in the position of direct object for the verb
“activer”:
Activer: un canal, la mémoire, le débogage, la transmission, le cache, une
imprimante.
Support verbs or
full verbs are also collected in this way:
Faire un lien, créer un lien, établir un lien/
maintenir le lien, faire pointer un lien, supprimer un lien, modifier un lien
In other words,
our methodological approach allows translators to create a term base that is
complete and completely corpus-driven.
Example 2
Potential terms,
among others, including the unit resolution in the subject area of
digital cameras are: low resolution, high resolution, standard resolution.
Should these three candidates be listed as collocations or multiword units? In
the context of specialized translation, an important criterion consists in
examining the way the French translations of these collocations behave:
EN FR
low resolution faible résolution
high
resolution haute résolution
(“weak” resolution)
standard
resolution résolution standard
The position of
the adjective in French, as well as other different syntactic behaviour points to
the conclusion that the first two can be listed as terms, whereas the third
must be considered as a collocation. This situation thus led me to try and
answer some questions about the definition of collocation within a French
Linguistics paradigm. In some theoretical approaches adopted within French
Linguistics (theoretical approaches), the limits between a collocation, a
“frozen” expression, or a support verb and its noun predicate are quite
unclear.
Conclusion
The gap between
listening to someone explaining what wonderful results corpora can lead to, and
actually plunging into a corpus can be quite huge. Most students in linguistics
or translation studies are discouraged when faced with a corpus and a
concordancer. The systematic approach described here helps to guide people
through an ocean of data, and to develop a fine-tuned linguistic intuition.
Uta Lenk (Universität
Augsburg, Germany)
Time and
time again - More and more stabilized expressions with ‘time’
Fixed or stabilized
expressions, phrases, collocations or idioms are the subject of an
ever-increasing number of linguistic studies. The question of the (graded)
degree of stability of such expressions, and their importance within the
vocabulary of a language is now undisputed. However, satisfying explanations
for the nature of the gradation displayed in their fixedness and/or variability
remain to be found.
The current
project, based on the BNC and various spoken corpora of English, is an
investigation of the phraseological patterns of the high-frequency lexeme time and searches for such an
explanation. A multitude of patterns that include the word time, displaying differing degrees of fixedness, have been
identified and will be demonstrated.
The fact that
these patterns display different degrees of fixedness justifies a broad
categorization into three main groups that could be called ‘frozen expressions’ at one end of the
scale of fixedness, ‘semi-fixed
expressions’ in the middle and
‘stabilized expressions’ at the other extreme.
While ‘frozen expressions’ are lexically invariable (such as time and time again, by the time, from time
to time), ‘semi-fixed expressions’ allow for a limited range of lexical
variation in a certain syntactic pattern (i.e. a long/short time, at a/any/one/some (modified) time or (the) N of time). ‘Stabilized expressions’, finally, are
verbal patterns that allow for certain syntactic variation as they may
encompass a range of optional and/or obligatory slots that may be filled with
various valency requirements such as pronouns, or they may even include other
frozen and semi-fixed expressions (such as spend
time, take time, have time).
Between these
three groups, but also within, different tendencies regarding their
collocational behavior are noticeable. The stabilized expression spend time, for example, displays markedly different patterns of
distribution regarding not only the different types of the verb, but also the
different possible combinations with prepositional attachments (i.e. spent time in, spends time with).
Semantic aspects also contribute to these patterns of distribution.
The stabilized
expression take time comes with several meanings, each
of which display their own syntactic requirements, such as an 'empty subject requirement'
in it usually takes a long time to ...,
whereas have time is more frequently than not.used with a negation
The differences
in pattern appearances of the various ‘stabilized
expressions’ that have been identified are associated with the variability
of syntactic aspects on the one hand, but must also be seen in connection with
an as yet undescribed semantic variability of the node, time, on the other hand. For linguists, dictionary makers and
language teachers, the question arises as to how detailed an analysis of
collocational tendencies is indeed desirable and/or feasible, especially in the
light of an approachable and learnable definition for foreign learners.
Gunter Lorenz
(Universität Augsburg, Germany)
Standard English in the Light of Corpus Evidence: Aspect Rules or
Probabilities?
It can hardly be
disputed that, over the last fifteen years or so, the availability of
machine-readable language corpora has fundamentally changed the discipline of
descriptive linguistics. And while corpus linguistics has sparked off great
progress in almost all areas of the description of English, it has also served
further to deconstruct one of the most persistent myths of language description
and teaching – that of a homogenous ‘Good English’ standard.
The
pre-sociolinguistic concept of ‘Good English’, as agreed on by the linguistic
authorities and laid down in the standard grammars and dictionaries, was an
idealisation based on careful, educated, formal English usage. Such usage is of
course included in present-day English language corpora, but they are in no way
restricted to it. The 100 million word British National Corpus (BNC), for
example, consists of a wide range of spoken and written genres, with data from
speakers and writers of all ages and from a wide variety of social and regional
backgrounds. The more we study such rich variation, and the more we learn about
the wealth of variants, the more arbitrary a monolithic standard of English
will appear. In a corpus-based description of English, the formerly cast-iron
certainties of standard grammar often need to be replaced by probabilities – or
transformed into meticulous descriptions of linguistic and extra-linguistic
conditions and restrictions. This way even ‘macro-rules’ of grammar are reduced
in scope, and even the most frequently cited grammatical rules of English can
be found to be ‘violated’ in actual, native-speaker usage.
This state of
affairs, however, is not altogether new: learners have for a long time
tantalised teachers with counter-evidence for grammatical rules from pop songs,
the media or cryptic dictums from a native-speaking friend. English language
corpora, while posing a far greater challenge to grammatical description than
such accidental data, have also provided a partial remedy: they have allowed us
to research, rather than criticise, the seeming violations of ‘rules’; they
have enabled us to isolate and investigate, rather than marvel at, the
variability inherent in English grammar and usage – and they are forcing us to
re-evaluate the concept of a monolithic standard of English.
As a sequel to a
paper given at TaLC 2000, the present contribution will continue the thread of
probing into the variability of perfective and progressive aspectual marking. As
far as the perfective is concerned, there will be a brief discussion of the
relationship between use of the perfect and adverbial perfective marking –
through items such as yet, hitherto and since, for
example. This relationship, it will be argued, is not nearly as stringent as
some grammars of English (especially pedagogical) have held so far.
As regards the
progressive, there have recently been a number of studies concerned with its
variability and its increase in frequency (see, e.g., Mair & Hundt 1995, as
well as Smitterberg, Reich & Hahn 2000). Explanations have so far been of a
rather general nature, emphasising what has been termed the ongoing
‘colloquialisation’ of English, and maybe even language use in general. While
this interpretation certainly cannot be rejected from a wide perspective, it
does not explain precisely what governs the change from individual simple to
progressive variants. The present paper seeks to offer an additional view: by
narrowing the focus on selected members of two related classes of verbs, namely
those of ‘inert perception’ and ‘inert cognition’ (cf. Leech 1987: 24f), it
will try to show how new variants are construed in their individual
instantiations. It will be argued that the progressive offers new construals
for these verbs and the meanings they express – in one case (see)
leading to a new Aktionsart, and in another (think) leading to a
re-grammaticalisation of a lexicalised structure.
Returning to the
problem of ‘deconstructing’ standard grammar rules, corpus evidence such as the
present indeed works towards questioning the validity of variation-free
macro-grammar. But it would be wrong to hold corpus linguistics responsible for
the deconstruction of the standard: language corpora have not deconstructed the
grammar, but the concept of grammatical rules without variation. And there is a
strong case for the assumption that such rules do not in fact exist. Now the
Pandora’s box of linguistic description has been opened, the best that can be
achieved is to explore ever new types of variants with the aim of understanding
the nature of linguistic variation. For the present purpose, for instance,
conventional corpus data has been supplemented with what may be perceived as
examples of a particularly ‘sassy’, i.e. inventive, type of usage from the
media. It is in such ‘trendy’ usage that change and variation become most
apparent – not always of a permanent nature, but certainly of interest to
linguistic description. In relation to the main theme of the present ICAME
conference, one of the ‘future challenges for corpus linguistics’ might
include, on a practical level, incorporating more – and more recent – dynamic
audiovisual material into corpus research. On a more theoretical level future
challenges include reconciliation of corpus linguistics with other disciplines,
such as cognitive linguistics and grammaticalisation theory.
References
Leech, G. (1987) Meaning
and the English Verb. Longman, London.
Mair,
Ch.
and Hundt, M. (1995) Why is the progressive becoming more frequent in
English? A corpus-based investigation of language change in progress, Zeitschrift
für Anglistik und Amerikanistik 43(2): 111-22.
Smitterberg,
E., Reich, S. and Hahn, A. (2000) The present progressive in political and
academic language in the 19th and 20th centuries: a corpus-based investigation,
ICAME Journal (24): 99-118.
Fanny Meunier (Université catholique de
Louvain, Belgium) & Inge de Mönnink (University of Nijmegen, The
Netherlands)
Assessing the success rate of EFL learner corpus tagging
Introduction
The aim of our research project is to assess
the performance of an automatic part-of-speech tagger (namely the TOSCA-ICLE
Tagger Lemmatizer1) on learners’ written
productions in English, taking test data from the International Corpus of
Learner English (ICLE2). Once
the performance of the tagger has been precisely assessed and analysed, we will
first define and formalize the influence of the learner’s mother tongue on the
performance of a tagger originally designed for and trained on native English.
Secondly we will customize the tagger by implementing a number of changes
(either probabilistic or rule-based) in order to improve its success rate on
learner material.
Methodology
To answer the question of whether or not it is
valid to annotate learner data with a tagger trained on error-free native
English material, we have selected nine 5,000 word sub-corpora from ICLE,
representing 9 different mother tongue backgrounds: French, Dutch, German,
Polish, Spanish, Italian, Russian, Swedish and Finnish. These sub-corpora were
tagged automatically and the output was manually checked.
In assessing the performance of the tagger, we
classified the errors into three broad categories:
- tagging
errors due to learner mistakes
- genuine
tagger errors
- ‘shared
blame’ errors
Preliminary results
The performance of the tagger was lower than
the 95% claimed in earlier research (e.g. de Haan 2000). This difference may be
due to the fact that for the current assessment the tags were compared in
detail, including punctuation, and taking every single subclass into account.
More striking perhaps is that, contrary to our
initial expectation, the majority of the errors were not due to the
non-nativeness of the input, which constitutes an encouraging factor for
learner corpus tagging. Thanks to the probabilistic component of the tagger,
erroneous input was often tagged correctly.
Conclusion
A high percentage of the tagger errors we found
can be resolved by adding a few simple rules to the tagger. The output of the
new tagger should then be assessed anew and it is our firm belief that the
tagger will score significantly better, not only on learner data but also on
native data.
References
Aarts, J., Barkema, H. and
Oostdijk, N. (1997) The TOSCA-ICLE tagset. Tagging manual.
Nijmegen, TOSCA Research Group.
Granger, S.
(1996) Learner English around the world. In Greenbaum, S.
(ed.) Comparing English Worldwide. Clarendon Press, Oxford, pp.13-24.
Granger, S. (1998)
The computer learner corpus: a versatile new source of data for SLA research.
In Granger, S. (ed.) Learner English on Computer. Addison Wesley
Longman, London and New York, pp.3-18.
de Haan, P.
(2000) Tagging non-native English with the TOSCA-ICLE tagger. In Mair, C. and
Hundt, M. (eds) Corpus Linguistics and Linguistic. Proceedings of the 20th
ICAME Conference, Freiburg 1999. Rodopi, Amsterdam, pp.69-79.
Dieter Mindt (Freie Universität Berlin, Germany)
What is a
grammatical rule?
For
thousands of years grammarians have stated the regularities of languages in the
form of grammatical rules. We have become used to the concept of ‘grammatical
rule’ without asking questions such as
·
· What is the internal structure of a grammatical rule?
·
· When can we be confident of having discovered a grammatical rule?
·
· What is the place of exceptions and errors in the description of
language?
·
· What inferences can be drawn for language change from the structure
of a grammatical rule?
Corpus
linguistics sheds some new light on these questions. A fundamental research
design consists basically of three steps: collecting data, classifying data,
drawing conclusions from the classified data in the form of grammatical rules.
The procedure is inductive (from language to grammatical generalisation),
rather than deductive (from pre-stated rule to example).
The process
requires among other things the definition of grammatical categories together
with a descriptive framework outlining the essential features of the
grammatical phenomenon under investigation taking into account morphologic,
syntactic, and semantic information. These features can be described in the
form of variables which take a number of different values.
The final step
is to draw conclusions from the classified data in the form of grammatical
rules. If all previous procedures have been carried out properly we arrive at
the standard form of a grammatical rule.
There is one
important feature which characterises the standard form of a grammatical rule.
Of the many possible realisations, only between two and four make up the core
of an individual grammatical phenomenon. The paper describes the form of the
standard result using examples from morphology, syntax and semantics. A clear
borderline can be drawn between grammatical rules and the behaviour of lexical
elements.
The data provide
a new perspective on cases that are traditionally described as exceptions,
errors, obsolete uses and emerging tendencies.
The paper
concludes with a discussion of the following objectives
(1) (1) to achieve a closer approximation to the concept of
"grammatical rule"
(2) (2) to give new insights into the processes of language change.
Joybrato
Mukherjee (University of Bonn, Germany)
A functional corpus analysis of prosody-syntax
interactions in spoken English
At the ICAME conference in 1998, Jürgen Esser
outlined a new approach to the linguistic description and analysis of
prosody-syntax interactions in spoken English. His suggestions largely
capitalise on Halford's (1996: 33) concept of a talk unit as the "maximal
unit defined by syntax and intonation". For various reasons, her
definition, however, remains somewhat vague. This leads Esser (1998: 481) to
redefine the talk unit more precisely as a ‘stretch of speech which, at a given
point, is syntactically complete and ends with a falling tone’. The present
paper reports on some of the general results of a research project in which the
modified talk unit model was applied in the annotation of a 50,000 word sample
corpus in order ‘to analyse empirically how intonation and syntax come into
operation along with each other in authentic language use’ (Mukherjee 2001:
151).
The corpus material was mainly taken from the
London-Lund Corpus of Spoken English (LLC) and complemented with texts from a
small corpus of monologues including texts read aloud. All tone unit boundaries
were annotated by indicating the prosodic status (non-final in case of a rise;
final in case of a fall) and the syntactic status (non-final in case of
syntactic incompleteness; final in case of syntactic completeness). With regard
to the syntactic status, some finer distinctions were made, depending, for
example, on whether a syntactic structure is completed later in the text or
broken off in mid-sentence. In general, the talk unit ends whenever both the
prosodic and syntactic channel show a final status at a given tone unit
boundary followed by a new syntactic beginning to the right. Due to the fact
that the talk unit is defined both prosodically and syntactically it is
regarded as a parasyntactic presentation structure: at the level of parasyntax,
syntax and intonation are integrated (cf. Mulder 1989: 90), and by means of
stylistic choices at the level of parasyntax the speaker presents his or her
message to the hearer. The combination of prosodic and syntactic status at a
given tone unit boundary is called a parasyntactic configuration. Differences
in their use across the corpus is referred to as parasyntactic variation.
The quantitative corpus analysis
unveils significant and, at times, surprising correlations between the
parasyntactic variation and the stylistic (including text-typological)
variation across the corpus. The wealth of the statistical evidence vindicates the
general assumption that the talk unit represents a stylistically relevant unit
of presentation. Thus, the overall conclusion may be drawn that talk units
fulfil a communicative function.
First and
foremost, talk units function as information structural units. A talk unit
comprises one to many tone unit(s). According to Halliday (1994: 295), the tone
unit ‘is not only a phonological constituent; it also functions as [...] a unit
of information in the discourse’. In applying this information structural
interpretation of tone units, the functional corpus analysis reveals that
speakers tend to pack their message into contour-defined chunks of information
so that a tone unit indeed corresponds to an information unit. On the basis of
this parasyntactic information packaging, speakers choose parasyntactic
configurations at tone unit boundaries in such a way that an efficient and
effective hierarchy of tone units (as information units) is established. Generally
speaking, the parasyntactic configuration at a tone unit boundary signals to
the hearer the relative weight or importance of the subsequent tone unit. So,
the tone unit boundary serves as a kind of window through which the hearer may
look forward onto the next information unit (cf. Esser 1993: 144). The in-depth
analysis of authentic corpus data shows that both talk units as such and their
internal structure (in terms of segmentation and hierarchy of tone units) makes
it easier for the hearer to process the information presented by the speaker.
Secondly, the
corpus analysis shows that not only information structural functions can be
ascribed to talk units, but that talk units turn out to be relevant to speaker
interaction in conversations, too. In particular, talk unit boundaries provide
appropriate positions for turn taking. In this context, the grade of politeness
can be analysed and categorised on the basis of (prosodic and/or syntactic)
completeness at the very point of speaker shift. Hence, the concept of talk
units also contributes to a better understanding of some important linguistic
principles of turn taking which have been vaguely described in previous
approaches. This also applies to pausological research which has often
concentrated on the description of the demarcating function of pauses at tone
unit boundaries. Conversely, the talk unit-based approach highlights the fact
that many pauses in authentic discourse are used as ‘information structural
means in order to increase the hearer’s sense of anticipation whenever
syntactic incompleteness and/or prosodic openness is given’ (Mukherjee 2000 in
press).
In
the light of corpus data, the talk unit model turns out to be a very useful
descriptive framework. It certainly sheds new light on the interrelation of
prosody and syntax and has implications for information-structure theories and
conversation analysis.
References
Esser,
J.
(1993): English Linguistic Stylistics.
Niemeyer, Tübingen.
Esser, J. (1998):
Syntactic and prosodic closure in on-line speech production, Anglia 116: 476-91.
Halford,
B.
(1996): Talk Units: The Structure of
Spoken Canadian English. Narr, Tübingen.
Halliday,
M.A.K. (1994): An Introduction to
Functional Grammar. Second edition. Arnold, London.
Mukherjee,
J.
(2000): Speech is silver, but silence is golden: some remarks on the
function(s) of pauses, Anglia 118,
in press.
Mukherjee,
J.
(2001): Form and Function of
Parasyntactic Presentation Structures: A Corpus-based Study of Talk Units in
Spoken English. Rodopi, Amsterdam, in press.
Mulder,
J.
(1989): Foundations of Axiomatic
Functionalism. De Gruyter, Berlin.
JoAnne Neff, Emma
Dafouz, Honesto Herrera, Francisco Martínez, Juan Pedro Rica (Universidad
Complutense de Madrid, Spain), Mercedes Díez (Universidad
de Alcala, Spain), Rosa Prieto (E.O.I. Madrid, Spain) & Carmen Sancho
(Universidad Politecnica Madrid, Spain)
Contrasting Learner Corpora: The Use of Modal and
Reporting Verbs in the Expression of Writer Stance
This paper, part
of the work for a project funded by the Spanish Ministry of Education
(BFF2000-0699-C02-01), presents the results of a contrastive study of
qualification devices used in a 400,000-word corpus of English argumentative
text, produced by EFL Spanish university writers (SUW, from the International
Corpus of Learner English, ICLE, Louvain), American university
writers (AUW, from the LOCNESS Corpus, Louvain), and native
professional writers (NPW, newspaper editorials in English, the English-Spanish
Contrastive Corpus, Madrid).
We use the term qualification to indicate the means the
writer uses to express to the reader whether the information presented is to be
understood as fact or opinion (Hyland 2000).
By devices, we mean the grammatical
and lexical means used to construct writer stance,
defined as ‘…the positioning of a social agent with respect to alignment,
power, knowledge, belief, evidence, affect and other socially salient
categories’ (Du Bois 2000). Stance involves, then, not only the writer’s
expression of commitment, but also the effect that the writer presupposes the
stance taken up will have upon the readers, thus necessitating the use of
politeness strategies.
In a previous
study (Neff et al. in press), we examined certain modals of probability and
reporting verbs, as used by Spanish EFL writers and American university writers
to construct writer stance (Biber & Finnegan 1989). The findings regarding modal verbs showed
significant differences in the uses of can,
may, and might, but not of could. For the reporting verbs, results
showed that SUW overused say and
underused state. Along with the
overuse of we can, the under- and overuse of some reporting verbs seemed
to be working against impersonalization strategies in the Spanish EFL texts.
In the present
study, we attempt to explore these previous findings by carrying out a further
analysis of the same modals and reporting verbs in the argumentative texts of
the SUW (194,845 words), the AUW (149,790 words) and an additional third corpus
of professional writers of newspaper editorials, the PNW (113,475 words). In
addition to the previously mentioned modals, we decided to study non-epistemic must (e.g., we must consider) for possible use as a positive politeness
strategy (cf. we can). Results from these data are
contrasted with those from other ICLE sub-corpora (Dutch, French,
German, and Italian) for interlanguage issues and, for developmental questions,
with those from the MAD Corpus (first- and fourth-year Spanish EFL
university students writing in both L1 and L2).
Both this study
and the previous one have suggested that Spanish university writers construct a
different stance from that created by native writers. Below, we summarize our
conclusions.
1) Some of the
problems that SUW experience may be due to typological differences between
Spanish and English, that is L1 factors, for instance, an overuse of can influenced by the use of poder in Spanish. However, there may be,
as well, developmental factors to consider, for example, in the SUW’s overuse
of we can and we must as stance- or discourse-markers, but not of we may and we might. Since can is
the first modal verb learned in the Spanish EFL classroom, NNS may feel
comfortable using it – in the assumption that it covers the same degrees of
doubt as poder (can) in Spanish – and, thus, do not risk using other English
modals, such as may and might.
2) The
differences which appeared in the previous study in relation to the sociocultural
conventions used in constructing writer stance were confirmed in this study.
The SUW overuse of we can and we must followed by verbs of mental and
verbal processes points to a transfer of politeness strategies from the Spanish
academic context. The SUWs’ use of reporting verbs also further contributes to
the less impersonal writer’s role. The comparison of reporting verbs for the
three groups showed similar total tokens, but notably different frequencies for
individual verbs. This suggests that SUW not only concentrate on a limited set
of verbs, which restricts their possibilities of modulating their statements,
but also do not use inanimate subjects, which would allow for more abstract
agency. Such strategies point to broader issues of the interactional patterns
based on positive-politeness used in peninsular Spanish, that is
-power/-distance, while English may use, globally, more negative politeness
strategies, that is –power/+distance.
3) We
are well aware that some of these differences, particularly between the PNW
corpus and those of the student writers, may be a result of genre
characteristics, given that editorials are a very controlled type of text.
Nevertheless, we believe that non-native texts should not be compared solely to
native student texts, which may display some developmental characteristics not
present in more sophisticated writing.
