La mémoire virtuelle¶
Le modèle d’interaction entre le processeur et la mémoire que nous avons utilisé jusqu’à présent est le modèle traditionnel. Dans ce modèle, illustré sur la figure ci-dessous, la mémoire est divisée en octets. Chaque octet est identifié par une adresse encodée sur \(n\) bits. Une telle mémoire peut donc contenir au maximum \(2^n\) octets de données. Aujourd’hui, les processeurs utilisent généralement des adresses sur 32 ou 64 bits. Avec des adresses sur 32 bits, la mémoire peut stocker \(4.294.967.296\) octets (4 Go) de données. Avec des adresses sur 64 bits, la capacité de stockage de la mémoire monte à \(18.446.744.073.709.551.616\) octets (16 Eo, exa-octets). Si on trouve facilement aujourd’hui des mémoires avec une capacité de \(4.294.967.296\) octets, il n’en existe pas encore qui sont capables de stocker \(18.446.744.073.709.551.616\) et il faudra probablement quelques années avant que de telles capacités ne soient utilisables en pratique.
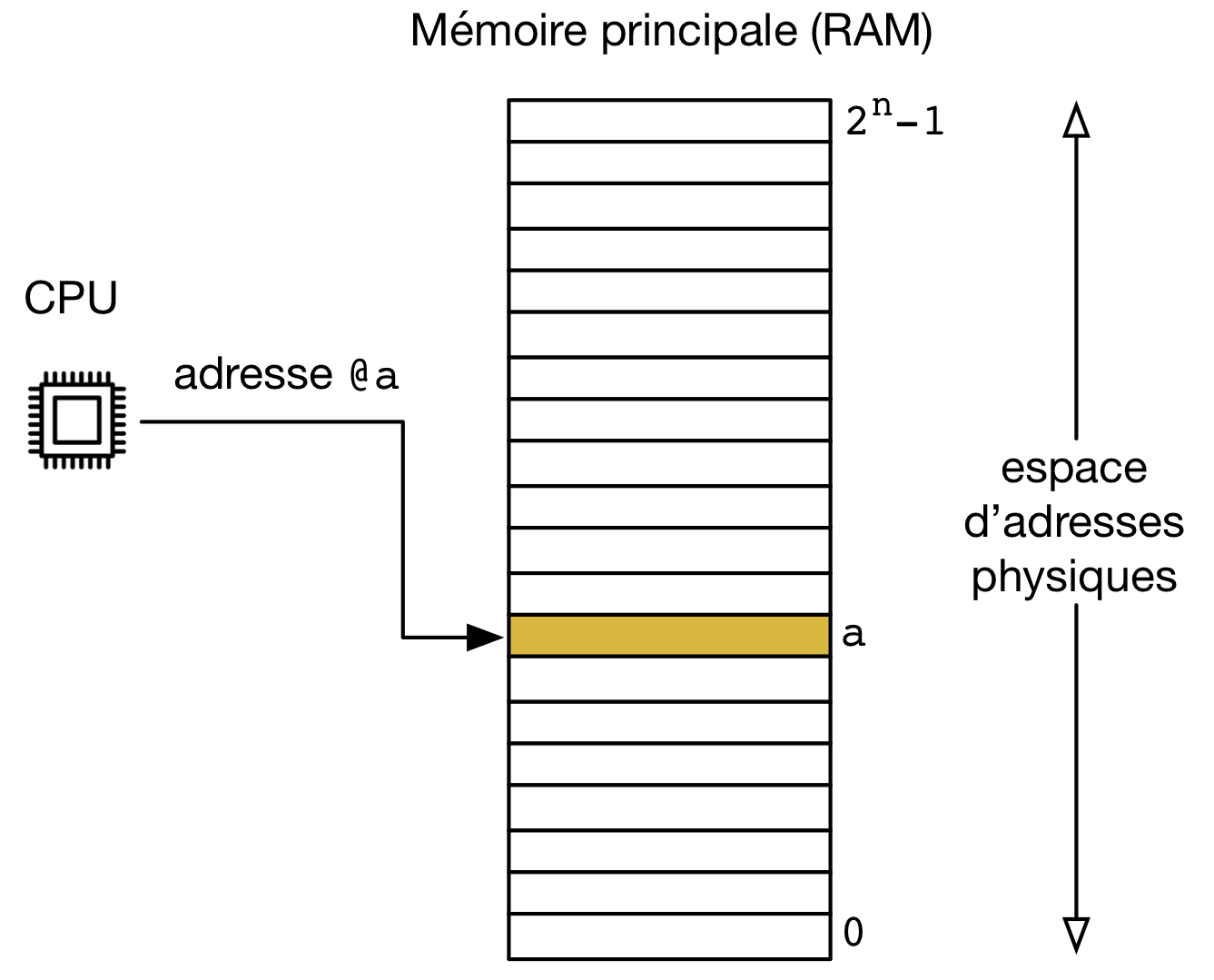
Modèle simple d’interaction entre le processeur et la mémoire
Ce modèle correspond au fonctionnement de processeurs simples tels que ceux que l’on trouve sur des systèmes embarqués comme une machine à lessiver. Malheureusement, il ne permet pas d’expliquer et de comprendre le fonctionnement des ordinateurs actuels. Pour s’en convaincre, il suffit de réfléchir à quelques problèmes liés à l’utilisation de la mémoire sur un ordinateur fonctionnant sous Unix.