Arja Nurmi (University of Helsinki, Finland)
‘I must let you knowe’: Modal auxiliary must in Early Modern correspondence
In this paper I
look at the item must in Early
Modern English Correspondence. The corpus used is the 2.7 million word Corpus
of Early English Correspondence (CEEC). The time period covered will be the
whole span of the CEEC (1410?–1681).
An earlier study
(Nurmi forthcoming), using the 0.45 million word Corpus of Early English
Correspondence Sampler (CEECS), showed that the frequency of the item must does not greatly change during the
16th and 17th centuries, staying mainly in the 10–20 instances /10,000 words
range. This is slightly lower than the results for Drama in the ARCHER corpus
in the17th century, but is clearly higher than the frequency for News or
Fiction (Biber et al 1998: 208). Earlier studies (e.g. Nurmi forthcoming) have
shown that the results from the full CEEC as opposed to the CEECS are likely to
lessen the fluctuation between subperiods, but on the whole follow the trends
attested in the sampler.
The reliability
of the CEECS was shown once again, when a total of 2858 instances of must were retrieved from the full CEEC:
the range of variation and the general trends in the development of must remained more or less within the
picture suggested by CEECS.
When the full
CEEC was divided into three subcorpora (15th, 16th and 17th centuries) a slight
increasing tendency in the frequency of the auxiliary could be observed, from
7.2 instances of must /10,000
words in the 15th century to first 8.1 in the 16th and 13.2 in the 17th
century.
Men and women
both show the rise in the frequency of the item must, but women’s use of the auxiliary increases faster than
men’s (women start from 4.2, move to 7.9 and finally to 15.6, while men start
from 7.8, move to 8.1 and in the 17th century to 12.2). The difference in
frequency between men and women is not very great, however.
The main focus
of this paper is on the sociolinguistic and socio-pragmatic variation
associated with a construction not part of an ongoing change. Most previous
work in the field of historical sociolinguistics has focused on changes in
progress. This time, it is interesting to see the variation connected with an
item only very slightly increasing in frequency for nearly three centuries. One
of the aims is to study the different meanings of must and their association with social variables. This is to
be a pilot study into the feasibility of such an undertaking, and, if
successful, will function as the model for a later application of the same
method to other modals as well.
The model of
meaning applied to must is the
fairly simplified one found in Biber et al (1999). The instances of must are classified under only two
meanings:personal obligation and logical necessity. In a corpus-based study, it
is necessary to have only few meaning categories, otherwise, when connected to
sociolinguistic variables, the results would suffer from what Rissanen (1989:
18) calls “The Mystery of Vanishing Reliability”. The application of a model
based on the Present-day English meanings of must
is not without its problems, but preliminary results seem to indicate that this
model can be applied to Early Modern English data without doing great injustice
to the material.
Examples of
logical necessity meaning of must
in the CEEC:
-
- he that hath nobody to work for him, must keepe shopp himself (John Holles, 1625)
-
- you must thincke we are brought to a lowe ebbe when the last
weeke the archdukes ambassador was caried to see the auncient goodly plate of
the house of Burgundie (John Chamberlain, 1613)
Examples of
personal obligation meaning of must
in the CEEC:
-
- All the hedges and fences must be allso presently made. (John Holles, 1630)
-
- I must confess this sodaine allteration of your purpose and
promise makes me imploye my patience and dewtie;
(Thomas Barrington 1629).
Since women’s
use of the item must seems to
increase more rapidly than that of men’s, it will be particularly interesting
to see what kind of meanings are used by men and women. One factor that may
have some bearing on the matter is the relationship between letter writer and
recipient. In the case of personal obligation it is also interesting to see who
the person obliged to do something is: the writer, the recipient or a third
person.
References
Biber,
D., Conrad, S. & Reppen, R. (1998). Corpus Linguistics. Investigating
Language Structure and Use. Cambridge University Press, Cambridge and New
York.
Biber,
D., Johansson, S., Leech, G., Conrad, S. and Finegan, E.
(1999). Longman Grammar of Spoken and Written English. Longman, London.
Nurmi, A. (forthcoming).
Modal auxiliaries in EmodE correspondence. Paper presented at the 11th
International Conference on English Historical Linguistics. 7–11 September
2000, Santiago de Compostela, Spain.
Rissanen, M. (1989)
Three Problems Connected with the Use of Diachronic corpora, ICAME Journal 13:
16–19.
Nelleke
Oostdijk (University of Nijmegen, The Netherlands)
Disfluencies in spoken language data
Spoken language corpora present
interesting new challenges to researchers who are working on the construction
of parsers. While over the past years efforts have been directed predominantly
at the implementation of parsers for the linguistic annotation of written
corpora, the idiosyncracies of spoken language data have been largely
neglected. The provisions that were made in order to deal with the spoken
passages in written fiction should be considered for what they are, viz. ad hoc
provisions that were made to prevent the parsing process from being upset and
forced to a halt. Meanwhile, in the light of the absence of parsers geared to
the analysis of spoken language, it is not surprising to find that parsers that
were originally constructed for parsing written language data are being applied
for the analysis of spoken data. The overall performance of the parser on such
data will prove very poor. What we see then is that in order to accommodate the
parser, language data are being normalized, i.e. they are made to conform to
what are postulated to be the ‘rules of grammar’. Such opportunistic doctoring
of the data is opposed to the view generally upheld in corpus linguistics that
the data are autonomous.
The present paper seeks to
investigate a number of phenomena that are considered to be characteristic of
spoken language use, in particular disfluencies such as hesitations,
false-starts and self-corrections. The aim is to get insight in the nature,
frequency and distribution of these phenomena, so that we may consider the
implications this has for the construction of a parser geared towards the
analysis of spoken language data. The study is based on the normalized data
found in the spoken part of the parsed ICE-GB corpus.
ICE-GB, the British component of the
International Corpus of English (Greenbaum 1996) comprises some one million
words of spoken and written English produced by adult, educated, native
speakers of British English. The texts in the corpus date from 1990-1994
inclusive, i.e. all texts were originally published or recorded during this
period (Nelson 1996a). The corpus has been fully tagged for part-of-speech
information, while it has also been syntactically annotated. In the annotation
process the TOSCA-ICE parser was used (Oostdijk 2000).
Prior to the linguistic annotation of
the corpus, all the material – both spoken and written – was marked up, using
two types of markup: (1) textual markup, which was added to the texts
themselves and typically encodes features of the original text that are lost
when it is converted into a computerized text file, and (2) bibliographical and
biographical markup, which was stored externally in the form of a file header
for each text (Nelson 1996b: 36). While it was observed that “spoken texts, and
especially dialogues require much more markup than written ones”, the set of
(textual) markup symbols was designed also to include symbols that could be
used “to indicate such features as pauses, speaker turns and overlapping
segments” (ibid. 39-42). Nelson’s discussion of the various markup symbols, however,
reveals that quite a number of them do not so much preserve features that would
otherwise be lost, but were introduced on the grounds that without these markup
symbols automatic parsing would be problematic:
This
system for marking overlaps was adopted because complete speaker turns are
essential for parsing. The marking scheme indicates the overlapping without
making the turns discontinuous.
(Nelson 1996: 41)
Especially with the spoken data from the
corpus, textual markup has been applied to normalize the input for the parser:
Spoken English is characterized by
a wide range of nonfluencies which are not found in writing. (…) These
phenomena are transcribed as they occur, and the markup for them will be of
particular interest to researchers studying the interaction between speakers.
However, they may be seen as disruptions of the underlying syntax, and as such
are problematic from the point of automatic parsing. We use the general term
'normalization' to describe the method of using markup to deal with them.
(ibid.)
Normalization involving
normative deletion is applied, for example, with repetitions, self-corrections,
and hesitations ‘when they disrupt the syntax’. Items marked for normative
deletion do not form part of the input to the parser.
Normalization involving
normative insertion includes the use of markup to complete the input. Here the
role of the annotator/linguist is rather objectionable since completing what
was left incomplete by the speaker can only amount to speculation. The same
goes for the normative insertions which aim to ‘correct’ the utterance. Here
the annotator/linguist imposes his own subjective norms as to what is
syntactically, semantically, or otherwise correct English by deleting what he
finds erroneous and then inserting what is considered to be correct.
While Nelson points out
that the “principle has been to normalize the original text as little as
possible, and to do so only when it was essential for parsing”, I want to argue
here that instead of using textual markup to modify the data whenever one sees
fit, a solution for the problems encountered in trying to parse spoken language
data must be found in obtaining insight in the nature of the phenomena and the
problems they pose for automatic parsing. Here the normalized data from the
spoken part of the ICE-GB corpus can serve as a starting-point.
From the 600,000-word spoken subcorpus
slightly over 10,000 instances were collected where the original input had been
normalized. In the data 15 categories were represented, ranging from direct,
spontaneous conversations to scripted speeches. First an inventory was made of
the average number of instances per text category. The results do not
immediately suggest a relation between the text category on the one hand and
the frequency of normalization on the other hand. Here, however, the idea comes
to mind that this might well be an artifact of the way in which the textual
markup has been applied. Next, on the basis of what helpful information could
be found in the literature (eg Fromkin 1973a,b, 1988; Garrett 1988, Nooteboom
1973; Tanenhaus 1988), a classification scheme was developed that should serve
to distinguish between different types of disfluencies. The scheme was then
applied to the data. The picture that emerged is one which suggests that in
many instances adaptation of the parser is feasible so that there is no need to
normalize the data prior to parsing.
References
Fromkin,
V.
(1973a). The non-anomalous nature of anomalous utterances. In V. Fromkin (ed.),
pp.144-163.
Fromkin,
V.
(1973b). Appendix. In Fromkin, V. (ed.), pp. 243-69.
Fromkin,
V.
(ed.) (1973). Speech errors as Linguistic
Evidence. Mouton, The Hague.
Fromkin,
V.
(1988). Grammatical aspects of speech errors. In Newmeyer, F.J. (ed.) (1988a),
pp. 117-38.
Garrett,
M.
(1988). Processes in language production. In Newmeyer, F.J. (ed.) (1988b), pp.
69-96.
Greenbaum, S. (1996.)
Introducing ICE. In Greenbaum, S. (ed.), pp. 3-12.
Greenbaum,
S.
(ed.) (1996) Comparing English Worldwide.
The International Corpus of English.
Clarendon Press, Oxford.
Nelson,
G.
(1996a). The design of the corpus. In Greenbaum, S. (ed.), pp.
27-35.
Nelson, G. (1996b). Markup systems. In Greenbaum, S. (ed.), pp. 36-53.
Newmeyer,
F.J.
(ed.) (1988a). Linguistics: The Cambridge
Survey. II Linguistic Theory: Extensions and Implications. Cambridge
University Press., Cambridge.
Newmeyer,
F.J. (ed.) (1988b). Linguistics: The
Cambridge Survey. III Language: Psychological and Behavioral Aspects.
Cambridge University Press, Cambridge.
Nooteboom,
S.
(1973). The tongue slips into patterns. In Fromkin, V. (ed.), pp. 144-63.
Oostdijk,
N.
(2000). Corpus-based English linguistics at a cross-roads. English Studies. A Journal of English Language and Literature 81(2
): 127-41.
Tanenhaus,
M.
(1988). Psycholinguistics: An overview. In Newmeyer, F.J. (ed.) (1988b),
pp. 1-37.
Pascual Pérez-Paredes
(Universidad de Murcia, Spain)
Networking
learner oral corpora: integration perspectives
In computer programming, integration is combining
software or hardware components or both into an overall system; in everyday
language it is the act or process of making whole or entire. In this work, we
want to do exactly that, in short, to present a framework for corpus data
gathering and implementation that integrates state-of-the-art technology and
network multipoint approaches into a learning environment. To this purpose, a
description of tools and procedures will be presented.
As Computer Assisted Language Learning (CALL)
spreads, educational institutions and students are becoming more familiar with
the use of computers in foreign language learning. These days, CALL
environments are progressively expanding their capabilities and functionalities
and, thus, it is not uncommon to find Universities or Secondary Schools in
Europe and the States where different learning formats (Jackson 2001) combine
to provide teachers and students with rich and varied learning experiences.
Simultaneously, learner language corpora have become
an important resource for both linguists and teachers, not surprisingly, for a
wide variety of reasons. It is claimed that learner corpora can provide
language teaching professionals and language researchers with a thorough insight
into the language actually used by foreign language students. FLT professionals
and linguists are very much interested in using corpora, and thriving symposia
such as TALC are a token of this interest. However, exclusively oral corpora of
students’ foreign language are scarce. Written language is, no doubt, still
dominant in the field. Very recently, Basturkmen (2001) has claimed that ELT
has focused its attention on describing and teaching the written language and
talks about spoken language as being neglected.
In this piece of research, we set out to explore ways
of incorporating oral learner corpora into mainstream CALL environments within
a technology-enhanced e-learning approach, as this has been the basis for our
research and our primary source of learner feedback. This environment is
characterised by (1) the pressence of the teacher in the computer facility; (2)
the fact that the sessions are, to different degrees, live, face-to-face and
instructor-led and (3) the use of materials which have somehow been previously
delivered to students as they are familiar with the type of tasks underlying
the corpus. Typically, this environment is asynchronous. A technology-delivered
e-learning approach was not considered, as our learner audience and the
instructor himself actually met to share the learning sessions.
At least six domains of interest have determined our
drive towards compiling and using a corpus of spoken learner English or any
other foreign language. The following reasons are common to both written and
spoken corpora:
1.
1.
A corpus can contribute to a
better understanding of students’ use of the foreign language.
2.
2.
It can offer teachers
classroom data that are not frequently analysed, fundamentally because
classroom dynamics make it extremely difficult for teachers to monitor every
learner’s performance. Usually, teachers tend to concentrate on fragmented
chunks of discourse and, more often than not, students are too aware of this
monitoring task, which in different ways can make learners shy away from
otherwise natural use of the FL. Such a corpus gives teachers the chance to
examine performances of students in detail, both as individuals and as a group.
In addition, learner oral corpora (LOC) might prove
useful in at least the following ways:
3.
3.
Learners’ oral performance
can be diagnosed and measured based on both qualitative and quantitative
information. This way, teachers can form a second opinion on their student’s
output and both on-the-spot and continuous assessment can be conveniently
enhanced.
4.
4.
Group assessment is favoured.
Teachers can establish accurate performance comparisons between two
individuals, between two groups of students or even between learner and native
speakers’ corpora. This is extremely useful when it comes down to deepening
into students’ oral output, a territory often neglected by educators and
learners themselves presumably believing that the very nature of oral discourse
is unapprehendable and elusive.
5.
5.
Teachers can build monitor
learner corpora that can contribute to changes and adjustments in their
methodology, particularly those aspects that are more directly connected with
developing students’ oral skills.
6.
6.
LOC can be used to promote
students’ language awareness of both segmental and suprasegmental aspects of
learners’ FL production.
All six purposes might potentially determine
different compilation, annotation, if applicable, and access criteria. In this
sense, Granger (1998: 8) lists some of the features that are relevant to
learner corpus building, distinguishing between language and learner variables.
In the first group we find medium, genre, topic, technicality and task setting;
in the second we find age, sex, L1, region, other foreign languages studied or
spoken, L2 level, learning context and practical experience. These features are
to be carefully considered and weighed up when designing learner corpora. It
seems that compilers have two options here. The first is to opt for
heterogeneous samples of learner language and account for them on different
levels, mainly those of representation, tagging and codification (Llisterri
1999: 54); the second is to strive for homogeneous collections of texts in
terms of the two broad categories presented above. This continuum is to be examined
by corpus builders in the light of the purposes and expectations generated by
the corpus.
Our research adheres to the second approach as we
believe functional parameters to be absolutely necessary when design stages of
an oral learner corpus are first sketched out. As any corpus serves a purpose
which must be conveniently kept to (Sánchez et al. 1995), our proposal here is
to link learner oral corpora to their expected audience, functionality, access
technology and network delivery system. In the main, we will discuss three
major types of learning formats that can be conveniently adapted to learner
oral corpora implementation: asynchronous self-study, synchronous
instructor-led events and, third, group collaboration. These formats will
combine with the purposes outlined above offering a wide range of potential
activities for the FL classroom. The principle underlying our discussion is
that Computer Based (CBT) and Instructor Led Training (ILT) can both play a
decisive role in boosting the use of customized oral learner corpora in
language teaching institutions. In the same manner, this work aims at
increasing the relatively small amount of research into computer networking and
language learning (Kern and Warshauer 2000).
Susan Pintzuk
& Ann Taylor (University of York, United Kingdom)
The effect of quantification on verb-object order in Old and Middle
English
The fact that English changed from a predominantly OV to a strict VO
word order language over time is well known. Less is known about exactly how
this change came about. Van der Wurff (1999) makes the interesting observation
that the change did not affect all NPs at the same time; rather, positive NPs
(that is, non-negative, non-quantified NPs) lose the ability to appear in
preverbal position before quantified and negative NPs. Van der Wurff's
interpretation of this difference relies on a grammatical reanalysis at the
beginning of the 15th century. Using a Kaynian head-initial framework, he
assumes that the derivation involves movement to specAgrO; but the result is
the same if an underived OV base order is adopted instead, as he himself notes
(van der Wurff 1999: 253, fn.8). At the point of the reanalysis, the original
derivation for OV word order is lost, but an alternative derivation becomes
available for quantified and negative NPs: namely, quantified NPs move leftward
over the verb by overt quantifier raising, while negatives move leftward to
specNegP. Thus, under van der Wurff's hypothesis, all NPs behave alike up to
the 15th century; afterwards, negative and quantified NPs behave differently
from positive NPs.
There is, however, an alternative analysis available for this data,
namely that negative NPs, quantified NPs and positive NPs behave differently
right from the beginning of the Old English period. Kroch and Taylor (2000) and
Pintzuk (2000) have suggested that in both Old and Middle English there is
grammatical competition in the underlying structure of the VP, VO vs. OV, with
the frequency of VO structure gradually increasing at the expense of OV
structure, until OV is completely lost in Late Middle English. The synchronic
evidence from Old and Middle English demonstrates that there is a distinct
difference in the derivation of positive preverbal objects as opposed to
negative and quantified preverbal objects: that is, preverbal positive NPs have
only one derivation, base-generation, while preverbal negative and quantified
NPs may either be base-generated or scrambled leftward from postverbal
position. Consequently, van der Wurff's claim that there was no difference in
the behaviour of the three types of NPs prior to the reanalysis cannot be
correct.
In this paper we use data from three corpora, the Brooklyn Corpus
and the York-Helsinki Corpus for Old English and the Penn-Helskinki Corpus for
Middle English to examine in more detail the long-term effect of NP type on the
course of the change from OV to VO. During the Old English period, there is a
decrease in the frequency of preverbal positive objects which is strongly
influenced by the length of the NP, suggesting that most objects are
base-generated preverbally with postposition of heavier objects. Negative NPs,
on the other hand, show little if any decrease in preverbal frequency, and
quantified NPs fall somewhere between the two. In Early Middle English, there
is a similar decrease in frequency of preverbal NPs, but only negative and
quantified NPs show a length effect; positive NPs, in contrast, show no length
effect. This suggests that, unlike in Old English, the vast majority of
positive NPs are base-generated postverbally. Moreover, the frequencies of the
three types decrease at different rates. This can be interpreted as the
converse of the Constant Rate Effect (Kroch 1989) and provides strong evidence
that the derivations of the three types are different at least from the
beginning of the Middle English period. After all, if the three types are
derived in the same way, we would expect the frequency of preverbal position to
decrease at the same rate for all three.
In conclusion, we have shown that the quantitative diachronic
evidence supports the earlier qualitative synchronic evidence that positive,
quantified and negative NPs do not all behave in the same prior to the 15th
century, as van der Wurff's analysis predicts.
Antoinette
Renouf (University of Liverpool, United Kingdom)
WebCorp: providing a renewable energy source for
corpus linguistics
Introduction
A
previously unimaginable number and range of electronic text corpora are now
available to corpus linguists, ranging from small and sampled collections to
very large textual databases. Whilst this wealth of data makes possible many
types of corpus-based research, particularly in the formerly rather
inaccessible areas of lexis and lexico-grammar, it has inherent limitations.
One is that the appropriate corpus data and software may not be available at
the required moment without special arrangements having been made - access to
the right computer, appropriate licences having been obtained, and so on. Other
limitations are the size, modernity and static nature of the corpora, which can
preclude certain kinds of linguistic empirical investigation, for instance the
study of very rare, new or changing language features.
An
alternative source of linguistic information is the web, a publicly available
data resource containing a vast and evolving accumulation of texts. Admittedly,
this is not contructed or managed with the rigour or for the purpose of a
corpus. It is a muddle of multilinguality; it operates a loose definition of
‘text’ which includes all manner of extraneous matter; text dating is sporadic
and linguistically uninterpretable, so that neither the latest coinages nor the
elements of language change across time that are undeniably in there are
identifiable by means of chronological organisation. Nevertheless, as a
renewable resource which in itself costs the linguistic community nothing to
create or access, it is worthy of serious consideration.
Meeting the need for
immediate and free access to textual data
The
web offers immediate and free online access to some large English corpora. Both
the BNC and Bank of English provide free response to word and phrase searches.
As Rundell (2000) says, the output is ‘deliberately limited in order to
encourage you to opt for the full package’, and even then, ‘you will only get
back 40-50 corpus lines for any inquiry’. Nevertheless, as he concludes: ‘these
sites are a good starting point for the occasional corpus query. Even 50
contextualized examples of going to would be a good basis for some
useful hypothesis-testing’.
Meeting the need for
very large amounts of up-to-date textual data
The
web is both larger than any corpus and constantly updated. One way to exploit
its potential as a linguistic resource is to extract texts which, together,
make up a corpus deemed to be representative of something, such as ‘general
language use’, or a technical field. Kilgariff (2001) et al., for instance, are
currently collecting reference sets of urls, from which domain-specified
corpora which the user can create by downloading, without copyright
infringement.
Another
approach is to exploit the functionality of web search engines. Standard
engines operate by searching the web for information containing a specified
search term. A small effort of imagination recasts this in corpus linguistic
terms as searching the web for contexts containing a target word or phrase. A
growing number of researchers have been driven, by the absence or insufficiency
of evidence in existing corpora for rarer or newer linguistic items and
features, to attempt a trawl of the web by this means. Search engines are,
however, not designed to accommodate such an approach, and the consequent negotiation
entails tedious serial searching and downloading of individually thin pickings,
followed by painstaking manual editing of whole texts. Each search engine
covers only a slice of the web, and only retrieves search terms in its
periodically-updated index. Google, which is unique in extracting context for
search terms, cannot trace Sophiegate, of April 2001 vintage, by early
May. As a linguistic search tool, its results are also skewed, in including
only one instance of a search term from a given web page on which it may
actually occur several times.
The WebCorp Tool
A
further leap of imagination reveals the web to be ripe for exploitation by
software tailored to find and retrieve contextualised instances of words and
phrases. Such information could serve the linguistic community in areas of
linguistic, pedagogic, lexicographic and other endeavour by filling the
information gaps left by traditional corpus data. This was the point of
departure for the WebCorp project, launched in December 2000 in the Unit at
Liverpool. The project team consists of Mike Pacey and Andrew Kehoe, software
developers; Paul Davies, statistical consultant; and myself, linguist and
project originator and manager. Michael Hoey, as PL, is on hand with linguistic
advice; Themis Bowcock, as CL, steers us through web and post-web developments.
The WebCorp tool is being developed according to an intensive and ambitious
two-year project plan, which has been informed in part by the copious feedback
received in response to a simple prototype software demonstrator installed on
the web in May 2000. Among the many unsolicited expressions of enthusiasm for
the WebCorp tool, Michael Rundell stated in his paper entitled ‘The biggest
corpus of all’ (Rundell 2000) that:
...a major
breakthrough is at hand, in the form of a stunning new website that produces
real "concordances". As with Altavista and others,
http://www.webcorp.org.uk/ [i.e. WebCorp] searches the entire Internet for your
query. But in this case the output is a proper concordance with an amount of
surrounding context which the user (that's you) can specify in advance. The
results, in other words, look very similar to what you might get from the BNC
or COBUILD Direct - but in this case the "source data" is the vast
store of text on the entire Internet.
Basically,
the WebCorp tool interfaces with the user request, converting it into a format
acceptable to a selection of existing search engines. It then piggy-backs on
one or other of these that has been specified by the user. Each search engine
follows its own procedure for searching a section of the web for texts
containing the specified language item. Once the engine has traced the search
term, via its own index, to a candidate text, WebCorp downloads that text into
memory and extracts the appropriate linguistic context, processing and
collating it before presenting it to the user. This basic functionality is
relatively simple to achieve. The real challenges lie in developing a closer
understanding of the web's structure and content, and in devising ways of
compensating for the current limitations of search engines in order to produce
a maximally efficient, informative and user-friendly tool.
Current State of
WebCorp Functionality
Progress
is incremental but swift. Since the prototype tool was first reported on
(Renouf 2001), a new version has emerged, with improvements including smaller
font and compact presentation for concordance lines, numbered concordance
lines, and HTML-centred keywords. The next version (4.7) of the tool will soon
incorporate type/token counts for web pages, contiguous collocational
statistics, and improvements in speed of search and retrieval. WebCorp
presently allows the user to specify search engines/s, data source and
concordance format; by way of illustration I offer below a 10-word context,
HTML-formatted concordance extract retrieved via the Northern Light search
engine at midday on May 2nd, 2001.
Sample WebCorp output for the recent
neologism, Sophiegate:
1. isn't likely to end "Sophiegate"
soon. Word is, the newspaper
2. called R-JH. Thanks to Sophiegate
, she's stepped down and
3. the sharp end of the Sophiegate
skewer. Tony Blair put on
4. Britain's closet republicans. Sophiegate
is a huge blow to
5. monarchy faces tough choices over "Sophiegate"
tapes. Apr 06 2001 17
6. interest between the two. The "Sophiegate"
affair will also be a
7. to say that the recent "Sophiegate"
scandal involving Sophie Rhys-Jones
8. lucrative deal. The so-called "Sophiegate"
scandal led many newspaper editors
9. Pak-origin scribe set up `Sophiegate'.
Pope commemorates Good Friday
10. isn't likely to end "Sophiegate"
soon. Word is, the newspaper
11. column Marketing & PR|Press &
publishing 'Sophiegate': what the papers say
12. 2001. Mark Lawson on the Sophiegate.
31 Mar 2001. Mark Lawson
In
this particular case, WebCorp is able to extract up-to-the-month results for a
vogue formation; it can equally yield instances of usage which is stable but
rare, too rare to appear in established corpora. The extract serves to
demonstrate that the web, when accessed by WebCorp, offers linguistic evidence
that is not supplied by existing text corpora.
Acknowledgement
We
acknowledge the support of this research by EPSRC, with thanks.
References
Kilgarriff,
A.
(2001). Web as corpus. In Rayson, P, Wilson, A., McEnery, T., Hardie, A. and
Khoja, S. (eds) Proceedings of the Corpus Linguistics 2001 Conference;
UCREL, 2001, pp.342-344.
Renouf,
A.
(2001). The Web as a source of linguistic information. In Rayson, P., Wilson,
A., McEnery, T., Hardie, A. and Khoja, S. (eds) Proceedings of the Corpus
Linguistics 2001 Conference ; UCREL, 2001, pp. 492
Rundell,
M.
(2000). The biggest corpus of all. Humanising Language Teaching 3
(May 2000) (http://www.hltmag.co.uk/may00/idea.htm).
Geoffrey
Sampson (University of Sussex, United Kingdom)
Structural data on the acquisition of
writing skills
Most British
children reach school speaking English fluently. If all goes well they complete
compulsory schooling as skilled users of the written language. The compilation
of structurally annotated corpora is starting to open up new possibilities of
studying the trajectory taken in moving from one stage to the other.
Our recent
CHRISTINE and current LUCY projects have been compiling annotated corpora of,
among other genres:
* conversational speech
* published writing
* writing by 9-12 year old children
All samples are
annotated according to exactly the same scheme, defined in Sampson (1995). This
paper discusses some initial findings extracted through statistical comparison
of these samples.
Writing "wordier" than speech
A first
expectation is that words in published writing are likely to be organized into
more elaborate constructions, on average, than words in spontaneous speech. We
cannot examine this in terms of "average sentence length", because
sentences are not well-defined units in speech; instead, I examined mean length
in words of all constructions:
speech 4.62
child writing 7.68
published writing 9.45
The average
construction in published writing is about twice as long as the average spoken
construction, and the average construction in child writing is intermediate.
Width v. depth in parse-trees
Ignoring details
of individual constructions for a moment and thinking just about the abstract
geometry of parse-trees, there are two ways in which mean construction length
can differ. Branching can be wide, and it can be deep. By wide branching I mean
that a tagma may have many ICs (daughter nodes); for instance, "a
man" is a noun phrase with two daughters, "a funny little man [who
made us laugh]" is a phrase with five daughters. By deep branching I mean
the extent to which structures exploit the recursive nature of grammar to create
long chains of branches between words and root nodes. A tree with deep
branching will dominate many words even if each nonterminal node is only two
ICs "wide".
Width and depth
are not mutually exclusive, and one might expect both to be relevant to genre
differences. That turns out to be wrong. Average ICs per construction are:
Speech 2.860
child writing 2.860
published writing 2.759
-- essentially
no differences.
For depth, things
are different. To make my figures for depth as theory-neutral as possible, I
have counted depth of words in terms of the number of clause nodes between the
word and the parse-tree root. Mean word depths are:
speech 1.365
child writing 1.401
published writing 1.857
These figures
perhaps do not look very different, but that is a consequence of the way depth
is counted. You cannot have a subordinate clause without words in a matrix
clause introducing it, so increasing the overall depth of embedding in a
parse-tree does not increase the average word depth in proportion. But these
differences are very solid. On a one-tailed t-test, the difference between word
depths even as between speech and child writing (where the mean difference is
smallest) gave a significance statistic far beyond the critical value for p
< 0.0001, the largest critical value I could find.
That does not
mean that the large difference shown above between mean depth in speech and in
published writing is wholly attributable to the difference between linguistic
modes. We know from earlier work (Sampson 2001) that mean depth of grammatical
structures increases with age, not just in childhood but throughout adult life.
The average published writer is probably older than the average in the whole
population, so the authors of the published writing may be individuals whose
speech structures were relatively complex. But the published writing v. speech
differential shown above is about seven times greater than the difference,
within the speech sample, between middle-aged speakers and the overall average.
Thus it seems
that the difference in "wordiness" between published writing and
speech relates to greater use of recursion, and in this respect the children's
writing has moved part-way from the spoken towards the adult written norms. Let
us now examine specific constructions.
Phrase categories
I used the
chi-squared test to test for significant differences between incidence of
various categories of tagma within the total set of tagmas in the three
samples. In the following, an entry such as "sp < cw = pw" means
that, for the given grammatical category, the rate in speech is significantly
lower than in child writing, but there is no significant difference between the
child-writing and published-writing rates. ("Significant" means p
< 0.05, but in fact each significant difference achieves at least p <
0.01.) "x >> y" means that the rate for x is over 50% greater
than for y.
noun phrase sp
<< cw = pw
verb group sp
>> cw < pw
prep. Phrase sp
<< cw < pw
adjective phrase sp
< cw = pw
adverb phrase sp
= cw = pw
number phrase sp
> cw >> pw
determiner phrase sp
>> cw = pw
genitive phrase sp << cw
= pw
In each case but
number phrases, the child writing figure is closer, often much closer, to the
published writing than to the speech figure. In the area of phrase grammar it
seems that the children have moved quite a long way along the path of
adaptation to the norms of ‘model’ written prose.
Subordinate clauses
For subordinate
clause categories the story changes. (Here, for some of the less-frequent
categories, significant differences attain only the p < 0.05 but not the p
< 0.01 level.)
The commonest
subordinate-clause type is the infinitival clause: its frequency is very
similar in the three samples and what differences occur are non-significant.
Otherwise
(ignoring two types which are very infrequent in all genres) subordinate
clauses can be classified in four groups.
(1) nominal clause sp >> cw << pw
verbless clause sp
>> cw < pw
antecedentless relative sp
>> cw = pw
bare non-finite clause sp >> cw = pw
These clauses
are less frequent in published writing than speech, and the child-writing
figure is closer to published writing: one might say that children have
successfully learned to ration their use.
In the case of
nominal and verbless clauses, this rationing has "overshot" in the
sense that the child-writing usage is even lower than in published writing. I
cannot explain the figures for nominal clauses; for verbless clauses I suspect
that the children have taken thoroughly to heart teachers' injunctions to
"write in complete sentences".
(2) adverbial clauses sp = cw >> pw
Child writing
reflects the relative high usage in speech.
(3) present participle clauses sp = cw << pw
comparative clauses sp
= cw = pw
"with" clauses sp
= cw = pw
special "as" clauses sp
= cw << pw
Child writing reflects
the relatively low usage in speech, or there are no significant differences
between child writing and either of the other genres.
Groups (1)-(3)
are "easy" cases: either children's writing resembles spontaneous
speech with respect to the figure in question, or the children have learned to
do something less often than in speech. The "harder" case,
presumably, is where published writing shows a higher incidence than speech,
and the children's writing is closer to the former:
(4) relative clause sp
<< cw = pw
whiz-deleted relative sp
<< cw = pw
past participle clause sp
<< cw < pw
These are,
logically speaking, variants of one construction. Apparently, children at the
relevant age have learned to adapt to adult written norms (where adaptation
means using more than in conversation rather than fewer) earlier in the case of
relative clauses (and their logical equivalents) than with other
subordinate-clause types.
Anyone can
understand why adaptation might be faster for phrases than clauses: phrases are
simpler. But, among clauses, one might feel that relatives are more complicated
than other types, not less complicated. So these findings are not what one
might expect.
Conclusion
The
above analysis is obviously extremely broad-brush and crude. Most of what we
would like to know about children's acquisition of literacy relates to far more
detailed properties of language. But those features too, or many of them, are
available for study in this range of annotated corpora. When one first begins
to extract analytic findings from a body of data, one naturally examines the
most obvious and immediate properties. The above is not a very subtle analysis.
But it is a beginning.
References
Sampson, G.R. (1995) English
for the Computer. Clarendon Press, Oxford.
Sampson,
G.R.
(2001) Demographic correlates of complexity in British speech. Ch. 5 of
Sampson, Empirical Linguistics. Continuum.
Josef Schmied (Chemnitz University of
Technology, Germany)
Learning English prepositions in the
Chemnitz Internet Grammar
This
presentation uses a contrastive translation corpus and a (contrastive,
deductive) grammar (book) on the web as a basis for contrastive linguistic and
language learning research. It discusses the sociobiographic questionnaire, the
tracking mechanisms and the first results of the experiments on students’
behaviour in the Chemnitz Internet Grammar. It uses prepositional phrases as an
example and compares the deductive explorations and the inductive searches for
corpus samples and the work on the exercise component. Although prepositions in
German and English appear rather similar on a general quantitative level, some
specific analyses show that particularly non-prototypical and metaphorical
usages can be quite different. This analysis offers some concrete examples of
linguistic problems and resulting learner strategies, distinguishing between
several user types, like age, computer literacy and other variables that might
have an influence on the choice of learning style. In this context, I will also
compare the emphasis of linguistic and psychological perspectives of
‘explorative learning as work’ and present further plans on the Chemnitz
Internet Grammar.
Kristina
Schneider (University of Rostock, Germany)
Extending
the Rostock Newspaper Corpus: Contrastive Analysis of German and English News
Reports
Having assembled
a corpus of English newspapers from 1700 to 2000 (the Rostock Newspaper Corpus or RNC), we have now started to extend
the corpus to cover German newspapers (and later perhaps newspapers published
in other European languages) to permit contrastive studies.
The initial
design and analysis of the German corpus will be based on the selection
principles underlying the English corpus, which were presented at ICAME 1999 in
Freiburg (cf. Schneider 2000a), but various modifications are envisaged for
later stages of the corpus compilation.
Overall
corpus design
Period: 1700 to 2000 in 30-year intervals
Sample size: 10,000 word samples from 6 newspapers per period
Corpus-lines: Distinction between popular and quality papers
For the initial stage the German corpus
will cover the same period, consist of the same sample intervals, the same
sample sizes and will attempt the same differentiation between popular and
quality papers.
Selection
of newspapers for the corpus
The selection
will be based on 'newspaper profiles' using the following criteria for the distinction
of popular and quality papers: external criteria (circulation and price) and
internal criteria (news content, i.e. percentage of hard news and soft news;
non-news content such as advertisements and serialisations; and layout, e.g.
decorations, titles and sub-titles).
Judging from a pilot study of German 18th
and 19th century newspapers, there seems to be a certain division
between popular and quality papers, although this distinction is probably less
pronounced than in the English press at the time. Most early German newspapers
still concentrate on hard news (politics and business) and occasionally show instances
of borderline cases, but seem to contain few clear-cut instances of soft news
(human-interest material such as natural disasters, accidents and crime). This
contrasts with English newspapers of the same period which quite frequently
include soft news. Another factor which might make it difficult to spot popular
papers is that the early German samples show fewer decorations and less
spectacular titles and sub-titles than the respective English newspapers.
Corpus
analysis
The corpus analysis of the English
corpus proved that differences between popular and quality papers are also
reflected in the language used (sentence length, paragraph length, word length,
choice of vocabulary, including forms of address and names), and that it is the
popular papers which usually introduce important new trends: trends towards
better readability (e.g. short and less complex sentences) and more emotional
involvement (e.g. frequent use of buzz words and superlatives). These
parameters will also be applied to the German corpus, but may have to be
changed to account for the morphological bent of the German language compared
to English.
As in the investigation of the English
corpus, special attention will be paid to the development of headlines. In particular,
we will examine the claims put forward by Wölfle (1943: 411) and Sandig (1971:
139, 142f), namely that German newspapers – compared to their English
counterparts - lagged behind in the use of headlines, and that the first
headlines were devoted to political events (e.g. 1848 Revolution in Paris, 1870
Franco-German War) and not to soft news items as in our English samples. It
will also be interesting to compare the use of nominal and verbal headlines (or
regional and relational headlines, cf. Schneider 2000b) in German and English
newspapers, since the German language tends to prefer nominal constructions
(cf. Sandig 1971: 147, 157).
Differing
political and socio-economic conditions
Contrastive
studies thrive on differences. As far as English and German newspapers and
their readership are concerned, these differences are abundant as proved by the
following selection:
1.
1. Whereas
the English press was to a large extent concentrated in London, the German
newspaper landscape faithfully reflects the political fragmentation in
pre-Bismarck times and later the federal structure of German society.
Therefore, it is impossible to expect a concentration of newspapers in one and
the same centre for all three centuries under consideration, as is the case
with London. Since regional papers have always been much more dominant in
Germany than in Britain, our focus will have to be on different centres of newspaper publishing in
Germany, such as Leipzig, Cologne, and later Berlin. Even today, 93% of the
German daily press are composed of regional newspapers (Schulz 1997: 47).
2.
2. Although
for the initial stage of corpus collection the starting point of 1700 has been
taken over from the British press, which experienced a relatively constant and
free development after the abolition of the Licensing Act in 1695, German
newspapers have been confronted with several ups and downs in their
development since 1700. They have experienced frequent changes of periods of
strict censorship (absolutist regimes, Napoleonic military administration, Nazi
regime, Communist regime in East Germany) and periods of more liberal attitudes
(Revolution of 1848, the Press Act of 1874 ['Freiheitliches
Reichspressegesetz'], and finally press freedom in post-war West Germany and,
more recently, East Germany).
3.
3. Another
factor which may have delayed the development of the distinction between
popular and quality newspapers in Germany is that industrialisation started
about 30 years later and, consequently, a large working class readership came
into existence later than in England.
Relationship
to existing German newspaper corpora
The corpus will
not only provide a basis for contrastive work, it will also fill a gap between
the two corpora of German newspapers that we are aware of: the Tübingen and the
Bonn projects. The former concentrated on 17th century German
weeklies such as the Relation
(founded in Straßburg in 1605) and Aviso
(founded in Wolfenbüttel in 1609) (cf. Fritz/Straßner 1996, Schröder 1995), the
latter was concerned with a comparison of East and West German newspapers of
the second half of the 20th century (cf. Hellmann 1992).
References
Fritz, G. and Straßner, E. (eds)
(1996) Die Sprache der ersten deutschen Wochenzeitungen
im 17. Jahrhundert. Niemeyer, Tübingen.
Hellmann, M. W. (1992) Wörter und Wortgebrauch in Ost und West. Ein
rechnergestütztes Korpus-Wörterbuch zu Zeitungstexten aus den beiden deutschen
Staaten. Die Welt und Neues Deutschland 1949-1974. Narr, Tübingen.
Sandig, B. (1971) Syntaktische Typologie der Schlagzeile. Möglichkeiten und Grenzen der
Sprachökonomie im Zeitungsdeutsch. Hueber, München.
Schneider,
K.
(2000a) Popular and quality papers in the Rostock Historical Newspaper Corpus.
In: Mair, Ch. and Hundt, M. (eds), Corpus
Linguistics and Linguistic Theory. Papers from the Twentieth International
Conference on English Language Research on Computerized Corpora (ICAME 20).
Rodopi, Amsterdam, pp. 321–37.
Schneider,
K.
(2000b), The emergence and development of headlines in British newspapers. In: Ungerer, F. (ed.) English Media Texts: Past and
Present.
Benjamins, Amsterdam, pp. 45-65.
Schröder, Th. (1995), Die ersten Zeitungen. Textgestaltung und
Nachrichtenauswahl, Narr,. Tübingen.
Schulz,
V. (1997), Medienkundliches
Handbuch. Die Zeitung, 5. aktualisierte und überarb. Neuauflage. Hahner
Verlagsgesellschaft, Aachen-Hahn.
Wölfle, L. (1943), Beiträge zu einer Geschichte der deutschen Zeitungstypographie von
1609-1938. Versuch einer Entwicklungsgeschichte des Umbruchs, Dissertation,
München.
Noëlle
Serpollet (Lancaster University, United Kingdom)
Corpus linguistics is a methodology which now uses
bilingual corpora as practical tools both to test theoretical hypotheses in
contrastive analysis and to throw light on particular translation problems.
Hence the linguistic approach is a very important aspect of translation
studies. Bilingual parallel corpora, also called translation corpora,
are defined in Baker (1995: 230) as being composed of “original source language
texts in language A and their translated version in language B”. Corpus
linguistics also uses more and more parallel synchronic or diachronic corpora
(such as LOB/Brown or LOB/FLOB) to study the possible influence of one type of
English on another (American English [henceforth AmE] on British English [BrE])
or the evolution of linguistic features.
This paper will
focus here on an area, where until recently, little contrastive analysis had
been carried out. I will analyse the particular grammatical features that are mandative
constructions, in two genres ‑ Press and Learned Prose ‑ of French
and English. Example (1) below illustrates a French mandative subjunctive and
its translation into English by a mandative construction with should:
La formidable menace que présente la prolifération nucléaire et balistique
dans le monde exige, en effet, que toutes les précautions soient prises. (Le Monde, 1993)
:: The daunting
threat of nuclear and missile proliferation in fact requires that every
possible precaution (should) be taken. (The Guardian Weekly
1993)
Example (2) provides a mandative construction with should
and a subjunctive as its French equivalent:
However, it is preferable
that these high-speed channels should,
as far as possible, be placed […]. (International
Telecommunication Union)
:: Toutefois, il est préférable que les
voies à grande rapidité de modulation soient
dans la mesure du possible, établies […]. (ITU)
The analysis of selected texts extracted from the bilingual
parallel INTERSECT corpus (Salkie 1995) will be undertaken using ParaConc, a
bilingual parallel text concordance program (Barlow 1995). The French section
was previously tagged with Cordial 6 Universités. I will first work from French
into English (Le Monde [1992-93] translated in The Guardian Weekly) and study
the English equivalents of the French subjunctive in the Press category. Then I
will go back to French and analyse the Learned Prose category of INTERSECT,
tracking the mandative constructions in English and their translations in
French.
I will check the
validity of my findings (from the English section of INTERSECT) and see how
significant they are, by comparing them with the results obtained in the
thorough analysis of extracts, equivalent in size, date and categories, of the
one-million-word corpora LOB and FLOB. The Press category is composed of
originals (FLOB) and target texts in BrE (INTERSECT). I will deal here with comparable
corpora, defined as follows in Baker’s sense (1995: 234): two separate
collections of texts in the same language A (BrE), one corpus containing
original texts in that language and the second containing translations from a
source language B (French) into the language A. The corpora are the same length
and cover the same genre(s). Hence, the possible differences in the results
could be due to the translation process. The Learned Prose category contains
originals (FLOB) and source texts in BrE (INTERSECT). Here, any difference
would be due to the data themselves as no translation process is involved.
This analysis
will enable me to describe the evolution of mandative constructions from
the 1960s to the 1990s in two genres and to see if two corpora of modern BrE
show the same trend regarding this specific grammatical feature.
The results will
show (like previous ‘corpus-based investigation of language change in progress’
(Mair & Hundt 1995): Övergaard 1995 and Hundt 1998) that the mandative
subjunctive is increasing whereas mandative should is on the
decrease. However, these studies used to some extent, non-computerized,
incomplete or incomparable corpora.