Le premier problème est lié à l’organisation d’un processus en mémoire. Sous Unix, le bas de la mémoire est réservé au code, le milieu au heap et le haut au stack. Le modèle simple d’organisation de la mémoire ne permet pas facilement de comprendre comment un tel processus peut pouvoir utiliser la mémoire sur un processeur 64 bits qui est placé dans un ordinateur qui ne dispose que de 4 GBytes de mémoire. Avec une telle quantité de mémoire, le sommet de la pile devrait se trouver à une adresse proche de \(2^{32}\) et non \(2^{64}\).
Un deuxième problème est lié à l’utilisation de plusieurs processus simultanément en mémoire. Lorsque deux processus s’exécutent, ils utilisent nécessairement la même mémoire physique. Si un processus utilise l’adresse x et y place des instructions ou des données, cette adresse ne peut pas être utilisée par un autre processus. Physiquement, ces deux processus doivent utiliser des zones mémoires distinctes. Pourtant, le programme ci-dessous affiche les adresses de argc, de la fonction main et de la fonction printf de la librairie standard puis effectue sleep(20);. Lors de l’exécution de deux instances de ce programmes simultanément, on observe ceci sur la sortie standard.
$ ./simple &
[pid=32955] Adresse de argc : 0x7fff5fbfe18c
[pid=32955] Adresse de main : 0x100000e28
[pid-32955] Adresse de printf : 0x7fff8a524f3a
$ ./simple 2 3 4
[pid=32956] Adresse de argc : 0x7fff5fbfe18c
[pid=32956] Adresse de main : 0x100000e28
[pid-32956] Adresse de printf : 0x7fff8a524f3a
Manifestement, les deux programmes utilisent exactement les mêmes adresses en mémoire. Pourtant, ces deux programmes doivent nécessairement utiliser des zones mémoires différentes pour pouvoir s’exécuter correctement. Ceci est possible grâce à l’utilisation de la mémoire virtuelle. Avec la mémoire virtuelle, deux types d’adresses sont utilisées sur le système : les adresses virtuelles et les adresses réelles ou physiques. Une adresse virtuelle est une adresse qui est utilisée à l’intérieur d’un programme. Les adresses des variables ou des fonctions de notre programme d’exemple ci-dessus sont des adresses virtuelles. Une adresse physique est l’adresse qui est utilisée par des puces de RAM pour les opérations d’écriture et de lecture. Ce sont les adresses physiques qui sont échangées sur le bus auquel la mémoire est connectée. Pour que les programmes puissent accéder aux instructions et données qui se trouvent en mémoire, il est nécessaire de pouvoir traduire les adresses virtuelles en adresses physiques. C’est le rôle du MMU ou Memory Management Unit. Historiquement, le MMU était implémenté sous la forme d’un chip séparé qui était placé entre le processeur (qui utilisait alors des adresses virtuelles) et la mémoire (qui utilise elle toujours des adresses physiques). Aujourd’hui, le MMU est directement intégré au processeur pour des raisons de performance, mais conceptuellement son rôle reste essentiel comme nous allons le voir.
La mémoire virtuelle¶
Le rôle principal du MMU est de traduire toute adresse virtuelle en une adresse physique. Avant d’expliquer comment le MMU peut être mis en œuvre en pratique, il est utile de passer en revue plusieurs avantages de l’utilisation d’adresses virtuelles.