The originality of my research lies in the fact that
it involves developing complex queries in Xkwic (Christ 1994) to retrieve only
the relevant occurrences of both the modal and the subjunctive. Therefore, all
my results are totally comparable because I used exactly the same retrieving
queries on complete, grammatically tagged and computerized corpora.
Nonetheless, these findings do not answer the
following question: If the mandative subjunctive is indeed healthy in British
English, what explanation can be provided? One possible answer (suggested in
many observations on American vs. British English, see also Serpollet [2001])
would be that its health is sustained by the influence of American English.
With four carefully matched corpora now available
(thanks to the completion of the one-million-word corpora FLOB [Freiburg-LOB,
1991 – that has been used along LOB in the second part of this paper] and Frown
[Freiburg-Brown, 1992], the two 1990s counterparts of the 1960s LOB and Brown),
an exhaustive corpus-based study of language change in progress over a
thirty-year period can be conducted. This study can analyse and compare
synchronic corpora to examine for example the possible influence of American
English on British English with FLOB/Frown.
The final part of this paper will attempt to verify
the explanation mentioned above by analysing two corpora of American English:
Brown and its 1992 counterpart Frown. The analysis of American data will enable
me to see if the ongoing change in BrE is dependent of diachronic developments
in AmE or of the synchronic influence of AmE.
References
Baker,
M. (1995) Corpora in translation studies: an
overview and some suggestions for future research, Target 7(2):
223-243.
Barlow, M.
(1995) ParaConc: a Concordancer for parallel texts, Computer and Text 10:
14-16, Oxford University Press, Oxford.
Christ, O.
(1994) A modular and flexible architecture for an integrated corpus query
system, COMPLEX'94, Budapest.
Hundt, M.
(1998) It is important that this study (should) be based on the
analysis of parallel corpora: On the use of mandative subjunctive in four major
varieties of English. In Lindquist, H. et
al. (eds) The major Varieties of English,
Papers from MAVEN 97, Växjö University.
Mair,
C. and Hundt, M. (1995) Why is the progressive becoming more frequent
in English? – A corpus based investigation of language change in progress, Zeitschrift
für Anglistik und Amerikanistik 43: 123-132.
Övergaard,
G. (1995) The Mandative Subjunctive in American
and British English in the 20th Century, Stockholm, Almqvist
& Wiksell International, Acta Universitatis Upsaliensis, Studia Anglistica
Upsaliensia, Vol. 94.
Salkie,
R. (1995) INTERSECT: a parallel corpus project at
Brighton University, Computer and Texts 9: 4-5, OPU.
Serpollet,
N. (2001) The mandative subjunctive in
British English seems to be alive and kicking… Is this due to the influence of
American English? In Rayson, P., Wilson, A., McEnery, T., Hardie, A. and Khoja,
S. (eds) Proceedings of the Corpus Linguistics 2001 Conference,
(Lancaster University, 30 March-2 April 2001), Lancaster, UCREL, (Unit for
Computer Research on the English Language : technical papers, Volume13 -
Special issue).
Robert Sigley
(Daito Bunka University, Japan) & Janet Holmes (Victoria University of
Wellington, New Zealand)
Looking at girls
in English corpora
This paper uses
data from the LOB, Brown, FLOB, Frown and WWC corpora to investigate the uses
(and especially, potentially sexist uses) of the terms girl(s) and boy(s).
To the extent that language reflects and even constructs social reality,
studying representative samples of language use (i.e., corpora) provides a
useful means of tracking social change in progress. The corpora used in this
analysis allow us to follow changes in several varieties of English between
1961 and 1991.
An initial
survey shows that the overall frequencies of girl(s) and boy(s)
are lower in Frown and FLOB than in the earlier corpora. This apparent decrease
has several sources: an orthographic shift from boy(-)friend to boyfriend;
a possible shift towards use of non-gender-marking terms (the overall frequency
of child(ren)/ kid(s) shows an apparent increase); and a possible shift
away from use of both terms for adult referents.
A more detailed
breakdown of use in context shows that there has been a shift of the last type,
albeit a quantitatively small one. There is a continued asymmetry in use of girl
for adults (more than three times more likely than parallel use of boy
in all corpora), but the use of boy with adult reference has fallen from
21% in LOB to 17% in FLOB (10% in WWC), while use of girl for adults has
fallen from 61% in LOB to 51% in FLOB (38% in WWC). Use of both terms in
workplace contexts shows a similar decrease.
Inspection of
concordance data indicates that both girl and woman are used to
refer to young but sexually mature human females, with the choice between these
determined less by objective age than by a cluster of subjective connotations
including immaturity, innocence, youthful appearance, desirability, subordinate
status, domestic roles, and emotional dependence or vulnerability.
Analysis of the
collocates of the terms girl(s) and boy(s) in the corpora largely
confirms this picture, but also offers some evidence of incipient social
change. The distribution of age premodifiers for girl(s) favours young
girl, which in practice most frequently denotes an adolescent or adult,
whereas boy(s) are more closely associated with small, used for
younger children. There is also particular emphasis on describing girls’
appearance; but this imbalance is less marked in Frown and FLOB. Finally, verbs
of which girl is an object show a shift from meet, marry, love,
find, know (LOB), married (Brown) to teased (FLOB),
which appears consistent with a movement from older to younger referents, and
away from girl as an object of male desire.
Overall, our
results suggest that, unlike adult males, adult females continue to be
linguistically constructed as immature, with special emphasis on related
properties traditionally attractive to men, including a youthful appearance, a
subordinate or submissive role, and emotional dependence. The most optimistic
interpretation of our data is that there is some slight evidence of the
beginnings of a decrease in the patterns analysed. The WWC writings emerge as
more ‘socially progressive’ than FLOB, a pattern consistent with all other
sexist language variables so far compared.
Our paper
concludes with an evaluation of the strengths and weaknesses of corpus analysis
in this area of language and gender research. Corpora of writing provide a
valuable window on the usage trends received by language consumers, and may
reflect ongoing social trends; but the reflection of social change provided by
numerical analysis of published writings is a distorted one, for several
reasons.
Firstly, these
corpora are not ideally designed for sociological research. In particular,
writer gender was not controlled in constructing any of these corpora. The
apparently more feminist tendencies of the WWC data probably derive in part
from it having a larger proportion of female writers than the other corpora (to
the extent this can be estimated: e.g. it is the only one of these corpora to
have a female majority in its fiction texts) — though this in itself could
indicate social progress has been made.
Secondly, corpus
figures provide little direct attitudinal information. Sexist patterns may be
used ironically, or put into the mouths of characters by authors who may not
themselves support those usages. Many of the examples cited in this paper are
of this type. Since individual tokens may in fact be subverting an apparently
sexist usage, it is thus critically important to consider how items are used in
context.
Thirdly, in
these relatively small 1-million-word corpora a single text can have a hugely
disproportionate influence on raw frequencies and collocate lists. This could
be minimised by using larger corpora; but editorial influence and prescription
can lead to an even broader clumping of variant choices in any corpus of
writing. As a result, corpus research is necessary but not sufficient;
complementary research into actual spoken usage, and attitudes, and
prescription, is also needed.
Nicholas Smith & Geoffrey Leech
(Lancaster University, United Kingdom).
Progress Report:
Grammatical Change in Recent Written English, based on the FLOB and LOB Corpora
The focus of the
presentation will be work carried out so far on recent change in grammatical
usage in the English verb phrase, especially aspect and modality. The primary
data for the investigation are the one-million word LOB and FLOB corpora of
British English, sampled in 1961 and 1991-2 respectively.1 These data have been recently
complemented by two smaller spoken corpora, extracts from the Survey of English
Usage and ICE-GB corpora, sampled across roughly the same time period.2
As was
demonstrated in several papers at ICAME 2000, across the regional varieties of
English there have been a number of interesting shifts in overall frequency of
some of the modal auxiliaries. For example, must, shall, need and
ought to, and to a lesser extent may, might and would
have undergone significant declines. The general pattern seems to be one of a
contraction in the profile of modal verbs as a whole. This is only partly
compensated by slight increases in some of the so-called semi-modals, notably have
to and need to. Moreover, in the corresponding spoken corpora of
British English, ICE-GB-mini and SEU-mini, although the type distributions
differ somewhat, the overall directions of change are the same.
To explore this
further, we have investigated the semantic, syntactic and contextual features
of those modals whose distribution has changed the most. Adopting the semantic
categories developed in Coates 1983, it has emerged that proportional and total
frequencies of the deontic/root senses of must and may have
drastically declined, whereas with should it is the epistemic use that
has declined, while the deontic/root use has remained robust. Minority usages
in 1961, such as the quasi-subjunctive uses of may and should,
have also declined markedly. With regard to the semi-auxiliary constructions, prima
facie one of the most salient characteristics is the rise of have to.
This may be attributable to a number of factors, such as have to taking
over semantic territory from must (which, for the obligational reading,
may be felt to be more direct, authoritative, assertive etc.), the rise of
epistemic have to, or fulfilling syntactic functions not available to must
(e.g., use in past tense, or following an infinitive marker). On the other hand
the spread of have to does not occur across all genres; its rise across
LOB/FLOB is pronounced in the press genres only, whereas the fall of must
occurs across all 15 text categories. Furthermore, the rise of have to
is much more pronounced within direct speech quotations than without.
Much as been
said about the long-term historical rise of be going to to express the
future (see e.g. Mossé 1938, Visser 1973, Krug 2000). Across LOB and FLOB, however,
a continuation of this growth has not been detected. Meanwhile, the SEU and
ICE-GB data show this to be one area in which speech represents a significant
point of divergence.
In continuation
of work presented at ICAME 2000, we will also present further analysis and
discussion of changes in the English progressive construction, focussing on
present progressives and modal combinations with the progressive, as these have
been found to be the main areas of increase in the thirty year period.
Patrick
Studer & Peter Schneider (University of Zurich, Switzerland)
Classifying Newspaper Headings in the ZEN Corpus
News headings before 1800 often appear to be static
and clumsy in comparison to the informative summary headline of the 20th
century. They are frequently referred to as functional labels that neither
advertise nor summarise the content of the news. Typical examples of functional
labels are shown in (1) and (2):
(1)
(1)
Daily Advertiser Hague
Intelligence 1741CEA00179
(2)
(2)
Foreign Affairs. 1741CJL00758
But there are also more elaborate headlines, such as
(3) and (4):
(3) Now on Sale in any Quantity at Ashley Lee
& Co.: Brandy Warehouses, on Ludgate-hill, A Parcel of fine ORANGE SHRUB, 1741LDP02076
(4) On Monday, the 2nd of February,
will begin A Course of Anatomy. 1741CEA00179
Of the existing studies in news language most are
concerned with the emergence of the modern headline of the 20th century. The
present paper focuses on earlier types of headings found in the first
newspapers (between 1670 and 1800) and is part of a larger project which aims
to classify news items in the newspaper collection of the Zurich English
Newspaper Corpus.
The ZEN Corpus – a selection of the most widely read
London newspapers of the late 17th and of the 18th centuries – consists of
newspaper issues manually entered into a database. One of the central concerns
while keying in was to group individual news items together according to a set
of preliminary criteria. The criteria relevant to this first classification
were the news categories established by the editors of the newspapers
themselves. The following text types have been identified so far (in
alphabetical order): Accidents, Address, Advertisement (commercial, personal),
Announcement, Births, Crime, Deaths, Essay, Foreign news, Home news, Letter,
Lost and found, Proclamation, Review, Ship news, Weddings.
Although helpful for a first sampling of related text
types, this procedure also shows major flaws and inconsistencies. Often there
is no clear-cut dividing line between two news items, and the classification,
which mingles functional, formal, and hierarchical levels of analysis, leads to
overlapping news categories. One way to remedy the situation now is to revise
the existing classification through systematically categorising the newspaper
headings. News headings are immediately accessible dividing lines of textual
units; they signal a juncture and indicate the content of the subsequent news.
The goal of this paper, therefore, is twofold:
Firstly we wish to present plausible ways of approaching a systematic
classification of news headings in the ZEN Corpus. Secondly, we will tackle
technical problems encountered in this process of classification and present
solutions for the whole corpus.
For the former purpose a selection of newspapers from
the ZEN collection was isolated and analysed. The years used for this primary
investigation – 1701 and 1741 – include a comparable range of material. A
minimum of two sample years was selected so as to possibly cover the full
variety of different headings found in the corpus. The 40 year gap between the
two samples is to make sure the results show a diachronic development.
Following the sampling a number of features were
assigned to each heading. A fundamental distinction had to be made between
headings introducing editorial news and those heads preceding advertisements.
On the basis of this distinction each heading was further specified by a cover
term indicating the content of the news (e.g. product advertisement, etc). In a
next step additional criteria were included which cover general (graphical,
positional), structural (morphological, syntactic), and contextual (situational
and socio-historical) factors.
Whereas a general and formal classification can
easily be achieved through internal analysis of the headings, the study of
contextual factors requires knowledge of the tradition of the genre. A few
traditional text types have been identified and described so far (cf. Sandig
1972; more recently Schneider 2000). To these categories more types have been
added which – we believe – can clearly be distinguished. The analysis of
headings finally leads to establishing concepts of ‘norm’, ‘deviation’,
‘style’, and ultimately to the description of ‘house styles’ of individual
newspapers included in the ZEN collection.
In the technical part of our presentation, we will
demonstrate the use of a flat-file database program for annotating headline
features. The headlines as marked up in the original text version of the corpus
were transferred to a Filemaker database containing the preliminary set of
descriptive features.
One of the advantages of Filemaker is that it makes
it possible to change and add fields as well as descriptions without changing
the rest of the database contents. All text internal headline features were
entered as binary factors, i.e. each criterion can be thought of as an answer
to a specific yes-no question. This system allows a finely grained
characterisation of headline types. Identifying co-occurring factors (and exact
opposites) will enable the collation of factors into labels without overlapping
features. In addition to the text internal "binary" factors, a number
of interpretative features will be added. The final feature set will then be
incorporated into the corpus in XML form.
References
Sandig, B. (1971) Syntaktische Typologie der Schlagzeile. Möglichkeiten
und Grenzen der Sprachökonomie im Zeitungsdeutsch. Max Hueber Verlag,
München (Linguistische Reihe 6).
Schneider, K.
(2000) The Emergence and Development of Headlines in British Newspapers. In Ungerer,
F. (ed.) English Media
Texts Past and Present. Language and Textual Structure. John
Benjamins Publishing, Amsterdam., (Pragmatics and Beyond 80), pp. 45-65.
Irma
Taavitsainen, Päivi Pahta & Martti Mäkinen (University of Helsinki,
Finland)
Corpus of Early English Medical Writing
1375-1750
We report on progress
in compiling the Corpus of Early English Medical Writing (CEEM) and present
some of the latest results obtained in pilot studies using the corpus. Work on
the corpus was started in the Department of English at the University of
Helsinki by Irma Taavitsainen and Päivi Pahta a few years ago, with the aim of
compiling a computerised database for the project Scientific Thought-styles:
The Evolution of Early English Medical Writing. We first presented the corpus
plan in ICAME 1996, and have given papers based on corpus findings in ICAME
conferences in 1997-1999. The project is now funded by the Academy of Finland
(1999-2001), and the team has been joined by Martti Mäkinen, working on his
dissertation1, and undergraduate
students working on their Master’s theses.
The present size
of the corpus is c. 1.5 million words. The medieval part extends from 1375 to
1550 and is further divided into two subperiods (1375-1475 and 1475-1550). It
contains c. 560,000 words and is nearing completion. The text selection covers
the full range of medical texts from the first emergence of writings in this
register in English. The material contains vernacular translations of academic
tracts, surgical and anatomical treatises, texts in special fields like
ophthalmology, encyclopaedias and compendia, remedybooks and recipes, and
medical verse. Shorter texts are included in toto, and more comprehensive
treatises are represented by extracts. This part opens up new possibilities for
studying vernacularisation, the creation of a new prestige register in English,
and the processes of standardisation, to name a few central topics of interest
for linguistic studies.
Work in charting
scientific and medical writing in the early modern period has already been
carried out. The text selection for the latter part of the corpus 1550-1660 is
nearly complete; but the last subperiod (1660-1750) still needs complementing.
We aim to cover the widening use of English in medical writing in this period.
The material ranges from specialized texts and experimental reports published
in the Philosophical Transactions of the Royal Society of London to popular
health guides intended for the general audience. The widening spectrum provides
material for comparison; we have included statutory texts dealing with hygiene,
religious and moral treatises on diseases, and educational works giving
guidelines for healthy living. The conventions of scientific writing were
already established in English in this period, and it is possible to discern
various lines of development in the genres within this register of writing.
The corpus has
already been used for pilot studies by the project members, and we hope to make
a version of it publicly available with the other historical corpora compiled
in Helsinki. Copyright negotiations have been initiated for this purpose. We
have prepared a WordCruncher version, and the Corpus Presenter by Prof.
Raymond Hickey is now being tested. For more information and publications
related to the corpus and the project, see our homepage at:
http://www.eng.helsinki.fi/scientific_thoughtstyles.htm.
Elena Tognini Bonelli (Università di Lecce / The Tuscan
Word Centre, Italy)
Towards a Corpus-driven Approach
This paper presents a case, through argument and example, for the establishment
of a new discipline within linguistics, and within corpus linguistics. The
provisional name of Corpus-driven
Linguistics (CDL) is offered in order to point the contrast with what we
refer to as “corpus-based linguistics”.
It will be
argued that corpus-based work relates corpus data to existing descriptive
categories adding a probabilistic extension to theoretical parameters which are
already received, i.e. established without reference to corpus evidence. On the
other hand, corpus-driven work attempts to define the categories of description
step by step, in the presence of
specific evidence from the corpus.
The difference
between the two approaches, however, is not only methodological but also
qualitative. The corpus-driven approach at times leads the analyst to question
some of the most basic received wisdom about language, and often points to new
determining elements which have to be incorporated in the description. The
strict interrelation between grammatical and lexical choices shown up by corpus
evidence is a case in point and leads the corpus-driven analyst to postulate
new categories.
While
corpus-based work tends to focus on paradigmatic nodes, corpus-driven work
highlights the importance of syntagmatic multi-word units made up of lexical,
grammatical, semantic elements which, together, perform a specific function
within the context they operate in; at the paradigmatic level, they represent a
single choice. What emerges in corpus-driven work is a new unit of currency of
description.
The paper will
provide a theoretical discussion of the issues related to a corpus-driven
approach and will illustrate them with practical examples. It will argue for the validity of the
approach and recommend its adoption as one of the future challenges for the
discipline of corpus linguistics.
Corpus-driven linguistics
(CDL): position statement
One question we should ask ourselves is: what are the basic
requirements of a new discipline, to differentiate it from those nearby? We
will argue for the establishment of such a new discipline starting from the
assumption that these are:
• a set of goals toward which the research hopes to move, in careful
stages.
• a philosophical standpoint, an orientation to the data that is not
as well developed elsewhere.
• a unique, or at least particular methodology.
• a set of theoretical and descriptive categories for articulating
the content of the research.
• an
accumulating body of knowledge that would be difficult if not impossible to
acquire from other sources (though it may be confirmed or questioned by
alternative approaches).
These assumptions are discussed in turn and some examples
are presented to illustrate the argument.
Goals
The primary goal of CDL is to make exhaustive and explicit connections
between the occurrence and distribution of language items in text, and the
meanings created by the text. There are two principal issues here:
1. Texts are physical
objects and meanings are unobservable, so claims could be made to justify a
direct association between formal and functional elements. The safeguard here
is the intuition of the language user, who must in some sense be satisfied that
the connections offer an illuminating explanation of the way language text
creates meaning.
2. This goal is not unique,
in that every adequate theory of language might be seen to adopt an identical
goal. That does not invalidate the distinctiveness of the discipline, indeed it
confirms that it is in the mainstream of linguistics. But the precise phrasing
of the goal is not already adopted by other linguistic theories, so there are
aspects of emphasis and priority that may still serve to give CDL a distinctive
flavour.
Standpoint
CDL considers axiomatic the statement that meaning arises as much
because of the combination of choices in a text as because of the individual
contribution made by the meaning of each choice. The combinations of choices
are recognised as relevant to meaning in several areas of language patterning,
but not in the comprehensive way that is implied in the above statement.
Grammatical structure deals with combinations, and their relative sequencing,
but not the specific choices of linguistic items - only linguistic abstractions
like classes, elements of structure, etc. The study of idiom, and the recent
flowering of phraseology, are concerned with specific combinations, but idioms
are seen as occasional events, and phraseology is not tightly associated with
meaning creation.
In CDL, the approach to language patterning is holistic. Any step
away from the physical data is taken with care, and regarded as a weakening of
the description unless compensated for by much greater generalisation.
Methodology
The essential methodology of CDL is to exercise the researcher's
intuition in the presence of as much relevant data as can be assembled. It is
accepted that there is no such thing as a theory-neutral stance, but in CDL the
attempt is made to suppress all received theories, axioms and precepts and to
rely on the standpoint above to guide the initial stages of any investigation.
Obviously, as experience grows there will be new hypotheses that arise from the
investigations, and if those are generally accepted they will form part of CDL
methodology.
Specifically in the present intellectual climate, CDL does not
accept prima facie those theories, axioms and precepts that were formulated
before corpus data became available. These are not rejected or dismissed - the
accumulated insights of centuries of research are not to be put aside lightly -
but they are to be re-examined in the new frameworks where, instead of the
scholar having to struggle to gather a sufficient amount of data, (s)he has now
a plethora of data at his/her disposal.
CDL is not immediately concerned with positioning itself vis-à-vis
the tradition of theoretical and descriptive linguistics. The results of
research probes so far (e.g. Tognini Bonelli 2001) show convincingly that there
are substantial differences between the patterns that are discovered in
language corpora and those that are anticipated by the mainstream linguistic
work of the last century, and especially of the last half-century. CDL does
not, therefore, accept the agendas that are popular in other branches of
linguistics, but will pursue its own goals probably for some time, until the
theoretical position is more fully articulated and the descriptive system is
elaborated.
For some time this may seem a laborious way of working, since so
much of language structure seems to be non-contentious, but the methodology of
CDL requires different standards of attestation from other approaches, and
joins other strict sciences in expecting that all results are replicable.
Categories
As the main lines of description become clear, it is to be expected
that a descriptive apparatus will take shape in response to the descriptive
needs. Some basic categories are already postulated, clustering round the
central concept of a “functionally complete unit of meaning” (Tognini Bonelli
1996, 2001).
Body of knowledge
The awareness that there was special knowledge to be gained from a
corpus, not available from any other source, and certainly not from unaided
introspection, was the original impetus to establish CDL as a separate branch
of linguistics. This knowledge has accumulated over years in several centres,
and an ad hoc terminology has grown up around it because it could not be
described with the normal apparatus of linguistics.