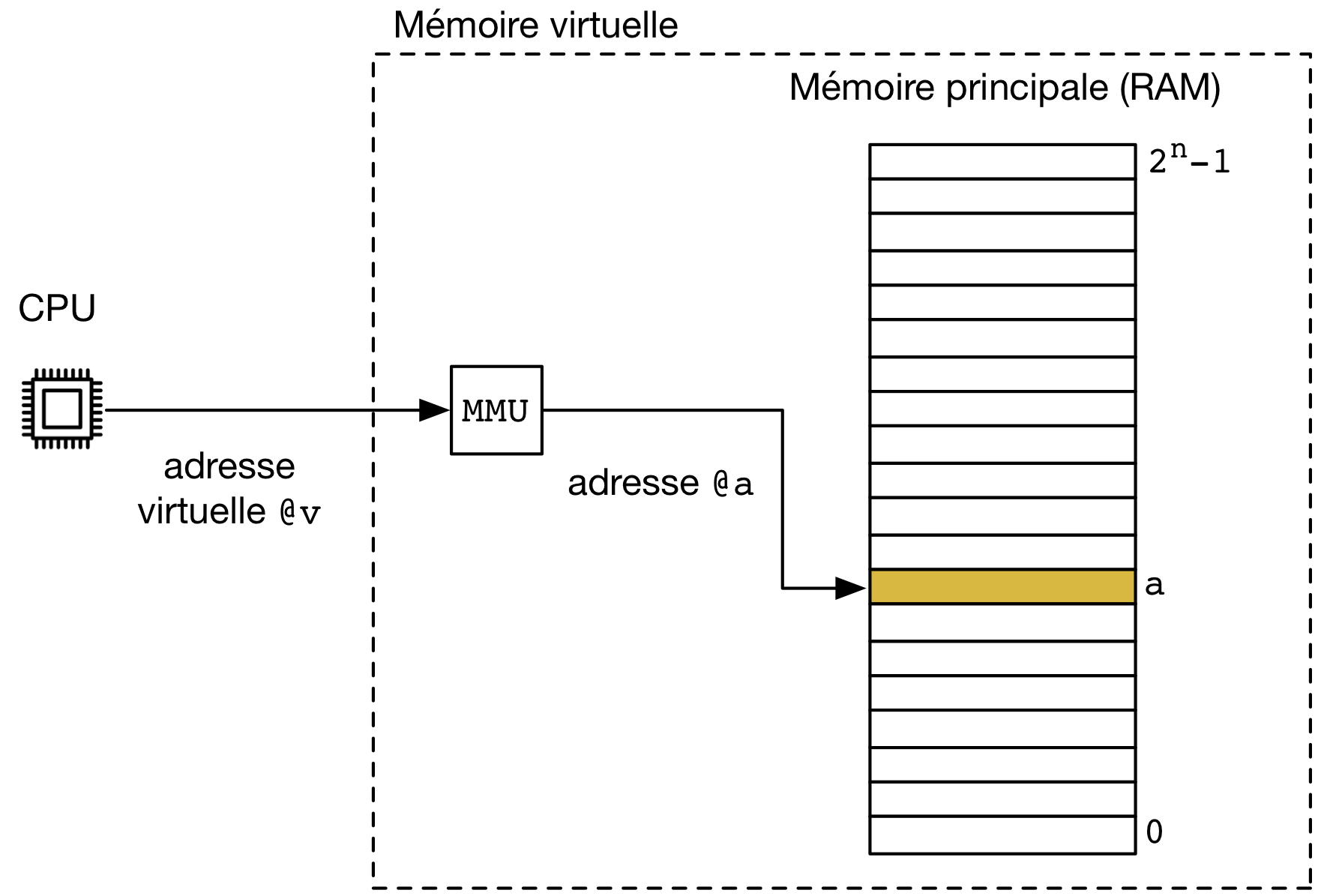
MMU et mémoire virtuelle
Un premier avantage de l’utilisation de la mémoire virtuelle est qu’elle permet de découpler les adresses virtuelles des adresses physiques. Celles-ci ne doivent pas nécessairement être encodées en utilisant le même nombre de bits. La longueur des adresses dépend généralement de l’architecture du processeur et de la taille des registres qu’il utilise. Une organisation possible de la mémoire virtuelle est d’utiliser des adresses virtuelles qui sont encodées sur autant de bits que les adresses physiques, mais ce n’est pas la seule. Il est tout à fait possible d’avoir un ordinateur sur lequel les adresses virtuelles sont plus longues que les adresses physiques. C’est le cas par exemple sur les ordinateurs bon marché qui utilisent une quantité réduite de mémoire RAM. Inversement, la mémoire virtuelle permet à un serveur d’utiliser des adresses physiques qui sont plus longues que les adresses virtuelles. Cela lui permet d’utiliser une capacité de mémoire plus importante que celle autorisée par l’architecture de son processeur. Dans ce cas, un processus ne peut pas utiliser plus de mémoire que l’espace d’adressage virtuel disponible. Mais ensemble, tous les processus fonctionnant sur l’ordinateur peuvent utiliser tout l’espace d’adressage physique disponible.
Un deuxième avantage de la mémoire virtuelle est qu’elle permet, à condition de pouvoir réaliser une traduction spécifique à chaque processus, de partager efficacement la mémoire entre plusieurs processus tout en leur permettant d’utiliser les mêmes adresses virtuelles. C’est cette particularité de la mémoire virtuelle qui nous a permis dans l’exemple précédent d’avoir deux processus qui en apparence utilisent les mêmes adresses. En effectuant une traduction spécifique à chaque processus, le MMU permet d’autres avantages qui sont encore plus intéressants.
Le MMU est capable d’effectuer des traductions d’adresses virtuelles qui sont spécifiques à chaque processus. Cela implique qu’en général la traduction de l’adresse x dans le processus P1 ne donnera pas la même adresse physique que la traduction de l’adresse x dans le processus P2. Par contre, il est tout à fait possible que la traduction de l’adresse w (resp. y) dans le processus P1 (resp. P2) donne l’adresse physique z dans les deux processus. Comme nous le verrons ultérieurement, cela permet à deux processus distincts de partager de la mémoire. Cette propriété est aussi à la base du fonctionnement des librairies partagées dans un système Unix. Dans notre exemple, la fonction printf qui est utilisée par les deux processus fait partie de la librairie standard. Celle-ci doit être chargée en mémoire lors de l’exécution de chacun des processus. Grâce à l’utilisation du MMU et de la mémoire virtuelle, une seule copie physique de la librairie standard est chargée en mémoire et tous les processus qui y font appel utilisent les instructions se trouvant dans cette copie physique. Cela permet de réduire fortement la consommation de mémoire lorsque de nombreux processus s’exécutent simultanément, ce qui est souvent le cas sur un système Unix.
Le dernier avantage de l’utilisation de la mémoire virtuelle est qu’il est possible de combiner ensemble la mémoire RAM et un ou des dispositifs de stockage tels que des disques durs ou des disques SSD pour constituer une mémoire virtuelle de plus grande capacité que la mémoire RAM disponible. Pour cela, il suffit, conceptuellement, que le MMU soit capable de supporter deux types d’adresses physiques : les adresses physiques en RAM et les adresses physiques qui correspondent à des données stockées sur un dispositif de stockage [1].

Organisation de la mémoire virtuelle
Cette possibilité de combiner la mémoire RAM et les dispositifs de stockage offre encore plus de possibilités. Comme nous le verrons, grâce à la mémoire virtuelle, un processus pourra accéder à des fichiers via des pointeurs et des écriture/lectures en mémoire. Le chargement d’un programme pourra s’effectuer en passant par la mémoire virtuelle de façon à charger uniquement les parties du programme qui sont nécessaires en mémoire. Nous verrons également qu’il existe plusieurs appels systèmes qui permettent à des processus de contrôler leur utilisation de la mémoire virtuelle.
Fonctionnement de la mémoire virtuelle¶
Avant d’analyser comment la mémoire virtuelle peut être utilisée par les processus, il est important de bien comprendre son organisation et les principes de base de fonctionnement du MMU. La mémoire virtuelle combine la mémoire RAM et les dispositifs de stockage. Comme la mémoire RAM et les dispositifs de stockage ont des caractéristiques fort différentes, il n’est pas trivial de les combiner pour donner l’illusion d’une mémoire virtuelle unique.
Au niveau de l’adressage, la mémoire RAM permet d’adresser des octets et supporte des lectures et des écritures à n’importe quelle adresse. La mémoire RAM permet au processeur d’écrire et de lire des octets ou des mots à une position déterminée en mémoire.
Un dispositif de stockage (disque dur, SSD, CD/DVD, ...) quant à lui contient un ensemble de secteurs. Chaque secteur peut être identifié par une adresse, comprenant par exemple pour un disque dur le numéro du plateau, le numéro de la piste et le numéro du secteur sur la piste. Sur un tel dispositif, le secteur est l’unité de transfert de l’information. Cela implique que la moindre lecture/écriture sur un dispositif de stockage nécessite la lecture/écriture d’au moins 512 octets, même pour lire ou modifier un seul bit. Enfin, la dernière différence importante entre ces deux technologies est leur temps d’accès. Au niveau des mémoires RAM, les temps d’accès sont de l’ordre de quelques dizaines de nanosecondes. Pour un dispositif de stockage, les temps d’accès peuvent être de quelques dizaines de microsecondes pour un dispositif de type Solid State Drive ou SSD et jusqu’à quelques dizaines de millisecondes pour un disque dur. .. Les tableaux ci-dessous présentent les caractéristiques techniques de deux dispositifs de stockage [3] [4] à titre d’exemple.
La mémoire virtuelle utilise elle une unité intermédiaire qui est la page. Une page est une zone de mémoire contigüe. La taille des pages dépend de l’architecture du processeur et/ou du système d’exploitation utilisé. Une taille courante est de 4096 octets. L’appel getpagesize(2) permet d’obtenir la taille de page utilisée dans un système, comme montré dans l’exemple qui suit.
#include <unistd.h>
int sz = getpagesize();
Lorsqu’un programme est chargé en mémoire, par exemple lors de l’exécution de l’appel système execve(2), il occupe un nombre entier de pages (par exemple, si le segment text du programme contient 5192 octets, le segment text occupera deux pages, dont une partie de la deuxième page sera inutilisée). Grâce à la mémoire virtuelle, ces pages peuvent être stockée dans n’importe quelle zone de la mémoire RAM. La seule contrainte est que tous les octets qui font partie de la même page soient stockés à des adresses qui sont contigües. Cette contrainte permet de structurer les adresses virtuelles en deux parties comme représenté dans la figure ci-dessous. Une adresse virtuelle est donc un ensemble de bits. Les bits de poids fort servent à identifier la page dans laquelle une donnée est stockée. Les bits de poids faible (12 lorsque l’on utilise des pages de 4 KBytes) identifient la position de la donnée par rapport au début de la page.