Gunnel Tottie & Hans Martin
Lehmann (University of Zurich, Switzerland)
‘As’ as a relativizer after ‘same’ in Standard English
As is nowadays considered
non-standard as a relativizer when used as in (1):
(1) Well I know one person as’ll eat it. (Biber et al. 1999: 609)
However, as can be used after antecedents
containing same and such in Standard English. An instance is
shown in (2), where as is in
variation with other relativizers, that and
zero.
(2a) John always bought the same car as Mary did.
(2b) John always bought the same car that Mary did.
(2c) John always bought the same car Ø Mary did.
Notice that (3)
is ungrammatical without same:
(3) *John always bought the car as Mary did
This type of
variation has received little attention in the literature on relativization. We
intend to report on the occurrence of as
and its equivalents in current spoken and written British and American English
from BNC and the Longman Corpus, respectively, as well as in British and
American newspaper corpora from the nineteen-nineties. In this paper we will
restrict ourselves to the use of as
after same.
The corpora chosen
for this study represent both spoken and written registers of American and
British English. We chose LSAC (Longman Spoken American Corpus) and the spoken
component of BNC (from here on BNC-S) for spoken language. Written language is
represented by the 1999 issues of The
[London] Times (TLN) and The Los
Angeles Times (LATM).
Relative
constructions with same are too
infrequent for manual retrieval. For the purpose of locating these
constructions we therefore used techniques described in Lehmann (1997a; 1997b;
In press) and Tottie and Lehmann (1999). At the heart of this approach is the
search for surface patterns of word-class sequences, as this is crucial for
locating elements that are absent in the surface structure, such as zero
relativizers.
For the present study
we used the engcg-2 tagger (cf. www.conexor.fi) to annotate the corpora with
word-class information. The retrieval process used here is based on the general
patterns for relative constructions with the additional requirement that the
antecedent must begin with the same.
Since the retrieval patterns will include the whole antecedent, they will have
to implement an NP model. The one used for this study can deal with most
premodification, e.g. as in (4). Postmodification is limited to of + NP, as in (5).
(4) British television is merely seeing the
same ratings-led drift that American television went through in the 1960s. (TLN955269538)
(5) Her motionless figure and the aloof and
even tones of her voice in the scene of her summoning Siegmund to Wallhalla and
the electric change of tone in the first moment of her pity showed the same
grasp of the implications of character which has made her Isolde a thing of
exceptional power. (TLN954581415)
In terms of functions
of the relativizer the present study covers the full range from subject (6)–(8),
direct object (9)–(10), to oblique relatives as in (11)–(12). (Cf. Keenan & Comrie 1977; 1979). As a
consequence it covers the relativizers
who, whom, which, that as well as prepositional relatives with either
pied-piping or stranding, and the alternatives where when, why and the marginal how. As mentioned above this study is limited to antecedents which
start with the same.
(6) If people are gonna sit around the house
while they're unemployed, they're probably the same people who sit around the house when they're on a Saturday and Sunday
when they're working you know. (BNC:HEN)
(7) And you will probably be aware that at
the consultation draft stage, which shows the same boundaries as are in the deposit plan, […] (BNC:FNM)
(8) […]
, it is the same person who was
born in the, in the manger at Bethlehem, he is now, after having died, been
raised […] (BNC:J8Y)
(9) […] and in Maryland we had a situation
that kind of evolved into the same kind of political row Ø you would expect when a company loses
a long time business . (BNC:HE6)
(10) But our department hasn't changed, the
women are just doing the same job as they did sixty years ago. (BNC:H03)
(11) The season before that, they had the
misfortune to visit the City Ground when Nottingham Forest, languishing in the
same parlous state in which they
find themselves today, had just appointed Stuart Pearce as caretaker
manager. (TLN956399874)
(12) “…If the wind keeps on blowing from the
same direction Ø it's coming from
today, there will be some big numbers out there,” he said. (TLN953335977)
In our paper we first report on the distribution of
relativizers in spoken and written registers of British and American English. We
will also investigate factors determining relativizer selection after same, such as the syntactic
function of the relativizer and the semantics of the antecedent, subjecting
them to a variable rule analysis. A preliminary survey of the overall use of
relativizers in British English is given in Table 1. Notice the surprising
difference in the occurrence of as in spoken and written language.
Table 1.
Relativizers after same in BNC-S and The [London] Times.
|
|
BNC-S |
TLN |
||
|
|
n |
% |
n |
% |
|
as |
151 |
54% |
218 |
34% |
|
that |
91 |
33% |
214 |
33% |
|
zero |
27 |
10% |
144 |
22% |
|
who |
7 |
3% |
20 |
3% |
|
which |
5 |
2% |
37 |
6% |
|
whom |
- |
- |
2 |
|
|
where |
1 |
- |
11 |
2% |
|
when |
1 |
- |
- |
- |
|
Total |
278 |
100% |
646 |
100% |
References
Biber, D., Johansson, S., Leech, G., Conrad, S. and Finegan, E. (1999) Longman
Grammar of Spoken and Written English. Longman, Harlow.
Keenan,
E. and Bernard C. (1977)
Noun Phrase Accessibility and Universal Grammar, Linguistic Inquiry 8: 63-99.
Keenan,
E. and Bernard C.
(1979) Data on the Noun Phrase Accessibility Hierarchy, Language 55: 333-351.
Lehmann,
H. M. (1997a) Things
Nobody Can See or Hear: Automatic retrieval of Zero Elements in a computerised
Corpus. Unpublished MA Thesis. University of Zurich.
Lehmann,
H. M. (1997b)
Automatic Retrieval of Zero Elements in a Computerised Corpus. In Ljung, M. (ed.) Corpus-based
Studies in English.
Rodopi, Amsterdam, pp.
179-194.
Lehmann,
H. M. (In press) Zero
Subject Relative Constructions in American and British English. In Peters, P.
(ed.) Proceedings from ICAME 2000.
Rodopi, Amsterdam.
Tottie,
G. and Lehmann,
H. M. (1999) The Realization of Relative Adverbials in Present-day British
English. In Hasselgard, H. and Oksefjell, S. (eds). Out of Corpora. Rodopi,
Amsterdam, pp. 137-155.
Joe Trotta & Mats Johansson
(Halmstad University, Sweden)
How big of a corpus is a big enough corpus?
In the unmarked word order in English, a premodifying AdjP itself
embedded in an NP occupies a slot between the head noun and the determiner,
i.e. it is normally a string which, for the sake of simplicity, can be
abbreviated as Det + AdjP + N as in a big
problem, the industrious student, his
faithful companion, etc. In certain circumstances, however, the AdjP must
precede the determiner, resulting in a AdjP + Det + N construction:
1. a. It wasn’t that big a problem. (cf *It wasn’t a that big problem)
b.
b.
How short a time we had for our visit!) a ? (cf *A
how short time we had…)
c.
c.
He felt it wasn’t so
foolish an idea at all. (cf *He felt it wasn’t an so foolish idea…)
The unusual position of the adjectives big, short and foolish in
(1), is sometimes described as a consequence of the fact that they themselves
are modified by a so-called ‘intensifiers’ (here that, how, and so), a
combination which requires a ‘preposing’ of the AdjP to a position preceding
the determiner (see Seppänen 1978; Quirk et al. 1985: 834-835; Delsing 1993:
138-146).
However, this same word order can also be noted in another similar
construction involving how in which
the AdjP is not premodified by an ‘intensifying’ item but rather by an ordinary
interrogative (Trotta 2001: 43-45):
2. a. How
big a problem is it?
b. How
large an area did it cover?
Moreover, in addition to the structures noted in (1) and (2), there
is another variation on this string which has been generally overlooked or ignored
in descriptive grammars of English:
3. a.
How big of a problem do you
think that is? (CDC: npr/07)
b.
b. […]
then […] the causes of the anxiety and the depression er are no longer that big of a problem and the person can
handle it then. (CDC: ukspok/04)
c.
c.
I live in too big
of a house (Abney 1987: 325)
d. [… ] lets not go over how stupid of a move this was, I already know […] (online:
http://woozle.org/netforum/myjournal/a/8--13.2.1.1.1)
Given this background, the aims of the
present paper are twofold:
i) We
examine and describe the ignored variation of the AdjP + Det + N construction
exemplified in (3). We investigate its frequency in the major corpora as well
as look into its use in a selected study of internet material. Aside from the quantitative study of this
string, previous analyses of the AdjP + Det + N construction are scrutinized
and we consider the relation between the types noted in (1), (2) and (3).
ii)
ii)
With the help of our case
study, we approach some of the problems faced by the corpus linguist in dealing
with low-frequency phenomena such as: What kinds of conclusions can one draw
about the ‘naturalness’ of a construction based on it’s frequency in a
particular corpus? How does the composition of a particular corpus affect the
way a researcher views a low-frequency construction? Is the size of a corpus
the most relevant issue and if so, how big of a corpus is a big enough corpus?
References
Abney, S. (1987) The English Noun Phrase
in its Sentential Aspect. Unpublished PhD Dissertation, MIT.
Delsing,
L-O. (1993)
The Internal Structure of Noun Phrases in
the Scandinavian Languages. Department of Scandinavian Languages,
University of Lund, Lund.
Quirk, R., Greenbaum, S., Leech, G. and Svartvik,
J. (1985) A Comprehensive Grammar of
the English Language. Longman, London.
Seppänen, A. (1978) Some notes on the
construction “adjective + A + noun”,
English Studies 59: 523-537
Trotta, J. (2001) Wh-clauses in English:
Aspects of Theory and Description, Rodopi, Amsterdam & Atlanta.
Åke Viberg
(Uppsala University, Sweden)
This paper is
one in a series of papers dealing with verbs of possession from a crosslinguistic
perspective. The polysemy of the rather language-specific Swedish possession
verb få ‘get;may’ has been treated in an earlier study (Viberg,
forthcoming). This study will be concerned with two other basic verbs within
the field, namely ge ‘give’ and ta ‘take’. In addition, a brief
sketch will be made of the field of possession verbs based on the
representation in the project Swedish WordNet (related to EuroWordNet). The
analysis of give and take is based on translation corpora: a
restricted pilot corpus consisting of extracts from novels in Swedish with
translations into English, German, French and Finnish and the complete set of
occurrences of Swedish ge and ta and English give and take
in the English Swedish Parallel Corpus (ESPC) prepared by Altenberg &
Aijmer.
Intertranslatability. The Swedish possession verb få treated in an earlier study
turned out to be very language-specific with respect to its semantic
patterning. Its closest equivalent in English get was used as a
translation of only 11.7% of the 2043 occurences of få in the Swedish
original texts in the ESPC. The verbs ge/give and ta/take have
patterns of polysemy which are rather similar in Swedish and English and this
appears to reflect universal tendencies (see Newman 1996 for ‘give’). Swedish ta
and ge were both translated with their closest English equivalents (give
and take, respectively) in around 43% of the cases in the ESPC and this
is a relativly high proportion for highly frequent verbs with many meanings. In
the presentation, examples will also be given of translational equivalents of
individual meanings of these highly polysemous verbs.
Patterns of
polysemy. The basic aim of the paper is to account
for the patterns of polysemy of ‘give’ and ‘take’. Below some examples are
given of the prototypical and some of the extended meanings of ge and ta.
1. ge ‘give’
|
Swedish |
English |
German |
French |
Finnish
|
Prototypical
meaning: Possession
|
- Vi tänker ge henne eget rum. MF |
'We're
thinking of giving her a room of her own,' she went on. |
"Wir haben vor, ihr ein eigenes Zimmer zu geben. |
-Nous envisageons de lui donner une chambre individuelle. |
-Olemme ajatelleet antaa hänelle oman huoneen. |
Abstract
possession: Mental
|
De nygifta ger
intryck av burget självmedvetande: IB |
The newly weds
give the impression of well-to-do self-assurance: |
Die Frischvermählten machen den Eindruck wohlhabenden
Selbstbewußtseins: |
Les nouveaux mariés donnent une impression d'assurance aisée: |
Vastanaineista saa
mielikuvan hyvässä asemassa olevien ihmisten itsetietoisuudesta: |
Focus on source: Emergence of sense impression: Sound
|
och försökte
undvika att trampa på något som gav ljud ifrån sig.
KE |
, trying to avoid
treading on anything that might make a noise. |
und vermied tunlichst, auf etwas zu treten, was ein Geräusch machte |
en évitant instinctivement de faire du bruit ou de marcher
sur des choses qui pourraient en faire. |
ja yrittäen välttää potkaisemasta mitään mistä lähtisi ääntä. |
Subject-centered
motion
|
Mia gav
sig iväg efter samtalet. KE |
Mia left
after the conversation. |
Mia ging nach dem Gespräch. |
Mia partit après le coup de fil. |
Mia lähti heti puhelun jälkeen. |
Indirect causation (Finnish only)
|
Jag lutade mig över min dockteater, lät ridån vällustigt
höja sig /---/ IB |
I leant over
my toy theatre, letting the curtain rise voluptuously |
Ich beugte mich über mein Puppentheater, ließ den Vorhang
wollüstig /---/ hochgehen. |
Penché sur mon théâtre de poupées je laissais
voluptueusement se lever le rideau |
Minä kumarruin nukketeatterini ylle, annoin esiripun
nautinnollisesti nousta |
In the example where ge
is used in its prototypical meaning, the primary equivalent appears in all the
translations. In the various types of extended meaning, the variation is much
greater in spite of the fact that it is often possible to find parallel cases
where the primary equivalent is used. The patterns of polysemy are similar at a
general level but there are many cases of language-specific more or less
lexicalized phrasal combinations. However, certain extended meanings are
relatively language-specific at a general level. In Swedish, Subject-centered
motion is an example of this. The use of Finnish antaa ‘give’ as an
indirect causative has no parallel among the other four languages in the pilot
corpus but has parallels in several other languages (e.g. Chinese, Luo).
2. ta ‘take’
Prototypical meaning: Possession
|
Ta fyra praliner, men
se dig för, så att du inte blir ertappad. IB |
Take four chocolate creams, but mind they don't catch you'. |
Nimm vier Pralinen, aber sieh dich vor, daß man dich
nicht erwischt.” |
Prends quatre
pralines, mais fais bien attention qu'on ne te surprenne pas. |
Ota neljä karamellia,
mutta pidä varasi, ettet jää kiinni. |
Physical contact with hand
|
Han rufsade
honom i håret. Tog i honom. KE |
The man
rufffled his hair and touched him. |
Er zauste ihm durchs Haar. Faßte ihn an. |
Le gars lui ébouriffa les cheveux. Le toucha. |
Mies pörrötti hänen tukkaansa. Kosketti häntä. |
Subject-centered
motion
|
Jag hämtade mor som tagit sig till teatern genom
snöovädret. IB |
I went to
fetch my mother, who had made her way to the theatre
through the snowstorm |
Ich holte meine Mutter ab, die sich durch den Schneesturm bis zum Theater
vorgekämpft hatte. |
Je suis allé chercher ma mère qui venait d'affronter la tempête de neige
pour venir au théâtre. [COME] |
Kävin noutamassa äidin, joka oli tullut teatteriin lumimyrskyn
läpi. [COME] |
References
Newman, J. (1996) Give.
A cognitive linguistic study. Mouton de Gruyter, Berlin.
Viberg,
Å.
(forthcoming) Polysemy and disambiguation cues across languages. The case of
Swedish få and English get. To appear in: Granger, S. and
Altenberg, B. (eds) Lexis in Contrast. Benjamins, Amsterdam.
Anne Wichmann
(University of Central Lancashire, United Kingdom)
Studying
attitudinal intonation: can corpora help?
Introduction
Work on attitudinal
intonation to date has mainly been based on intuition and anecdote. This is not
in itself a problem and does not, of course, preclude a subsequent, more
quantitative approach. However, the step from intuition to large-scale corpus
studies is in the case of attitudinal intonation not so simple. First of all,
intonation patterns with 'marked' attitudinal implications are frequent.
Secondly, their identification is subjective. Thirdly, as with all discourse
phenomena, they are much harder to annotate and to search for. It may be that
this is an area where corpora simply are no longer useful, and that any
quantitative analysis will simply require a large quantity of qualitatively
analysed examples, collected fortuitously and selected by intuition. Before
conceding in this way, I should like, however, to consider ways in which
existing (and future) corpora might still offer more systematic ways of
studying the elusive phenomenon which is 'attitudinal intonation'.
What can
corpora do?
Finding
labels
Past attempts to
classify the 'attitudes' which intonation can convey has led in the literature
to a plethora of labels, both positive and negative (from rude, angry
and condescending to cheerful, friendly and comforting).
Each reference to 'attitude' brings new labels, but there is little evidence of
an underlying system. Psychologists (e.g. Scherer) and linguists
(Couper-Kuhlen, Wichmann) have attempted to bring some order to these endlessly
proliferating lists, by identifying different kinds of 'attitude' and 'affect'
in human interaction. As yet, however, no-one seems to have investigated to
what extent such labels are actually used by the participants in interaction,
and if so, which they use most frequently. I shall report the results of a
preliminary search of this kind.
Finding
'potential' speech acts
Assuming access
to a grammatically annotated corpus such as the ICE GB, it is possible to
search for certain kinds of constructions that one might expect to constitute
speech acts with the potential to convey 'attitude'. A recent example is a
study of Wh-questions in ICE GB
(Wichmann & Cauldwell 2001). Lexical searches can also reveal
certain speech acts such as thanking, apologising, requesting (see Aijmer
1996), all of which can, of course, be conveyed in a neutral way but also have
the potential to be said with a marked 'tone of voice'. Unfortunately, until
corpora are labelled pragmatically, studies of this type are restricted to what
can be achieved by indirect lexical or grammatical searches.
Finding the
'norm'
There is another
way in which corpora can guide us towards, if not point directly to, attitudes.
I have argued elsewhere (Wichmann 2000a, b) that interpersonal attitude needs
to be discussed within a pragmatic framework. To perceive a voice as 'friendly'
is to make an inference based on a combination of textual, prosodic and
contextual information. Intonational 'attitudes' are implicatures or inferences
based on available information and arise particularly when there is some kind
of mismatch between prosody and text, or prosody and context. Such a mismatch
or incongruity signals: 'do not take this at face value; seek another meaning'.
The observation
of incongruity inevitably relies on our knowledge, implicit or otherwise, of
what is congruous. This is where corpora can be of assistance - in uncovering
what is 'normal'. With this information we can then identify incongruous or
abnormal behaviour, which may then be the key to explaining perceived
'attitude'. In this way, any work which manages to uncover prosodic patterns
that reliably co-occur with certain speech acts, or in certain contexts,
contributes to the study of attitude (Aijmer 1996 is a good example).
Where corpora
fail
While current
interest in spoken language is strong, the attention paid to the primary data,
namely the sound files themselves, varies immensely. The BNC, for example, has
not made the recordings readily available. ICE GB, on the other hand, has been
innovative in aligning the sound with the text, and the Corpus of Spoken Dutch
consists of sound files and orthographic transcriptions. What we as corpus
users cannot expect any longer is to be provided with a prosodic annotation.
The painstaking work of annotating the Spoken English Corpus (SEC) or the
London-Lund Corpus (LLC) is a thing of the past. For those whose expertise lies
elsewhere, but who would like to use prosodic information in their analysis,
this is a considerable loss.
Even if it were
available, auditory prosodic analysis is not enough. Neither linguists nor the
speech community can now rely exclusively on auditory annotation. There are
important prosodic phenomena which can only be explored instrumentally,
especially global prosodic parameters such as pitch range, loudness and speech
rate. Intonational phonology also explores its categories both in terms of
meaningful auditory distinctions and in terms of their acoustic reality. This
requirement for instrumental methods of analysis has important technical
consequences for recording. However authentic the conversation, if it has been
recorded in a busy pub it is useless for instrumental analysis. The first
requirement of speech corpora is therefore that the sound should be treated as
essential primary data. This means that availability of sound files is a
pre-requisite. In addition, the sound needs to be of good enough quality for
instrumental analysis; more thought should therefore be given to ways of
collecting high-quality recordings.
Secondly, while
selection criteria that distinguish between private vs. public conversation,
scripted vs. unscripted, monologue vs. dialogue, have ensured a wide range of
speaking styles, the resulting corpora are still too homogeneous for
interesting work on prosody. The interaction represented in current corpora is
symmetrical in terms of power relationships, co-operative, and also for the
most part affectively neutral. For studying attitudinal intonation we need more
asymmetrical, uncooperative, and confrontational discourse.
The most useful
work on prosody is now being done outside the corpus linguistic community by
two very different groups: speech technologists and conversation analysts.
Conversation Analysts carry out minutely detailed work on small amounts of
data. In my view, they tend to work with a fairly atheoretical, impressionistic
view of prosody, ignoring both past and recent developments in intonational
phonology. They also work at such a level of detail that systematic
generalisations cannot be made. However, these minute observations at least
raise useful hypotheses which could in theory be tested quantitatively. Prosody
is also an important a focus of research in the speech community, with the aim
of modelling prosody for use in applications such as automatic dialogue
systems. High-quality recordings and very sophisticated analysis techniques are
used; the sophistication of the approach has furthered our knowledge not only
of intonational phonology, but also of more global prosodic characteristics of
speech which could not be identified impressionistically but which reveal how
these characteristics function in interaction. Unfortunately the kind of data
being used is extremely limited - specially elicited conversations in
laboratory conditions, mostly replicating some kind of goal-directed service
encounter.
The corpus
linguistic community could play an important role by mediating between these
two extremes - encouraging quantitative analysis but on the basis of
linguistically interesting data. As it is, corpus linguists have little to
offer those whose interest lies in the sounds of speech.
References
Aijmer, K (1996) Conversational
Routines. Longman, London.
Scherer,
KR.
(forthcoming) Psychological models of emotion. To appear in Borod, J. (ed.)
The neuropsychology of emotion. Oxford University Press, New York.
Couper-Kuhlen, E. (1986) An
Introduction to English Prosody. Arnold.
Wichmann, A. (2000a) Intonation
in Text and Discourse. Pearson Education, London.
Wichmann,
A.
(2000b) The attitudinal effects of prosody and how they relate to emotion. Proceedings
of ISCA Workshop on Speech & Emotion, Newcastle, Northern Ireland pp
143-147.
Wichmann, A. and Cauldwell, R. (2001) Wh Questions and attitude: the
effect of context. Presented at CL2001, Lancaster.
Chris Allen (University of Halmstad,
Sweden)
Causality in Modern English
This poster
reports on the initial stages of a corpus-driven study of causality in modern
English. The study builds on recent work on sublanguages and on small scale
‘local grammars’ written to parse narrowly-defined communicative functions. To
date complete or partial local grammars have been written to analyse
full-sentence dictionary definitions, evaluation, causality and duration.