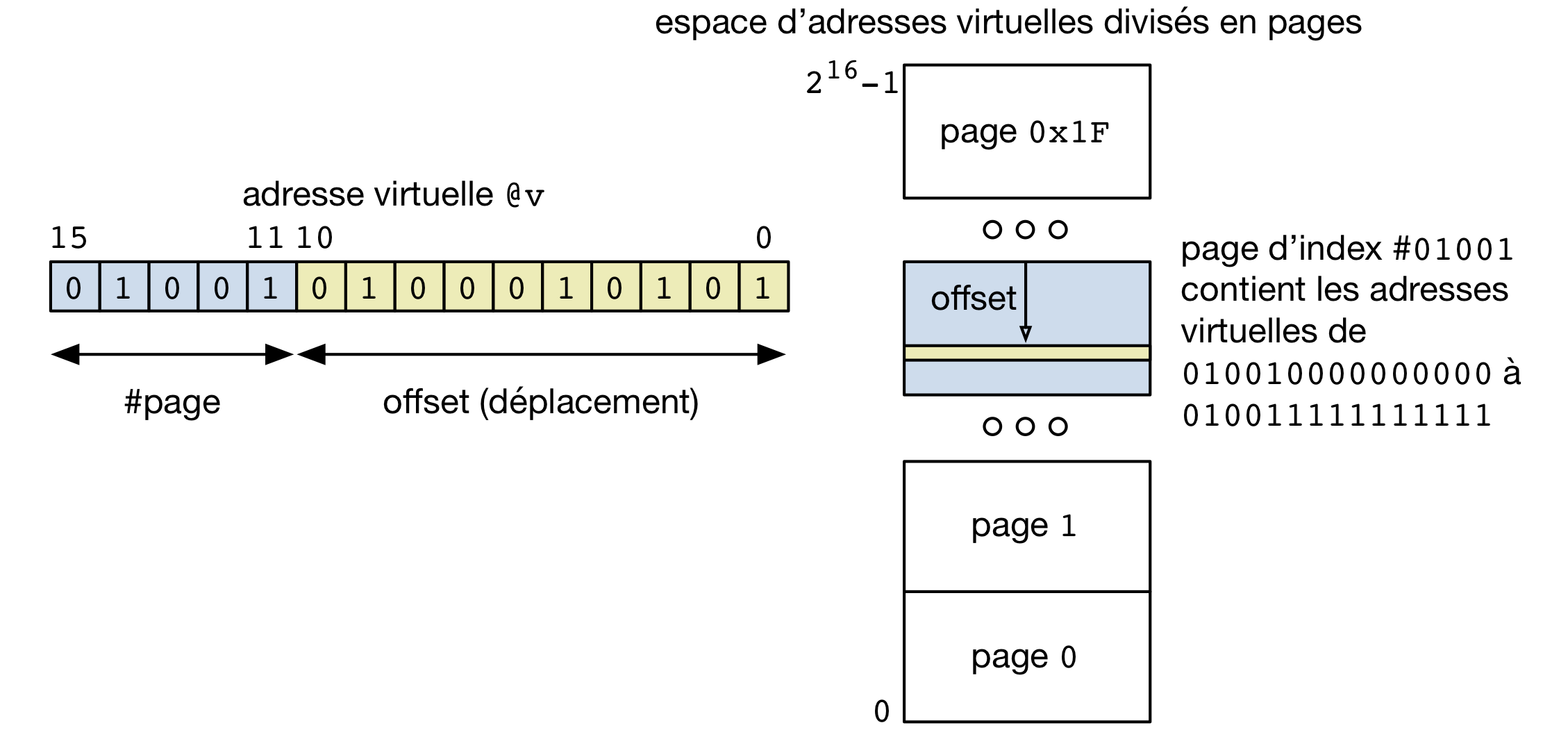
Adresse virtuelle
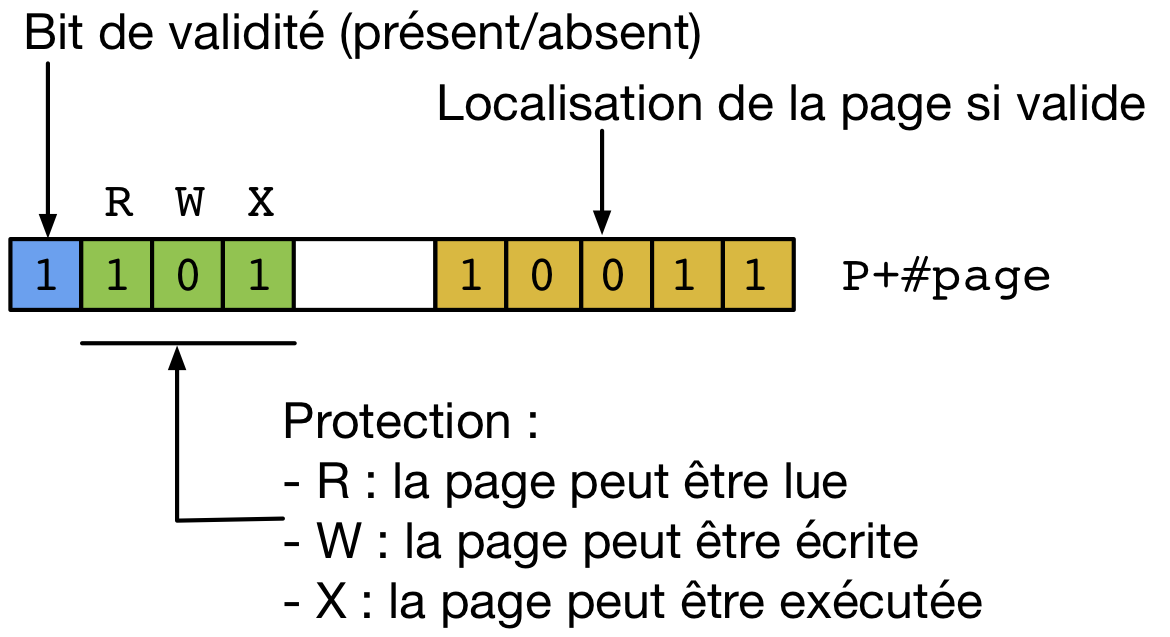
Grâce à cette organisation des adresses virtuelles, il est possible de construire un mécanisme efficace qui permet de traduire une adresse virtuelle en une adresse réelle. La première solution qui a été proposée pour réaliser cette traduction est d’utiliser une table des pages. La table des pages est stockée en mémoire RAM et contient une ligne pour chaque page appartenant à la mémoire virtuelle. À titre d’exemple, un système utilisant des adresses virtuelles de 32 bits et des pages de 4 KBytes contient \(2^{32-12}=2^{20}\) pages. La table des pages de ce système contient donc \(2^{20}\) lignes. Une ligne de la table des pages contient différentes informations que nous détaillerons par après. Les deux plus importantes sont :
- le bit de validité qui indique si la page est actuellement présente en mémoire physique (RAM) ou non,
- l’adresse en mémoire RAM à laquelle la page est actuellement stockée (si elle est présente en mémoire RAM, sinon une information permettant de trouver la page sur un dispositif de stockage)