Proponents of local grammars argue that existing grammatical analyses and
terminology - whether structurally or functionally-motivated - may be too
general to be useful in the parsing of such narrow communicative functions. A
local grammar in contrast can be thought of as a series of ad hoc grammatical categories designed to analyse a specific semantic
or communicative notion. Local grammar parses have the further advantage of
being more semantically transparent than their general language counterparts,
raising the prospect that they could be used in future information
retrieval/extraction applications. It is envisaged that the parsing of
unrestricted text can then be carried out using an array of individual local
grammars. On the basis of the corpus evidence being analysed I hope to be able
to identify the most significant lexicogrammatical patterns through which cause
and effect relationships are realised which can then serve as the basis for a
small scale grammar of causality at a later date.
Niek Brom, Inge
de Mönnink & Nelleke Oostdijk (University of Nijmegen, The Netherlands)
An
evaluation of the MF/MD method
Introduction
The research
conducted by Biber (1988; 1990; 1995) in which he uses the MF/MD method for the
automatic classification of texts has been criticized by a number of people, incl.
Oostdijk (1988), Altenberg (1989), and most recently Lee (2000). The criticisms
that are put forward concern various aspects of the method and the way in which
it has been applied. Among these are the size and the nature of the corpus and
the samples used, and the selection of grammatical features. It has also been
suggested that the dimensions as postulated by Biber (1990) are not as
pronounced as he claims. One of the questions that has so far remained
unanswered is the following: would it have made a difference if Biber had used
a different set of grammatical features? At the time that Biber conducted his
research, no corpora were available that had been annotated with detailed
syntactic information. Since then, however, the fully parsed ICE-GB corpus
(Nelson 1996) has become available. It is against this background that we
decided to conduct a study which aimed to clarify the issue as to whether the
data set has any effect on the results obtained in applying the MF/MD method.
In the poster presentation the results of this study are presented.
Description of the
experiments
The present
study includes three experiments. In these experiments, the set of linguistic
features is varied, while the corpus data is kept the same. The three sets of
linguistic features are as follows:
1.
1. Biber's
set of 67 variables
2.
2. a
set of 129 tags
3.
3. a
set of 103 sentence structures
The corpus which
is used is the 1-million word ICE-GB corpus. It consists of 500 texts of
approximately 2000 words each.
In the first
experiment, Biber's application of the MF/MD method as described in Biber
(1988) was copied as meticulously as possible on the ICE-GB corpus. While
making use of the syntactic annotation available in the ICE-GB corpus, every
attempt was made to stay as close as possible to Biber's 67 grammatical
features. In other words, we converted Biber's algorithms into Fuzzy Tree
Fragments. By means of this experiment we wanted to investigate whether the
classification as postulated by Biber would hold when the research was
replicated on a different corpus. In the attempt to copy the linguistic
features, some obscurities, inconsistencies and shortcomings in the algorithms
used by Biber came to light. The availability of syntactic annotation provided
the opportunity to search for most linguistic features using only one (complex)
fuzzy tree fragment and to improve on some of the original search schemes. Only
changes that improved the precision and recall of the original algorithms were
carried through.
For the second
experiment, the full set of 332 tags found in the ICE-GB corpus was reduced to
make it suitable for factor analysis. The reduction was established by ignoring
some of the word classes (e.g. pause, punc, interjec) and features (e.g. comp,
disc, procl), ignoring incomplete tags (e.g. V(ditr), N(sing)), and ignoring
all features for some major word classes (e.g. ADJ, NUM).
As input for the
third experiment we took all sentence patterns with a frequency of occurrence
of 70 or higher. To establish this set, we looked at the functions of the
daughters of the highest node in the sentence. This results in a total of 4815
different functional structures of which only 103 occur 70 times or more (with
a highest frequency of 5390 for the structure subject-verb-subject
complement).
These last two
experiments differ from the first in the fact that the set of linguistic
features is not based on previous micro-analysis. While this may complicate or even
render impossible the functional interpretation of linguistic features in terms
of an underlying dimensional structure, it has the clear advantage that no
prior research into the communicative functions of features is needed to carry
out the MF/MD analysis. If it turns out that a factor analysis on tags and/or
sentence structures still results in a meaningful text classification, this
method can be used for the automatic categorization of texts. Automatic text
categorization in turn has its applications in areas such as information
retrieval and data warehousing and in determining the representativeness of
corpus design.
Description of the results
In the first
experiment, the (normalized) frequency counts resulting from the fuzzy tree
fragments were used as input for the factor analysis. The resulting factorial
structure consists of five factors, instead of Biber's seven factors. When
comparing both factorial structures, we find some differences, but also some
striking similarities. For example, the 13 variables that have a salient
positive loading on Factor 1 in our factorial structure also load on Biber's
first factor and the variables in our Factor 3 all load on Biber's Factor 2.
Some of the differences that we found can be explained by the use of the
improved search algorithms. The feature 'wh-relative clause on subject
position', for example, was improved to include cases where the head of the
noun phrase is not realized by a common noun, or where the postmodifying
relative clause is preceded by a prepositional phrase. In Biber's calculations
this variable has a positive loading on Factor 3, while in our factorial
structure it has a high negative loading on Factor 1.
If we compare
the mean factor scores of the ICE-GB genres with Biber's scores, we find that
Biber's first dimension 'involved versus informational' is clearly reflected in
the mean scores for our Factor 1, with private and public conversations on one
end of the scale, and academic writing on the other. Biber's second dimension
'narrative versus non-narrative' is reflected in the scores for our Factor 3,
with creative writing on one end of the scale, and instructional writing on the
other. The distribution of scores for our Factor 2 are not directly reflected
in Biber's study, but it seems to make a clear distinction between spontaneous
speech on the one hand, and scripted speech and writing on the other.
The results from
our second and third experiment cannot be compared with Biber's results
directly, since we are dealing with both a different corpus and a different set
of linguistic features, but we can compare the mean factor scores for the
genres with the results of our first experiment. On doing so, we find that the
results for the set of tags are very similar to those of the first experiment.
Again, we find a distinction between involved vs. dimensional, narrative vs.
non-narrative, and written vs. spoken. While approximately the same
distinctions are found for the set of structures, the mean factor scores are
here far less distinct.
Conclusions
In the current
study Biber's classification (cf. Biber 1988) was largely reproduced, using the
same linguistic features. It was shown that the availability of syntactic annotation
simplified and improved the search for the linguistic features considerably,
effecting the classification on some points. At the same time, however, it was
shown that a factor analysis carried out on the frequency counts of only a set
of tags resulted in largely the same text categories. Assuming that the
categorization is a useful one, this would indicate that the automatic
categorization of tagged texts is feasible.
The current
study also brought to light some limiting conditions on and suggestions for the
successful implementation of the MF/MD method. With regard to the design of the
corpus, it can be concluded that the number of texts in some of the 32 genres
in ICE-GB is too small to obtain significant differences in factor scores
(using the Anova test). For a successful implementation of the MF/MD method the
number of texts per genre should be increased. Another improvement of the MF/MD
method can be found in the availability of a more accurately annotated corpus.
The syntactic analyses found in ICE-GB still show numerous mistakes and
inconsistencies. Here the use of tags as input for the factor analysis provides
a solution, since accuracy scores for tagging are much higher than for parsing.
On the whole it
can be concluded that, while Biber's factorial structure was largely
reproduced, the text classification for English is not yet stable and can still
be improved bearing in mind the findings of the present study.
References
Altenberg, B. (1989) Review of ‘Variation across
speech and writing’ by D. Biber (1988), Studia
Linguistica 43(2): 167-174.
Biber, D. (1988) Variation across speech and writing. Cambridge University Press,
Cambridge.
Biber, D. (1990) Methodological issues
regarding corpus-based analysis of linguistic variation, Literary and linguistic computing 5: 257-269.
Biber, D. (1995) Dimensions of register variation. Cambridge University Press,
Cambridge.
Lee, D. (2000) Unpublished Ph.D. Thesis. Lancaster University, Lancaster.
Nelson, G. (1996). The
Design of the Corpus. In
Greenbaum, S. (ed.), 27-35.
Oostdijk, N. (1988) A corpus linguistic approach
to linguistic variation, Literary and
linguistic computing 3: 12-25.
Andreas
Eriksson (Göteborg
University, Sweden)
Advanced Swedish Learners' Use of Tense, Mood and
Aspect in English Argumentative Writing
It remains unclear, however, why there exists such an amazing
variety of ways to express these concepts and why tense and aspect distinctions
generally constitute the most difficult part of the language system for non-native
language learners, even if the target language is genetically very close to the
native one. (Vet & Vetters 1994: 1)
The tense, mood and aspect (TMA) systems of English and Swedish are
in many respects similar and it should therefore be possible to use the same
basic framework in order to describe the systems. Despite the similarities,
however, many Swedish students have struggled with the TMA categories while
trying to improve their English. When learners reach an advanced level, they
will make fewer tense mistakes, but the system is still likely to cause
difficulties1. Problems which may
arise are, for instance, what tenses to use in a certain text type and what
tenses to use in a particular part of a text. The difficulties will probably
not be describable only in terms of misuse, but also as matters of over- and
underuse.
Aims
The first aim of the present study is to give a description of the
usage of tense, mood and aspect in argumentative essays written by advanced
Swedish learners and to compare it with the usage found in essays written by
English-speaking students. Part of this aim is thus to locate areas in the TMA
system which might cause difficulties for learners. The second aim is to
scrutinize what TMA categories are used in particular parts of a text. Thirdly,
special attention will be paid to so-called TMA shifts, e.g. shifts from the
present to the past tense, or from the past to the present perfect. The study
thus goes beyond the sentence level and views tense from a text linguistic
perspective. Granger (1999: 196-197) has pointed out that a major problem for
learners seems to be that they adopt a clause- or sentence-level approach when
selecting tenses. Furthermore, it is emphasised by Granger that tense plays an
important role in textual cohesion (Granger 1999: 198). Consequently, there
seem to be sound reasons for studying learners' and native speakers' tense
usage within the scope of text linguistics.
Material
The material is
collected from two corpora consisting of argumentative essays: the Swedish
component of the International Corpus of
Learner English (SWICLE) and the Louvain
Corpus of Native English Essays (LOCNESS). Other material will also
be used in order to see if there is any difference in terms of the use of TMA
categories between argumentative texts written by learners (both native and
non-native speakers) and professional writers.
Model for the investigation of TMA
categories
I am currently trying to work out a model
which links English and Swedish tense, mood and aspect systems, both in terms
of form and function. At this point, this work builds on a model by Nordlander
(1997), where tense, mood and aspect are seen as expressing three types of time
by means of three binary distinctions:
Factual
time - realis-irrealis: mood
Internal
time - perfective-imperfective: aspect2
External
time - anterior-non-anterior: tense
The idea is that three values, one from each
pair, are always expressed in a situation, either by explicit marking or implicitly
by the absence of marking (cf. the notion of obligatory sets in Bybee &
Dahl (1989). The difference between sentences like The Swedish people made a mistake and The Swedish people will make a mistake is one of tense and mood, since
the former is ‘realis, perfective, anterior’, whereas the other is ‘irrealis,
perfective, non-anterior’. The model makes it possible to compare what forms
learners and native-speakers use to express, e.g. irrealis mood. The importance
of this type of analysis was indicated in a minor case study carried out on
four texts from each corpus, since, in the case of conditionality, learners
more often used open conditions, while native speakers used hypothetical
conditions, as exemplified in (1) and (2):
(1) As
it is now, I think it may be a mistake if Sweden does not join
the union. (SWICLE)
(2) If a single Europe should lead
to British troops fighting on behalf of Europe instead of its own nation, most
sovereignty would be lost (LOCNESS: esee30).
The model will be elaborated in order to
capture more fine-grained distinctions, e.g. different degrees of
hypotheticality.
Another area that will be looked
into is the complexity of the verb phrase, in order to see if, as one perhaps
would expect, greater complexity is found in the texts of native speakers.
Measures of complexity are yet to be looked into, but one example of verb
phrases with high complexity are phrases containing infinitival complements as
in He is
believed to have killed the dog.
References
Bybee, J. L. and Dahl, Ö. (1989) The Creation of Tense and Aspect Systems in
the Languages of the World, Studies in
Language 13:
51-103.
Granger, S. (1999) Use of Tenses by
Advanced EFL Learners: Evidence from an Error-tagged Computer Corpus. In
Hasselgård, H. and Oksefjell, S. (eds) Out of Corpora. Studies in Honour of
Stig Johansson. Language and Computers: Studies in Practical Linguistics
26. Rodopi, Amsterdam, pp. 191-202.
Nordlander, J. (1997) Towards a Semantics of
Linguistic Time. Swedish Science Press, Uppsala.
Vet, C. and Vetters, C (eds)
(1985) Tense and Aspect in Discourse. Trends in Lingustics. Studies and
Monographs 75. Mouton de Gruyter, Berlin/New York.
Monika Hägglund (Göteborg University, Sweden)
The use of
English phrasal verbs in the (written and spoken) language of advanced Swedish
learners
General presentation
of the thesis
The aim of the
thesis is to investigate the use of English verb-particle constructions (VPCs)
in advanced Swedish learners’ written (and spoken) interlanguage. This will
include what is traditionally referred to as phrasal verbs and also
phrasal-prepositional verbs (Quirk et al. 1985).
The
written material consists of argumentative texts from the Swedish component of the
International Corpus of Learner English (SWICLE). A comparison will be made
with a native speaker norm e.g. the Louvain Corpus of Native English Essays
(LOCNESS). If time allows, the thesis will be expanded to include spoken
language e.g. from the Louvain Database of Spoken English Interlanguage
(LINDSEI)).
I am interested
in analyzing general differences between the two speaker groups as well as
register differences. Do Swedish advanced learners use different VPCs from
native speakers? Is their use appropriately adapted to the register?
Since the
Swedish learners are advanced, it is unlikely that differences can be solely
accounted for by misuse. Instead one may anticipate instances of over- and
underuse. Both over- and underuse may be due to influence from the mother
tongue since Swedish also allows for VPCs.
The fact that
both languages show this common typological characteristic does not mean that
the combinations are identical, nor does it mean that the acquisition of
English VPCs is unproblematic for Swedish learners. Previous research has shown
that Swedish learners prefer transparent combinations to opaque combinations
(Sjöholm 1995) in English, i.e. what one may refer to as prototypical usage.
The aim of the
actual analysis is to encompass both semantics and syntax. When looking at the
semantics of the VPCs a cognitive perspective might be fruitful. The general
assumption in that theoretical framework is that the meaning of these
constructions is not arbitrary. Instead the semantics can be explained by the
components, in literal as well as in metaphorical and metonymic use (Lindner
1982, Morgan 1997, Hampe 1997). In other words, a particle, such as out
can be can be metaphorically extended to encompass non-animate, non-physical
and non-spatial entities (Johnson 1987), such as to stay out of trouble or
to figure something out. This gives rise to the following question:
Extensions: Do
NNSs use the same kind of metaphoric/metonymic extensions of the particles/and
the verbs as NSs do?
Another issue
concerns the choices available to the NSs and the NNSs. While finish may
be said to compete with finish off, many VPCs have a different
one-word synonym, usually of Romance origin. Such is the case with take off
and depart, for example, which leads to the following question:
Synonyms: What
differences are there between NSs and NNSs regarding the use of VPCs vs.
potential one-word synonyms?
Other types of
variation, of a syntactic kind, which may be interesting to study from a
contrastive perspective, have to do with object placement and the possible
optionality of the particle:
Object placement: Is
there a preference for medial or final placement of the object by the two
speaker groups (in cases where there is a choice)?
Optional particles: Is
there a difference between the NSs and the NNSs concerning the use of particles
that are not part of the valency of the verb, e.g. finish off vs. finish?
On a deeper
level, the thesis aims to account for the differences and similarities between
the NS and the NNS groups, e.g. in terms of transfer, avoidance strategies and
proficiency.
References
Beate
Hampe, J. (1997) Toward a Solution of the Phrasal Verb Puzzle: Considerations on
some Scattered Pieces, Lexicology 3(2).
Berman, R.A. and Slobin, D.I.
(1994)
Relating Events in Narrative: a Crosslinguistic Developmental Study.
Lawrence Erlbaum Associates, Hillsdale.
Biber,
D., Johansson, S., Leech, G., Conrad, S. and Finegan, E.
(1999) Longman Grammar of Spoken and Written English. Longman, London.
Johnson,
M
(1987) The Body in the Mind. The Bodily Basis of Meaning, Imagination, and
Reason. University of Chicago Press, Chicago.
Lindner,
S.
(1982) What Goes Up Doesn’t Necessarily Come Down: The Ins and Outs of
Opposites, Papers from the Regional Meetings, Chicago Linguistics Society
18: 305-23.
Morgan,
P. S. (1997) Figuring Out figure out: Metaphor and the Semantics of
the English Verb-Particle Construction, Cognitive Linguistics 8:
327-57.
Sjöholm,
K.
(1995) The Influence of Crosslinguistic, Semantic and Input Factors on the
Acquisition of English Phrasal Verbs. A Comparison between Finnish and Swedish
Learners at Intermediate and Advanced Level. Åbo Academi University Press,
Åbo.
Quirk, R., Greenbaum,
S., Leech, G. and Svartvik,
J. (1985) A Comprehensive Grammar of
the English Language. Longman, London.
Tomoko
Kaneko (Showa Women’s University, Japan)
A study on LINDSEI Japanese Data
This is a report
on a pilot study on some of the Japanese data compiled for the Louvain International
Database of Spoken English Interlanguage (LINDSEI) project. Data for the
Japanese portion of LINDSEI was collected and reached its goal of 50 samples in
May 2000. We are still adding more data. One of the purposes of the study is to
find possible ways of using international corpus data like LINDSEI to
investigate learners’ interlanguage. However, to serve as a pilot study, the
present study is based only on a part of the Japanese data. While transcribing
the data, the researcher noticed that the subjects had difficulty in sustaining
the past tense frame in their speeches. The researcher wanted to know to what
extent the Japanese learners correctly used different types of past tense verb
forms and to speculate on why they could not sustain the past tense frame in
their speaking. Thus, the research questions are as follows:
1.
1. To what extent do learners use the past tense forms correctly?
2.
2. What kind of qualitative features are shown in learners’ errors in
the past tense verbs?
Thirty out of
fifty LINDSEI Japanese files were checked and tagged for obligatory context for
the past tense forms of regular, irregular, be-, and auxiliary verbs. WordSmith
analysis tool was utilized to analyse the quality and quantity of the target
language forms.
For all four
types of verbs, correct use slightly out-numbered incorrect use. The accuracy
order was 1) irregular verbs, 57.8%, 2) regular verbs, 53.2%, and 3) be-verbs
and auxiliary verbs, 50.0%, which suggests that the subjects had acquired
irregular verbs earlier than regular verbs. However, since the learners used
various types of verbs in regular verbs, while they used only limited types of
irregular verbs, the concept of accuracy order judged by obligatory context
should be questioned. Nevertheless, at the very least, the result of the
present study suggests that verbs that are simpler in form are not necessarily
easier for learners to acquire.
From the
comparison of the frequency word lists of the correct and incorrect regular
verbs, it was suggested that the learners recognized the need to mark past
tense more easily with verbs which show objective facts than with verbs which
show states of mind. The finding is similar to those of Bardovi-Harling and
Reynolds (1995), who found that learners seem to find it easier to mark past
tense when referring to completed actions than when referring to states and
activities which may last for extended periods. This kind of issue also needs
to be investigated further from a cognitive linguistic point of view. The
comparison of the frequency word list of the correct and incorrect irregular
verbs shows that the amount of input seems to be a crucial factor in the use of
the past tense forms, and that past tense seems to be marked more easily at the
beginning of a long utterance than in the middle or toward the end of the
utterance. It may be that the task to convey the meaning requires so much
concentration that the learners aren’t able to concentrate on the form that is
known to be correct. Levelt (1989) reports that in the case of native speakers,
vocabulary errors and the speakers correcting them toward the end of their
utterances are rare. This contrast between native speakers and learners also
needs to be investigated in later studies. Finally, it was suggested that one
reason for the fact that the learners had difficulty in using were, the
plural form of the be-verb, seems to relate to its pronunciation. Were
needs more effort to pronounce than was, maybe because of the increased
value of the vowel.
Cluster and
collocation lists show that learners often self-repaired their verb utterances,
especially when they didn’t have confidence in the form and/or pronunciation.
The lists also show that chunk-learning in classrooms worked well for Could
you ~ ? but didn’t work for I wanted to ~ . It is obvious from our
experience that Japanese learners rarely practise I wanted to ~ pattern
in classrooms, while they often practise Could you ~? as a form for
requesting. It is also interesting to note that past tense was marked more
easily when there was another marker of time frame in the utterance, for
example, the conjunction when. The forty-five cases of correct use of
the cluster when I was support this idea. Because of the limit of the
total number of tokens in the files, it was not possible in the present study
to find other conjunctions that seem to work as markers of time frame. This
point also needs to be studied in the future.
Despite the
small amount of data, we could gain some valuable insights into aspects of
learner language. We believe that further study using more files, especially
the comparative study using data from other language backgrounds, will give us
more insights into language acquisition by non-native learners.
References
Bardovi-Harling,
K.
and Reynolds, D. (1995) The role of lexical aspect in the acquisition of
tense and aspect, TESOL Quarterly 29(1): 107-31.
Levelt, W. J. M.
(1989) Speaking: From intention to articulation. The MIT Press, Boston.
Alexander
Kautzsch (University of Regensburg, Germany)
The changing shape of
English: non-finite verb forms
The majority
of studies of non-finite verb forms in English tend to be selective to some
extent. That is, researchers often restrict themselves to an analysis of one
non-finite verb form, e.g. the infinitive (e.g. Fischer 1997, Fanego 1992), or
the ing-form (Moessner 1997); or of
one certain syntactic function of non-finite constructions, e.g. adverbial
clauses (Ljung 1997) or verbal complementation (Los 1998). One exception is
Svartvik and Quirk (1970), who study a wide variety of functions of non-finite
clauses but restrict themselves to Chaucer. This tendency to study a certain
period or a certain author is the second type of selection frequently
encountered. Of course, these limitations are necessary to provide in-depth
analyses of the respective feature or period under scrutiny.
Nevertheless,
a more general approach might have its benefits for our understanding of the
changing shape of English and the mechanisms involved in linguistic change.
This is why the present study differs a little from common practice: it sets
out to investigate if and how the English language has changed over the last
500 years as far as the syntactic behaviour of all non-finite verb forms is
concerned.
In order to do
so, I will provide an empirical analysis of the non-finite verb forms (i.e.
plain infinitive, to-infinitive, for-to-infinitive, past participle and ing-form) of eight high frequency verbs
in English (bring, come, tell, know,
play, write, help, and drink),
based on the Helsinki, Brown, and LOB corpora. [For the selection of these
verbs I used Hofland and Johansson’s (1982) word frequencies. However, the most
frequent ones – go and make – were set aside due to their high degree
of semantic variability and change through time.]
A general
survey of the total frequencies from Old English to present-day English (PDE)
shows very interesting developments towards a more equally distributed
occurrence of non-finite verb forms. That is, it appears that the plain
infinitive heavily loses ground through time, while the to-infinitive, the past participle, and — even more so – the ing-form continually rise in frequency
from Old English to the present. As a result, in present-day English the
frequency differences between the non-finite verb forms have become smaller
than they used to be.
More detailed
analyses are capable of showing which syntactic categories are responsible for
this change in the appearance of English through time. Since, as we all know,
change usually comes after variation, it is obvious that those grammatical
environments in which one non-finite form is the (almost-)categorical one — as
for example the past participle in the passive, the ing-form in the continuous form, or the plain infinitive after
auxiliaries — should be set aside. But those contexts in which more than one
non-finite verb form is possible give interesting insights in changes though
time.
These
‘crucial’ grammatical categories are non-finites as verbal complements with and
without subject, adverbial clauses, modification, nominal clauses. It can be
shown, for example, that the to-infinitive
gains a vary large share in these contexts through time. It increases steadily
as verbal complement with subject from Old English to the present and as verbal
complement without subject from Old English to late Early Modern English, from
where it drops a little towards the present. Further, it is a frequent modifier
through time but decreases in this function after Early Modern English. In
adverbial clauses the to-infinitive
remains a relatively constant number two, while in nominal clauses it is the
almost categorical number one from Early Middle English onwards. I think this
short glimpse into the results neatly demonstrates the power of this approach.
In addition,
this presentation is the initial stage of a project that intends to document
non-finite verb forms in standard varieties of today's English. Since part of
the analysis is based on the Brown and LOB corpora, first results of
differences between American and British English — to be precise: between
written American and British English of 1961 — can already be displayed.
Similar to the overall survey, the interesting contexts are also the ones in
which non-finites appear variably. And it appears, indeed, as if American and
British English have different preferences for the usage of non-finite verb
forms. Verbal complementation by means of non-finites is just a case in point:
without subject, British English and American English tend to favour the to-infinitive and the ing-form, respectively, whereas in
complementations including a subject for the non-finite form, the results are
reversed.
On the whole,
I think this long-term approach to the development of non-finite verb forms is
a very fertile one for two reasons. First, by providing an integrated analysis
of all non-finites it becomes possible to receive an overall impression of the
changing shape of a relatively large part of the English grammar through time.
Second, on a more general level this presentation shows that it is possible to
watch syntax change. The only prerequisite is to use a corpus with a relatively
big temporal range which in this case is achieved by means of a combination of
diachronic and synchronic corpora.
References
Fanago, T. (1994) Infinitive marking in Early Modern English.
In Fernandez, F., Fuster, M. and Calvo, J. J. (eds) Historical Linguistics 1992. Benjamins, Amsterdam, pp. 191-203.
Fischer, O. (1997) Infinitive marking in Late Middle English. Transitivity and
changes in the English system of case. In Fisiak, J. and Winter, W. (eds)
(1997), pp. 109-34.
Fisiak, J. and Winter, W. (eds) (1997) Studies in Middle English Linguistics. Mouton
de Gruyter, Berlin.
Hofland, K. and Johannsson, S. (1982) Word Frequencies in British and American
English. Norwegian Computing Centre for the Humanities, Bergen.
Ljung, M. (1997) A genre-based study of English
subordinator-headed non-finite and verbless adverbial clauses. In Nevalainen, T.
and Kahlas, T-L. (eds) To Explain the
Present: Studies in the Changing English Language in Honour of Matti Rissanen.
Societe Neopholologique,
Helsinki, pp. 375-94.
Los, B. (1998) The rise of the to-infinitive as verb
complement, English Language and Linguistics
2(1): 1-36.
Moessner, L. (1997) -ing constructions in Middle English. In Fisiak, J. and
Winter, W. (eds) (1997), pp. 335-49.
Svartvik, J. and Quirk, R. (1970) Types and uses of
non-finite clauses in Chaucer, English
Studies 51: 393-411.
Mikko
Laitinen (University of Helsinki, Finland )
Extending the
Corpus of Early English Correspondence to the 18th century
The Corpus of Early English Correspondence (CEEC), reaching over almost 300 years of personal letters and
including 2.7 million words, is now being expanded. This diachronic corpus
designed by the Sociolinguistics and
Language History project at the English Department of the University of
Helsinki is being augmented to cover the 18th century as well as the
last two decades of the 17th century.
The corpus,
which now contains around 6,000 letters from almost 800 informants, and its
published sampler version (CEECS), of roughly half a million words no longer in
copyright, serve as material for the research group interested in applying
modern sociolinguistic methods to historical linguistics. The team has produced
well over 50 publications. A collection of pilot studies can be found in
Nevalainen and Raumolin-Brunberg (eds) (1996).
When completed,
the CEEC supplement will cover personal correspondence to the end of the 18th
century. The letters are selected from published collections of correspondence
often by comparing several different editions in order to provide the corpus
with accurate extralinguistic information. The supplement will be provided with
a same kind of sender database as created for the CEEC. It will give
researchers easy access to different sociolinguistic variables including the
writer's provenance, social status, sex, education, age and relationship
between the writer and the addressee. The text level and parameter coding of
the supplement will also follow those used in the CEEC.
The aim of the
team is to include letters not only from the higher social ranks of English
society but to include material written by people from all walks of life. It is
also in our interest to try to include as much material from female informants
as possible. At this stage of the compilation process it could be said that
there seems to be a large number of published collections of private
correspondence covering the 18th century. It should be noted,
however, that some writers of the period, especially literary men and women, often
addressed their letters either to a large circle of people or intended them to
be published later. Therefore, one of the challenges in the process is to find
material that fulfils the criterion of private correspondence.
The CEEC
supplement now contains two types of material. Firstly, new letter collections
have been added to the corpus to cover the last two decades of the 17th
century, since the CEEC covers the time period until 1681. In addition to that,
some of the letter collections that are already included in the corpus have
been complemented. Secondly, according to the original purpose of the
supplement, new private correspondence collections, mainly from the first half
of the 18th century, have been added to the corpus. Put together,
this means that the supplement now consists of about 350,000 words.
References
Keränen,
J.
(1998) The Corpus of Early English Correspondence: Progress Report. In Renouf,
A. (ed.) Explorations in Corpus
Linguistics. Language and Computers: Studies in Practical Linguistics 23. Rodopi, Amsterdam, pp. 29-37.
Nevalainen,
T.
and Raumolin-Brunberg, H. (eds) (1996) Sociolinguistics and Language History. Studies Based on the Corpus of Early English Correspondence. Language
and Computers: Studies in Practical Linguistics 15. Rodopi, Amsterdam.
Ilka Mindt
(Universität Würzburg, Germany)
Syntactic constituents in main clauses
This poster aims
at presenting a quantitative analysis of the frequency and the realisation of
clause elements (e.g. subject, direct object etc.) and phrases (e.g. noun
phrase, adverb phrase etc.) in ICE-GB.
Four aspects
will be dealt with:
a) the frequency of clause elements
(e.g. subject, object, adverbial);
b) the frequency of phrases (e.g.
noun phrase, adjective phrase);
c) the function of phrases (e.g. noun phrases functioning as
subjects, direct objects etc);
d) the realisation of clause elements (e.g. subjects being realised
as noun phrases and clauses)
The unit of
analysis is the top-level of sentences. In a sentence such as:
However, the important
thing is that we are having a house warming party
[...]
(w1b-004 48:1)
the top-level
taken into account for the analysis looks as follows:
|
|
However, |
the important thing |
is |
that we are having a house warming party |
|
phrase |
|
noun phrase |
verb phrase |
clause |
|
clause element |
discourse
marker |
subject |
verb |
subject
complement |
a) The frequency of clause elements
The most frequent
clause elements are: verbs, subjects, adverbials, discourse markers, direct
objects, and subject complements. These six elements account for 94.2% of all
clause elements.
b) The frequency of phrases
Clause elements
are realised by phrases or by clauses. Thus, the frequency of phrases and of
clauses functioning as clause elements is considered. Clause elements are most
frequently realised by noun phrases, verb phrases, clauses, prepositional
phrases, and adverb phrases. These five types account for 96.6% of all phrases.
c) The function of phrases
Next, the
function of phrases is considered. Each phrase is investigated independently.
The different function of phrases as clause elements will be presented.
Additionally, the relative frequency of each functional realisation is given.
Example:
Noun phrases can
function as subjects (69.7%), as direct object (18.5%), as subject complements
(8%), as adverbials (2.1%) and as other clause elements (1.7%). Each phrase
type will be dealt with in turn.
d) The realisation of clause elements
Finally, the
reverse view is taken. The focus will be on the phrasal realisation of clause
elements. Example: subjects are realised in 96.8% of all cases as noun phrases and
in 3.2% as clauses. Each clause element will be dealt with in turn.
Vladimira
Miňovská (UJEP Usti nad Labem, Czech Republic)
What have
our students learnt from ICLE?
Our students have been
contributing to the ICLE for several years. Before we started our attempts at
analysing the corpus material, the students seemed quite confident about their
essays as all they worried about was grammar. The pioneering analysts began to
discover, as it has gradually turned out, surprising facts for both the students
and the teachers.
These included the
school-born myths:
-
- a text is a good
quality text if it follows the rules of grammar and cohesion
-
- writing is a
creative activity that cannot be learnt/taught
-
- writing in a
foreign language is more or less just writing following different rules of
grammar and using (English) equivalents of Czech words
-
- students learn
to write by reading
-
- students can
write in their mother tongue.
Very little attention is
paid to writing in general in our country. Students not only feel helpless but
they are used to it and they accept it. Teachers do not feel very confident
either, and correcting students’ writing is usually to a large degree a
question of grammar only.
Student analyses have so
far covered the areas of prepositions, sentence connectors, sentence length,
writer/reader visibility, tag frequencies, punctuation, modal auxiliaries,
definite articles, passives, infinitives and participles.
Prepositions
Frequency counts based on
the Czech subcorpus (CZ) and LOCNESS suggested significant overuse of among in
CZ. One of the underused prepositions was between. These two prepositions have
only one equivalent in Czech – mezi. It seemed that speakers of Czech are not
able to apply what they learn about the use of between and among. The corpus
material revealed that the overuse was primarily caused by translating from
Czech and producing constructions that do not exist in English. The misuse was
a result of ‘correct’ application of simple rules of among/between usage
presented by textbooks and materials used in our schools.
Sentence connectors
The underused connectors in
CZ ICLE could have been easily predicted. They are the long, ‘difficult’ words
we all know, but not well enough to risk using them. Overused connectors mostly
belong to informal registers and are typical of spoken language. The student’s
conclusion that the overuse in written texts is caused by the recent obsession
with the highly misunderstood concept of communicative approaches at schools
is, probably, correct.
Sentence length
Sentence length was
compared in Spanish, French, Finnish, Dutch and Czech subcorpora and LOCNESS.
The distribution curves showed three groups. LOCNESS with the longest
sentences, the CZ subcorpus with the shortest sentences and all the other
subcorpora in the middle group. The student-researcher concluded that the
findings reflect the fact that the Czech students at the time of their essay
writing were not as advanced as students in other countries as English was
widely introduced into our schools only recently.
Writer/reader visibility
Inspired by Stephanie
Petch-Tyson (1998), who claims that the pronoun I appears in ‘chains’, the
student wrote his own simple programme to extract a map of occurrences of I in
the Czech corpus. It shows that the high frequency of the word indicates that
there are writers prone to overusing I rather than that all users use the
pronoun too extensively. His findings do not support Petch-Tyson’s conclusions
that the pronoun is connected with verbs in the past tense, often used for
recounting personal experiences. In the Czech essays past tense verbs were not
very frequent.
Tag frequencies
Existential there shows
significant overuse. As the Finnish overuse is even more prominent, it seems
that there may be used to help solve some problems of English word order to
students with highly flective mother tongues. Noun frequency brings the Czech
students nearer to imaginative, informal prose than the informative prose of
argumentative essays, which relates to a high frequency of verbs as well.
Underuse of prepositions in CZ seems a natural result of students’ avoiding
constructions where they are likely to make mistakes.
Punctuation
Czech students like all
other students, (except Finns) overuse punctuation. They tend to apply the
Czech rules – commas preceding all dependent clauses.
Verbs
The Czech subcorpus has the
verb frequencies even higher than other learner corpora, again except the
Finnish. It puts the essays even more clearly in imaginative texts. The second
reason is the fact that CZ has a higher number of sentences per 1,000 words.
Modal auxiliaries
Overuse of can and underuse
of may. A more thorough analysis would probably prove that students use can instead
of risking may in extrinsic modality. The Czech equivalent of may expresses
only intrinsic modality. Have to is slightly preferred to must. Textbooks and
popular grammars used in our country stress probably too much that must is
personal and should not be used for facts. Students know that they should avoid
personal references in essays, so they avoid must. Will and would frequencies
are different in different subcorpora. The author came to the conclusion that
the reasons relate to the frequency of the topics. CZ favourite topics are No
1,6,11, while in the French corpus No 12 seemed to be the favourite.
Definite and indefinite
articles
There are no articles in
Czech. The Czech learners use about 25% less articles than native speakers and
less articles than other non-native speakers whose languages also have no
articles. A striking gap between Finnish and Czech learners led to the question
of noun frequencies, which turned out to be very similar. The student’s
solution presents an interesting learner perspective: input. Generally our
input is very limited (all films are dubbed), while the Finns are exposed to
English every day. They do not have to rely on learning how English articles
are used but they can hear them being used.
Passives, Infinitives,
Participles
Czech students use less
passives than any other group, which supports the findings in previous chapters
about the CZ writing being less formal. With its high frequencies of
infinitives, the CZ subcorpus displays the “speech-like” quality (Granger 1998)
of our students’ writing. Czech students’ score of participle frequencies is
only a fraction better than French.
Students’ papers based on
the ICLE material have pointed out interesting facts, but first of all they
have introduced the concept of interlanguage. Interlanguage awareness
development based on the ICLE gives a new perspective to our English teacher
education courses.
Lene
Nordrum (Göteborg
University, Sweden)
Nominal and
verbal style in English, Norwegian and Swedish Expository Prose
Introduction
My thesis will
be a contrastive study of nominal and verbal style in English, Norwegian and
Swedish expository prose. Nominal style is defined by the use of long, elaborate noun
phrases and nominalizations, and verbal style by the use of coordinated or
subordinated clauses containing a finite verb. Nominal style is frequently
commented upon in studies on the difference between
spoken and written language. Here, it is emphasized that heavy use of nominal
forms (nouns, nominalizations and gerunds) is the most salient trademark of
written language, whereas a style characterized by low lexical density and a
high proportion of finite clauses is a feature of spoken language (Biber 1995,
Biber et al 1999, Chafe 1985, Halliday 1994). Moreover, in the
Longman Grammar of Spoken and Written English (Biber et al 1999), it
is found that the registers academic writing and news are
considerably more nominal than fiction and conversation.
In this
connection, it seems that register theory in Systemic Functional Grammar (SFG),
and particularly the notion of grammatical metaphor, provide a fruitful
approach to the register differences associated with nominal and verbal style.
In SFG it is claimed that the basic grammatical pattern in English is clausal
(Halliday 1994). Halliday holds that it is not until language users are capable
of expressing themselves through clauses that they are ready for the slightly
more sophisticated task of reconstruing propositional content into nominal
categories. To exemplify: a child would not say in times of engine failure,
rather he would use the clause whenever the engine fails (Halliday 1994:
353). When the content of a clause is restructured into a phrase, SFG uses the
notion grammatical metaphor. Nominalizations, then, are non-congruent
realizations of language, as opposed to their verbal counterparts which are
congruent. Halliday & Martin (1993: 238) argue that a congruent piece of
discourse consists of structures which maintain a natural relation between
semantic and grammatical categories. That is, when the child first learns his
mother tongue, he comes to the understanding that objects and things are
denoted by nouns whereas processes are denoted by verbs, and this comes to be
the logic on which he builds his grammar. A nominalization, then, is a
grammatical metaphor, since a process is naturally denoted by a verb. In
effect, grammatical metaphor provides us with a useful distinction between
nominal and verbal style, in that nominal style might be described as
non-congruent and verbal style as congruent language use.
Aims
The concept of
grammatical metaphor, then, provides me with a useful theoretical notion to
contrast nominal and verbal style in my material. The following research
questions form the foundation of the study:
- Are comparable registers in
English, Norwegian and Swedish equally nominal/verbal?
- Do nominal forms (grammatical
metaphor) have similar functions in comparable registers in English,
Norwegian and Swedish expository prose?
- If there are differences, how is
this dealt with in translations?
Regarding the
question whether comparable registers are equally nominal/verbal in the three
languages studied, a small pilot study on one English text, A History of God from Abraham to the Present
the 4000-year Quest of God by Karen Armstrong, and its Norwegian and
Swedish translations suggests that Norwegian might be less nominal than both
English and Swedish. This can be exemplified by the example below. Put in SFG
terminology, the Swedish translation (i), takes over the grammatical metaphor
in the English original, whereas the Norwegian translation (iii) renders the
grammatical metaphor the placing congruently as a verbal participle (set)
in a postmodifying non-finite clause (grammatical metaphor underlined):
(i) Non-congruent:
The placing of this incident in stark
juxtaposition to the awesome revelation (...)
(ii) Non-congruent:
Placeringen av händelsen i skarp motsättning till den
vördnadsbjudande uppenbarelsen (...)
(iii) Congruent:
Denne hendelsen stilt opp slik i skarp kontrast til den
fryktinngytende åpenbaringen (...)
[This incident set up in this manner in sharp contrast to the
awesome revelation (...)]
Also, connected
to the second research question posed above, Halliday & Martin’s (1993)
findings that grammatical metaphor serves different purposes in different text
types raise the question whether the function of grammatical metaphor across
registers is similar language-internally as well as between languages.
The texts from
the pilot study were taken from the non-fiction part of the two sister corpora,
the English-Norwegian Parallel Corpus (ENPC) and the English-Swedish Parallel
Corpus (ESPC). These corpora provide the main bulk of material for my thesis,
since they share many of the same English originals and thereby facilitate a
comparison of translated texts. Texts from the British National Corpus (BNC)
and Swedish and Norwegian monolingual corpora will be added to the material
from ENPC and ESPC. The total amount of texts included in the study remains to
be fixed.
To sum up, then,
I find that some of the theoretical assumptions made in SFG provide me with a
useful starting point for a contrastive study on nominal and verbal style in
English, Norwegian and Swedish expository prose.
References
Biber,
D.
(1995) Dimensions of Rregister variation: a Cross-linguistic Comparison.
Cambridge University Press, Cambridge.
Biber,
D., Johansson, S., Leech, G., Conrad, S., Finegan, E. (1999) Longman
Grammar of Spoken and Written English. Longman, London.
Chafe,
W
(1982) ‘Integration and Involvement in Speaking and, Writing, and Oral
Literature’. In Tannen, D. (ed.) Spoken and Written Language:
Exploring Orality and Literacy. Norwood, New York.
Halliday,
M.A.K. and Martin, J.R. (1993) Writing Science. Literacy and
Discursive Power. Falmer Press, London.
Halliday,
M.A.K. (1994) An Introduction to Funtional Grammar. 2nd
edition. Arnold, London/New York/Sydney/Auckland.
Ravelli, L.J. (1988) Grammatical
Metaphor: an Initial Analysis. In Steiner & Veltman (eds), Pragmatics,
Discourse and Text. Pinter Publishers, London.
Pam Peters & Adam Smith (Macquarie
University, Australia)
Textual structure and segmentation in online
documents
Differences between print and
online documents are increasingly commented on, as people in their millions
join the digital community. The comments are typically about lexis and grammar
-- the informality of electronic communication (especially email -- though just
which genres are being talked about is not always made clear). Some find that
this informality sabotages the norms of standard English, others embrace it as
contemporary communication (Hale 1996). Differences in the structure and
segmentation of online documents are less often commented on, except in
instructional books on how to optimise communication on-screen. There is little
objective research about common practices in digital documentation or how they
impact on readers.
The
EDOC project aims to address this fundamental gap by developing a corpus of
digital documents (i.e. ones designed in the first instance to be read on
screen), collecting two major nonfictional genres: the instructional and the
informational (or the procedural and the expository, in Longacre's 1974
taxonomy of discourse types). These two categories were selected because of
their importance in public communication, and as functions for which many feel
that electronic delivery is well suited. They are also genres which commonly
appear in printed form, and therefore readily compared on aspects such as
structure and segmentation. Computerized samples of these print-based
equivalents are already held in the Macquarie ACE and ICE corpora, and
therefore readily matched and subjected to computational analysis.
The EDOC corpus
of electronic documents contains more than 100,000 words of instructional and
of informative prose, extracted from about 100 sources, in samples whose
finished length varied (from 200 to 8,000 words). The texts, all of Australian
origin, so as to match ACE and ICE selections on that parameter, were selected
from bibliographies of online documents, and with the aid of Yahoo search categories,
limited by region. The sources were checked to ensure that they were indeed
"digitally born", not merely electronic copies of preexisting
paper-based documents. Whole texts were sampled because of our interest in
overall structure, and the very question as to what communicators thought was a
reasonable length for screen reading. The instructional texts embraced several
subcategories, including those of:
1.
1. teaching
structured information
2.
2. regulating
behavior
3.
3. constructing
something
4.
4. solving
a problem
Informational
texts were subcategorized in terms of their readerships (general and
specialized), and discourse type: as news reports, thematic or argumentative
articles, or scientific, in the broad sense.
Within this body
of data, the project aims to compare textual structure and segmentation on
several levels, using both conventional cues, such as the writer's recourse to
section and paragraph divisions, as well as the segmentation of text into lists
and individual sentences. Sentence punctuation is therefore of interest, as
well as the use of headings marked by contrasts of font and line space. The
actual font changes and spaces may of course reflect the reader's browser
settings rather than the author's selections; so here and elsewhere the
analysis is confined to those aspects of text structure which cannot be
adjusted by the browser, but are of the author's making. We can nevertheless
take advantage of whatever information is provided in HTML coding or any XML
style sheet associated with the document, as a basis for annotating the
structural and segmental features.