La table des page est stockée en mémoire RAM comme un tableau en C. L’information correspondant à la page 0 est stockée à l’adresse de début de la table des pages. Cette adresse de début de la table des pages (P) est généralement stockée dans un registre du processeur pour être facilement accessible. Si une entrée [5] de la table des pages est encodée en n bytes, l’information correspondant à la page 1 sera stockée à l’adresse P+n, celle relative à la page 2 à l’adresse P+2*n, ... Cette organisation permet d’accéder facilement à l’entrée de la table des pages relative à la page z. Il suffit en effet d’y accéder à l’adresse P+z*n.
Grâce à cette table des pages, il est possible de traduire directement les adresses virtuelles en adresses physiques. Cette traduction est représentée dans la figure ci-dessous. Pour réaliser une traduction, il faut tout d’abord extraire de l’adresse virtuelle le numéro de la page. Celui-ci se trouve dans les bits de poids fort de l’adresse virtuelle. Le numéro de la page sert d’index pour récupérer l’entrée correspondant à cette page dans la table des pages. Cette entrée contient l’adresse en mémoire RAM à laquelle la page débute. Pour finaliser la traduction de l’adresse virtuelle, il suffit de concaténer les bits de poids faible de l’adresse virtuelle avec l’adresse de la page en mémoire RAM. Cette concaténation donne l’adresse réelle à laquelle la donnée est stockée en mémoire RAM. Cette adresse physique permet au processeur d’accéder directement à la donnée en mémoire.