In pilot work to
establish the parameters of analysis, a set of four texts in each of the
categories of instructional and informational prose was analyzed in terms of
its structural components from the level of text down to sentence or
subsentence (e.g. listed item). The texts were chosen from the middle range of
length in each category, the average instructional text being about 1,200 words
long, and 2,100 words long for informational. The results except for the whole
discourse, were then compared with samples from the appropriate categories in
ACE and ICE. The hypothesis was that the documents from EDOC would be segmented
into shorter units at all structural levels. This proved to be true for the
instructional samples, but not so consistently for the academic ones, some of
which seemed to take little account of the impact of reading longish documents
on screen.
It seems that
writers-to-screen do often anticipate the finite bounds of the screen, and its
effect on screen readers. This is presumably an intuitive response, given that
there is so far relatively little received wisdom in the field.
References
Hale, C. (1996) Wired
Style (HardWired).
Longacre, R. (1974) An
anatomy of speech notions (Peter de Ridder).
Caren Sanders (University of Zurich, Switzerland)
New structural text classification patterns
in the ZEN Corpus
The ZEN Corpus (Zurich
English Newspaper Corpus) was compiled at the University of Zurich. The corpus
covers the years from 1671 to 1791 and contains a selection of early English
newspapers published in London. The project will be finished in early summer
2001 and a published version of the corpus is expected to be available in a
CD-format. The Corpus consists of about 1,500,000 words at the moment and
provides a suitable tool for analysing newspaper language of this period.
It is known from
contemporary newspapers that there are sections such as foreign or domestic
news, sports, and business classified by the publisher. However, regarding 17th
and 18th century news publications these divisions are not yet consistently
indicated, because the articles are mere flat texts, frequently starting with a
place- and dateline, followed by the news report. Additionally, the
publications are news collections rather than chronologically and
systematically ordered items.
The purpose of
the presentation is to find out more about the structures of 17th and 18th
century newspaper language. The starting point was the clear and classifiable
category of texts type advertisements. What became obvious from a very early
stage was that the term advertisement was used in a fundamentally different way
300 years ago. In those times there were advertisements for things lost and
stolen, people who had run away or were needed as well as announcements. It was
impossible to handle all of these categories at the same time, so we
concentrated exclusively on product advertising.
The next step
was to strip the ZEN Corpus and to store all advertisements and especially all
medical advertisements in a subcorpus. Medical advertisements were chosen
because there was a manageable number of them (in contrast to book
advertisements, for example,) so that we could be sure to have a clear overview
of the area of research. The medical advertisement subcorpus contains 341
advertisements which corresponds to a total of about 87,573 words; these very
specialised texts formed the beginning of our research.
The main aim was
to examine the results of the distribution of medical advertisements per
decade. The result was as expected: there are more advertisements towards the
end of the 18th century in comparison to the beginning of the 17th century.
Furthermore, the content structure and the average number of words per
advertisement were investigated. We struggled with the increase of the average
number of words per advertisement towards the end of the period of the ZEN Corpus
but found out that advertisements in German newspapers had undergone a similar
process at that time. Another point which seemed worth looking at were names of
products and also the most frequent adjectives in premodifying position which
describe medical products.
Anna-Brita
Stenström (University of Bergen, Norway)
The COLT story
Why collect a corpus of London teenage talk? One
answer to this question is that English teenage talk - and teenage language in
general - had been very little investigated at the beginning of the 1990s, and
no ‘large’ corpus of English teenage talk was available for research. A second
answer is that new trends that appear in the London teenage talk can be
expected to have a great potential for influencing not only teenage language in
general but also adult language.
From tape to CD-ROM
The compilation
of COLT (The Bergen Corpus of London Teenage Language) was modelled on that of
the BNC (The British National Corpus) in May and September 1993 and amounts to
roughly half a million words. The 13 to 17 year-old male and female recruits,
who recorded the conversations they engaged in with their peers, came from five
socially different London school districts (Barnet, Camden, Hackney, Tower
Hamlets and Hertfordshire). The tape recordings have been orthographically
transcribed and word-class tagged. Both versions are available for research on
the Internet, and a first CD-ROM version appeared early this year. Finally, a
COLT book (Trends in Teenage Talk: Corpus compilation, analysis and findings)
will, hopefully, be published by Benjamins later this year.
Main findings
Is teenage talk synonymous with ‘bad language’? That
is of course a matter of opinion, but many of the features that struck us as
typically used by the COLT teenagers are often heavily criticized by adults,
e.g. the use of slang, vague words, tags, old words with new meanings, and not
least the rich use of swearwords. A sociolinguistic comparison of some of the
findings can be summed up as follows:
§
§ Slang: the older boys and girls use more slang
than the younger ones. Overall, the boys use slang more frequently than the
girls and also more ‘dirty’ slang words. The use of slang, including dirty
slang, dominates in Tower Hamlets, which is the school borough that is lowest
on the social scale, whereas ‘proper’ slang dominates in Hertfordshire, which
is highest on the social scale
§
§ Swearing:
The boys swear more than
the girls and use more of the stronger ones (fuck, shit, bloody). Among the
boys, it is the youngest ones that swear most, compared to the older ones among
the girls. As regards school borough, swearwords are more common in Tower
Hamlets than anywhere else.
§
§ Tags:
A comparison of the use
of okay, right, yeah and innit shows that innit totally dominates speaking
followed by okay, right and yeah. With the exception of okay, the use of the
tags increases with age. With respect to gender, the boys are more frequent
users of especially yeah, while the girls use innit more often. As to school
borough, okay dominates in Camden, right in Barnet, yeah in Camden and innit in
Hackney.
More of this with illustrations on the poster.
Ann Taylor, Anthony Warner, Susan Pintzuk & Frank Beths
(University of York, United Kingdom)
The York-Helsinki Parsed Corpus of Old English
The York-Helsinki Parsed Corpus of Old English (YCOE) is a project
currently underway at the University of York to create a 1.5 million word,
part-of-speech tagged and syntactically parsed corpus of Old English. This
corpus is fully compatible with the recently released Penn-Helsinki Parsed
Corpus of Middle English, second edition (Kroch and Taylor), the York-Helsinki
Parsed Corpus of Old English Poetry (Pintzuk and Plug), and the comparable
Penn-Helsinki Parsed Corpus of Early Modern English (Kroch and Santorini)
currently being developed at the University of Pennsylvania. The end result of
these linked projects will be a coherent series of annotated electronic corpora
for the major historical periods of the English language.
The YCOE is parsed with a limited hierarchical system of labelled
parentheses. Each token consists of one main clause along with its associated
subordinate clauses bracketed and labelled according to type, and is referenced
by text, page and token number. Within the clause, words are labelled by part
of speech, and phrasal constituents are bracketed and labelled by formal type
(NP, PP, etc.) with additional functional information (such as subordinate
clause type, predicate, etc.) added in some cases. A limited number of empty
categories, such as traces of wh-movement and various types of extraposition
and scrambling, have been included to make semantic relations clear. Our goal
in designing the system was to balance the need for extensive and accurate
morphological and syntactic information with a reasonable rate of progress in
producing usable output. In addition we
have tried to avoid introducing annotations where the judgments of grammarians
are known to differ or to be unstable.
The data contained in the YCOE and its sister corpora are accessed
by means of a specially designed search engine, CorpusSearch, which
provides all matching tokens along with summary statistics in response to a
simple query. The search engine is highly customizable and even includes a
coding function, the output of which can be used as input to statistical
packages such as varbrule, SPSS, DataDesk, etc. The kinds
of data, both qualitative and quantitative, that can be extracted quickly and
easily from such corpora provide an unparalleled new resource for empirical
studies in the history of the English language.
Shunji
Yamazaki (Daito Bunka University, Japan)
Syntactic Characteristics
of Adjectives
This poster is
part of a large-scale study of adjectives and adjectival collocations in the
Wellington Corpus of Written New Zealand with the aim of comparing its
diversity with the Brown and LOB Corpora. In this poster I describe some
syntactic characteristics of adjectives in three corpora of written English
(Brown, LOB, and Wellington). The distribution across genres of attributive and
predicative adjectives differs considerably. For example, academic writings
and, within press material, reviews, show high use of attributive adjectives (I
bought a new cap the other day), whereas predicative adjectives (John
will be able to come tomorrow) are particularly frequent in
romantic fiction.
Comparing specific attributive adjectives in the three corpora
reveals distinctive differences between the corpora. A comparison of frequency
lists shows for example a higher frequency of insular or inward-looking
adjectives in Brown (American, national, local, federal, military, central,
religious), as against more international adjectives in Wellington (international,
Australian, British, French, English, foreign, European, overseas). These
findings are consistent with differences in the various countries’ political
and economic power and self-sufficiency.
Maria Teresa Prat Zagrebelsky
(University of Torino, Italy)
‘Even if’ or
‘even though’? A corpus-based investigation of the Italian-ICLE subcorpus
In the poster
the recently collected Italian component of the International Corpus of Learner
English (ICLE) will be presented and taken as the starting point for a
corpus-based investigation. Among the mistakes made by advanced Italian
learners of English the frequent confusion between even if and even
though to express hypothetical or concessive meanings respectively will be
considered. This appears to be due to interference with Italian where the same
form (anche se) can be used to
express both meanings.
In order to
explore the issue more extensively, statements will be drawn from recent
descriptions of English (e.g. Quirk et al. 1985 and Biber et al. 1999),
pedagogical grammars, various types of dictionary, native English learner
corpora (e.g. LOCNESS), English corpora, native speaker judgements, and the other
ICLE subcorpora. Comparison with these different sources of information will
show whether this confusion is a typical Italian mistake, a widespread learner
mistake or, indeed, a very subtle conceptual distinction which is gradually
disappearing in language use.
Michael Barlow (Rice University, USA)
ParaConc: A Parallel Concordancer
Bilingual or parallel
corpora provide, in effect, an accumulated store of numerous translation
choices. We can thus use aligned bilingual corpora to explore the notion of
translation equivalence and, more generally, the relationship between the
form-meaning links of one language and the form-meaning links of a second
language.
One way to extract the information inherent in such corpora is by
using a parallel concordance program such as ParaConc. Like other
concordance programs, ParaConc facilitates research into the lexical,
syntactic, and semantic patterns of a language. It differs from other programs
in that it is designed to work with parallel texts, i.e., texts in two
languages that are translations and are aligned, typically sentence by sentence
in most cases. To distinguish the two languages when necessary, I will refer to
them in the abstract as languages A and B. It is also possible to think of the
software more broadly as a way of searching parallel representations of what
might be labelled as "the same thing." For example, each tier in a
tiered linguistic representation or alternative writing representations may be
reworked as parallel texts.
For ParaConc to work correctly, the two parallel texts must
be aligned. The current version of the program does not include an aligner and
so the alignment must either be carried out manually or accomplished using a
separate program or utility. Each sentence (or segment) must either be followed
by a paragraph break (or some other special character) or be identified using
beginning and ending tags.
The use of the program typically involves the
following stages. Once the parallel texts have been loaded, the investigator
specifies a morpheme, word, or phrase (i.e. a search term) from language A (or
language B), and the program then finds and displays all the instances of the
search term. The concordance results are typically displayed in KWIC format,
i.e. with the search word in the centre of the window, along with a context of
preceding and following words. In addition, the program shows in a second,
lower window all the sentences in the second text from language B that contain
the meaning associated with the search term. Such is the general situation, but
naturally it sometimes happens that some item or some meaning in the source
text does not appear in the target text, at least not in the segment that is
displayed.
At this stage the user can click on lines of interest from language
A (possibly sorted 1st right, 1st left etc.) and observe the corresponding
lines from language B. It is also possible to search for, and highlight, words
in language B, which leads to a situation in which there are parallel search
words. In this case, the collocates of both search terms can be obtained and
sorting can be applied to language A or language B. In addition, there is a
"hot words" utility which attempts to suggest language B translations
for the language A search term.
A variety of features commonly found with monolingual concordancers
are present in ParaConc and will be demonstrated as time permits. A
history of different versions of ParaConc and access to different beta
test versions of the program is provided on the web at www.ruf.rice.edu/~barlow/parac.html.
Estelle
Dagneaux, Sylviane Granger, Fanny Meunier, Stephanie Petch-Tyson & Xavier
Vilret (Université catholique de Louvain, Belgium)
A web interface to the
International Corpus of Learner English
The International Corpus of Learner English
currently contains over 2 million words of writing by EFL learners from a
variety of mother tongue backgrounds. The corpus has the following defining
characteristics:
Ø
Ø homogeneity: it contains a well-specified type of data (academic,
mainly argumentative texts of c. 500 words each in their integral form) from
advanced EFL learners
Ø
Ø documentation: detailed information relating both to the learner and
to the task is stored alongside the texts
The corpus lends
itself to two types of research:
Ø
Ø theoretical SLA (Second Language Acquisition) research: being a very
controlled corpus, ICLE provides an ideal platform for assessing the role
played by transfer in SLA
Ø
Ø applied ELT research: ICLE provides a solid empirical foundation for
describing advanced learners' interlanguage and on that basis for producing
more focused and hence more efficient ELT tools (textbooks, grammars,
dictionaries).
The first CD-Rom version of the corpus will be available in late
2001. It will also be accessible online via a Java web interface designed both
to query and manage the database. An authentification procedure will govern
access to the system according to user’s rights. The database itself is a
relational database (powered by postgreSQL) which will assure quick response
times.
Knut Hofland
(University of Bergen, Norway)
The COLT CD-ROM
The Bergen Corpus of London Teenage Language (COLT) is the first,
and so far the only, existing corpus of English teenage language talk that is
available for research worldwide. The Corpus is now available on a set of 3
CD-ROMs with the sound files compressed as files in the MP3 format (players
available free for the most common machine platforms). A sound/text alignment
procedure now enable the corpus user to browse the text with a standard
Web-browser with hyperlinks to the sound files. It is also possible to search
the text corpus at the COLT Web-site and retrieve a search result that includes
hyperlinks to the relevant sound files (stored at the user's machine or
delivered as sound fragments through the Internet).
The corpus was collected in five different London school boroughs in
1993 and consists of roughly half a million words of spontaneous conversation
(55 hours). The conversations were recorded (surreptitiously) by student
'recruits', equipped with a Sony Walkman, a lapel microphone and a log book.
The recordings have been orthographically transcribed by trained British
transcribers and part of the material has been subjected to a simplified
prosodic analysis. The entire corpus has been tagged for word-classes by means
of the CLAWS 6 tagset developed at Lancaster University.
More information on the corpus can be found on the COLT Web-site: www.hit.uib.no/colt
Charles Meyer (University of Massachusetts,
USA)
Much of the work
that has been done in descriptive corpus linguistics has not been based on very
sophisticated statistical analysis. Instead, many of the generalizations that
have been made are based largely on frequency differences. This can lead to
disastrous results, since one has no way of knowing whether frequency differences
are statistically significant or not. The failure to use statistical tests in
corpus analysis is largely a consequence of the fact that most corpus linguists
have been trained as linguists, not as statisticians, and as a consequence have
little knowledge of the appropriate tests to use on the data they are working
with. In my software demonstration, I will show that one can easily use a
standard statistical package such as SPSS for Windows (version 10) without
knowing a lot about statistics. I will show how to code data, import it into
SPSS, do various cross tabulations, and then analyze the results with various
statistical tests, such as chi square and log likelihood tests.
Paul Rayson (Lancaster University, United Kingdom)
Wmatrix: a web-based corpus processing environment
In this software
demonstration, I will introduce Wmatrix, a web-based environment which
allows staff and students at Lancaster local and remote access to some of
UCREL's corpus annotation and retrieval tools. The web browser provides a much
simpler interface to these tools than via the UNIX command line. All processing
is done on the remote web server so users gain access from any platform that
provides a browser such as Netscape or Internet Explorer. Tools available in Wmatrix
include CLAWS (part-of-speech tagger), SEMTAG (word-sense tagger) and LEMMINGS
(a lemmatiser). Wmatrix also provides production of frequency lists,
statistical comparison of those lists, and KWIC concordances.
Wmatrix was built during REVERE (Rayson et al. 2000), a UK funded project
investigating the extraction of information from software engineering
documents. One of the aims of the project was to investigate the use of NLP
tools to aid software engineers in their understanding of a software system.
The information on the software system is contained in existing documentation
or transcripts and reports from ethnographic studies of the system being used.
We built a web-based information extraction environment by locating various
UCREL NLP tools on a web server and by providing the Wmatrix interface
to those tools. The output of the tools can be presented in a web browser from
different viewpoints depending on the role taken by the user of the system, but
this demonstration will be from the corpus linguist viewpoint. This presents
the traditional model of submitting raw data to Wmatrix, passing it
through the corpus annotation tools and then using concordances to view the
results.
A user of Wmatrix
begins by uploading their corpus to the web server via a web browser such an
Netscape Navigator or Microsoft Internet Explorer. The first corpus annotation
tool applied to the text is the hybrid part-of-speech tagger, CLAWS (Garside
and Smith 1997) which assigns a part-of-speech tag to every word in running text
with about 97% accuracy. A second layer of annotation is applied by SEMTAG, a
semantic tagger (Rayson and Wilson 1996). This tool assigns a semantic field
tag to every word in the text with about 92% accuracy. The resulting annotated
files are presented to the user in a workarea and Wmatrix prepares word,
POS and semantic tag frequency lists. These can be downloaded but can also be
browsed using the web browser application. The user can select a word or tag
from the lists and see a standard key word in context concordance for that
item. This is prepared on the fly from the corpus on the web server.
Users are guided
towards interesting words or tags to investigate further by comparing frequency
lists from their corpora to standard textual norms provided by frequency lists
produced from the British National Corpus for example.
Each user of Wmatrix
has their own set of workareas containing corpora that they have processed. Wmatrix
is designed to cope with corpora up to several million words in size, but
retrieval would be less interactive with larger corpora. A web based interface
for the Stuttgart Corpus WorkBench is available. The Corpus WorkBench (Christ
1994) pre-indexes the text and is consequently much faster at providing
concordances for large corpora. I am currently working on integrating this into
Wmatrix so that texts can be automatically indexed for CQP queries.
Acknowledgement
The REVERE project
(REVerse Engineering of Requirements) is supported under the EPSRC Systems
Engineering for Business Process Change (SEBPC) programme, project number
GR/MO4846. Further details can be found at:
http://www.comp.lancs.ac.uk/computing/research/cseg/projects/revere/
The web interface to
IMS CWB was provided by Tomaz Erjavec as used in the Slovene corpus tool at: http://nl2.ijs.si/corpus/
References
Garside, R. and Smith, N.
(1997) A Hybrid Grammatical Tagger: CLAWS4. In Garside, R., Leech, G. and
McEnery, A. (eds) Corpus Annotation: Linguistic Information from Computer
Text Corpora. Longman, London, pp. 102 - 121.
Rayson, P. and Wilson,
A. (1996) The ACAMRIT semantic tagging system: progress report. In Evett,
L. J. and Rose, T. G. (eds) Language Engineering for Document Analysis and
Recognition, LEDAR, AISB96 Workshop proceedings, pp 13-20. Brighton,
England.
Rayson, P., Garside, R. and Sawyer,
P. (2000) Assisting requirements engineering with semantic document
analysis. In Proceedings of Content-based multimedia information access RIAO
2000 (Recherche d'Informations Assistée par Ordinateur, Computer-Assisted
Information Retrieval) International Conference, Collège de France, Paris, France,
April 12-14, 2000. C.I.D., Paris, pp. 1363-1371.
Sean Wallis (University College London, United
Kingdom)
Performing scientific experiments in parsed corpora
with ICECUP 3.1
This paper will demonstrate the new version of the ICE
Corpus Utility Program, the corpus exploration program developed in conjunction
with the parsed ICE-GB corpus. ICECUP has been extended in a number of
directions. Fuzzy Tree Fragment queries1 support embedded logical expressions and text wild
cards. The corpus map overview is supplemented by a lexicon. In addition there
are major improvements in browsing results of queries.
ICECUP was initially developed as a multi-purpose
‘exploration’ platform, supporting corpus annotation. However, we have a
particular priority. Linguists require a research tool that permits them to
frame and investigate research questions based on the annotation in the corpus.
Given, say, ICE-GB and the grammar, can we test hypotheses?
The methodology must be cyclic. Parsed corpora both
permit more selective definitions of queries and tie these queries to a
particular analysis scheme. Research is both limited by a framework and
elucidative of the framework. There is a creative tension between corpus and
theory. Results are interpreted through examples in the corpus, so the tool
must support their identification and browsing. Conversely, browsing the corpus
raises questions in the mind of the researcher, including criticism of the framework
itself.
A parsed corpus permits us to create a diverse range
of structured and extensible queries. In performing research, queries are used
to specify the object of research (e.g. a particular type of verb phrase) and
to identify particular outcomes (alternative special cases of the VP). We are
concerned with questions like "how many of X are subclass x?" rather
than their absolute frequency. This permits experiments to investigate the
factors, sociolinguistic and grammatical, that correlate with the variation
between alternative versions of X.
ICECUP 3.0 does not explicitly support experiments beyond
performing queries and combining results. Nonetheless, it may be used for some
quite sophisticated experiments2. We will demonstrate new facilities in ICECUP 3.1
to support experimentation, including the construction of frequency tables and
performing statistical tests, and discuss future directions for corpus research
methods.
Martin
Wynne & Oliver Mason (University of Birmingham, United Kingdom)
TRACTOR
Demonstration
TRACTOR
is the TELRI Research Archive of Computational Tools and Resources. It features
monolingual and multilingual corpora and lexicons in a wide variety of
languages, currently including Bulgarian, Croatian, Czech, Dutch, English,
Estonian, French, German, Greek, Hungarian, Italian, Latvian, Lithuanian,
Romanian, Russian, Serbian, Slovak, Slovenian, Swedish, Turkish, Ukrainian and
Uzbek. The archive, network and user community are a key part of the TELRI
agenda to build links between the research communities in Western, Central and
Eastern Europe. Resources distributed through TRACTOR are available for
non-commercial use only, but we hope to promote and foster commercial links
between academic and industrial researchers.
TRACTOR
operates a User Community (TUC) for all those involved in creating, depositing
and using the resources. The website www.tractor.de is the hub for the TUC.
Resources can be downloaded from the website and there is a comprehensive
catalogue detailing all resources and the contact details for the resource
providers.
An
important recent acquisition for the archive is the special TRACTOR version of
the Qwick corpus analysis program which is available to the TUC with
indexed monolingual corpora in many languages.
It
is intended to greatly increase the range and depth of holdings in the TRACTOR
archive throughout 2001, as a key part of the work of the Centre for Corpus
Linguistics in the English Department at the University of Birmingham.
Particular efforts are being made to create and acquire parallel translation
corpora, which are of particular interest for research purposes for many
academic and industrial users of TRACTOR.
The
website, Qwick and some new multilingual resources will be demonstrated.
Participants at ICAME 2001 are encouraged to use the archive to distribute
their resources, and to join the user community!