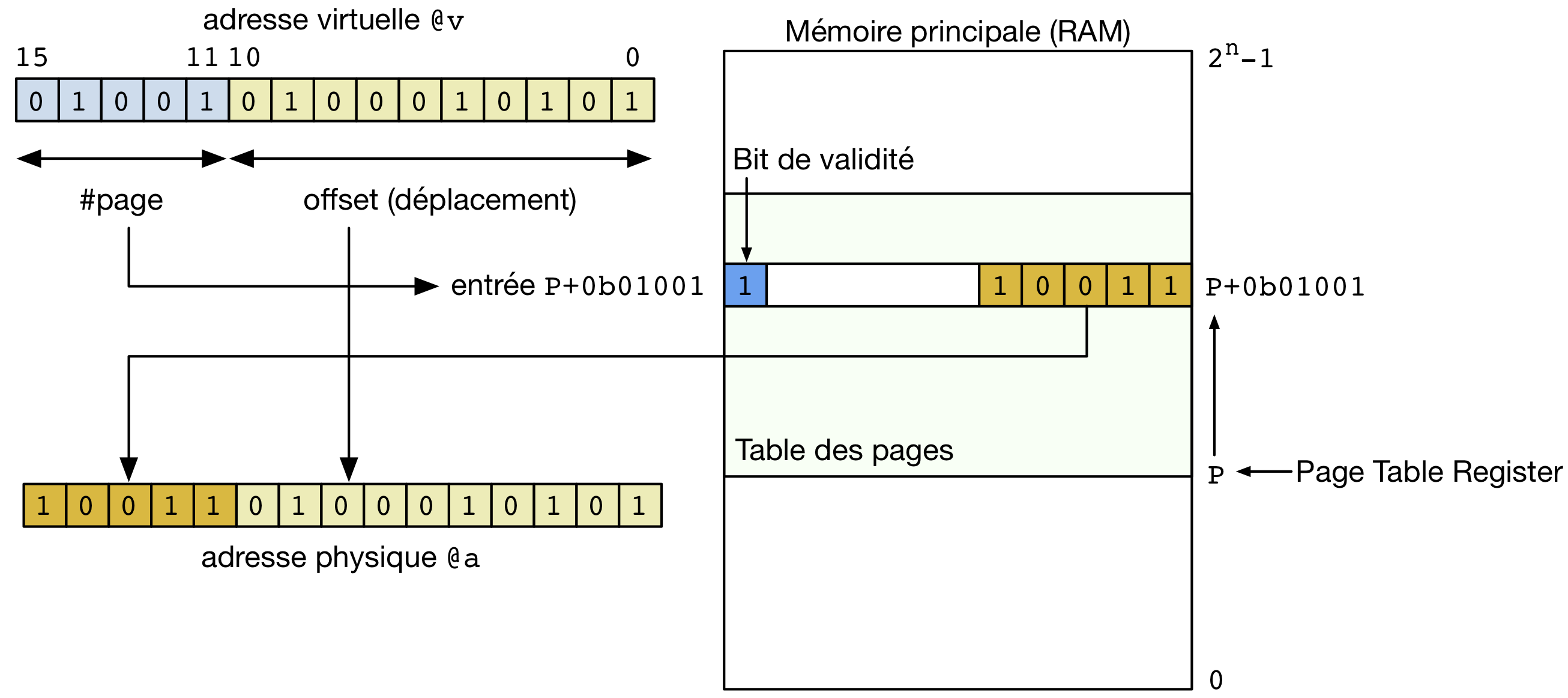
Traduction d’adresses avec une table des pages
La table des pages permet de traduire les adresses virtuelles en adresses physiques. Ce faisant, elle introduit un mécanisme d’indirection entre les adresses (virtuelles) qui sont utilisées par les programmes et les adresses (réelles) qui sont utilisées par le hardware. Ce mécanisme d’indirection a de nombreuses applications comme nous le verrons par la suite.
Un point important à mentionner concernant l’utilisation d’un mécanisme de traduction des adresses est qu’il permet de découpler le choix de la taille des adresses (virtuelles) utilisées par les programmes des contraintes matérielles qui sont liées directement aux mémoires RAM utilisées. En pratique, il est tout à fait possible d’avoir des systèmes informatiques dans lesquels les adresses virtuelles sont plus longues, plus courtes ou ont la même longueur que les adresses physiques. Sur un ordinateur utilisant des adresses en 32 bits et équipé de 4 GBytes de mémoire, il est naturel d’utiliser des adresses virtuelles de 32 bits et des adresses physiques de 32 bits également pour pouvoir accéder à l’ensemble de la mémoire. Dans ce cas, la mémoire virtuelle permet d’accéder à toute la mémoire physique. Aujourd’hui, la majorité des ordinateurs de bureau et des serveurs utilisent des adresses sur 64 bits. Ceux-ci utilisent des adresses virtuelles de 64 bits, mais aucun ordinateur ne contient 2^64 bytes de mémoire. Par exemple, un serveur disposant de 128 GBytes de mémoire physique pourrait se contenter d’utiliser des adresses physiques de 37 bits. Dans ce cas, la mémoire virtuelle donne l’illusion qu’il est possible d’accéder à plus de mémoire que celle qui est réellement disponible. D’un autre côté, il est aussi possible de construire des serveurs qui utilisent des adresses virtuelles de 32 bits, mais disposent de plus de 4 GBytes de mémoire RAM. Dans ce cas, les adresses physiques pourront être plus longues que les adresses réelles. Quelles que soient les longueurs respectives des adresses virtuelles et physiques, la table des pages, sous le contrôle du système d’exploitation, permettra de réaliser efficacement les traductions entre les adresses virtuelles et les adresses physiques.
Pour bien comprendre la traduction des adresses virtuelles en utilisant la table des pages, considérons un système imaginaire qui utilise des adresses virtuelles encodées sur 7 bits et des adresses physiques qui sont elles encodées sur 6 bits. La table des pages correspondante est reprise dans le tableau ci-dessous. La ligne du bas du tableau est relative à la page 0.
| Index | Validité | Adresse |
|---|---|---|
| 7 | true | 00 |
| 6 | false | |
| 5 | true | 11 |
| 4 | false | |
| 3 | false | |
| 2 | false | |
| 1 | true | 01 |
| 0 | true | 10 |
Cette mémoire virtuelle contient quatre pages. La première couvre les adresses physiques allant de 000000 à 001111, la seconde de 010000 à 011111, la troisième de 100000 à 101111 et la dernière de 110000 à 111111. Les adresses virtuelles elles vont de 0000000 à 1111111. La traduction s’effectue sur base de la table des pages. Ainsi, l’adresse 1010001 correspond à l’octet 0001 dans la page virtuelle 101. Sur base de la table des pages, cette page se trouve en mémoire RAM (son bit de validité est vrai) et elle démarre à l’adresse 110000. L’adresse virtuelle 1010001 est donc traduite en l’adresse réelle 110001. L’adresse virtuelle 0110111 correspond elle à une page qui n’est pas actuellement en mémoire RAM puisque le bit de validité correspondant à la page 011 est faux.
Si on analyse la table des pages ci-dessus, on peut remarquer que la page contenant les adresses virtuelles les plus hautes se trouve dans la zone mémoire avec les adresses physiques les plus basses. Inversement, la page qui est en mémoire RAM à l’adresse la plus élevée correspond à des adresses virtuelles qui se trouvent au milieu de l’espace d’adressage. Ce découplage entre l’adresse virtuelle et la localisation physique de la page en mémoire est un des avantages importants de la mémoire virtuelle.
La mémoire virtuelle a aussi un rôle important à jouer lorsque plusieurs processus s’exécutent simultanément. Comme indiqué ci-dessus, l’adresse de la table des pages est stockée dans un des registre du processeur. L’utilisation de ce registre permet d’avoir une table des pages pour chaque processus. Pour cela, il suffit qu’une zone de mémoire RAM soit réservée pour chaque processus et que le système d’exploitation y stocke la table des pages du processus. Lors d’un changement de contexte, le système d’exploitation modifie le registre de table des pages de façon à ce qu’il pointe vers la table des pages du processus qui s’exécute. Ce mécanisme est particulièrement utile et efficace.
A titre d’exemple, considérons un système imaginaire utilisant des adresses virtuelles sur 6 bits et des adresses physiques sur 8 bits. Deux processus s’exécutent sur ce système et ils utilisent chacun trois pages, deux pages dans le bas de l’espace d’adressage virtuel qui correspondent à leur segment de code et une page dans le haut de l’espace d’adressage virtuel qui correspond à leur pile. Le premier tableau ci-dessous présente la table des pages du processus P1.
| Index | Validité | Adresse |
|---|---|---|
| 3 | true | 0011 |
| 2 | false | |
| 1 | true | 1001 |
| 0 | true | 1000 |
Le processus P2 a lui aussi sa table des pages. Celle-ci pointe vers des adresses physiques qui sont différentes de celle utilisées par le processus P1. L’utilisation d’une table des pages par processus permet à deux processus distincts d’utiliser les mêmes adresses virtuelles.
| Index | Validité | Adresse |
|---|---|---|
| 3 | true | 0000 |
| 2 | false | |
| 1 | true | 1111 |
| 0 | true | 1110 |
Lorsque le processus P1 s’exécute, c’est sa table des pages qui est utilisée par le processeur pour la traduction des adresses virtuelles en adresses physiques. Ainsi, l’adresse 011101 est traduite en l’adresse 10011101. Par contre, lorsque le processus P2 s’exécute, cette adresse 011101 est traduite grâce à la table des pages de ce processus en l’adresse 11111101.
Note
Performance de la mémoire virtuelle
Grâce à son mécanisme d’indirection entre les adresses virtuelles et les adresses physiques, la mémoire virtuelle permet de nombreuses applications comme nous le verrons dans les sections qui suivent. Cependant, la mémoire virtuelle peut avoir un impact important au niveau des performances des accès à une donnée en mémoire. Pour cela, il est intéressant d’analyser en détails ce qu’il se passe lors de chaque accès à la mémoire. Pour accéder à une donnée en mémoire, le MMU doit d’abord consulter la table des pages pour traduire l’adresse virtuelle en une adresse physique correspondante. Ce n’est qu’après avoir obtenu cette adresse physique que le processeur peut effectuer l’accès à la mémoire RAM. En pratique, l’utilisation d’une table des pages a comme conséquence de doubler le temps d’accès à une donnée en mémoire. Lorsque la mémoire virtuelle a été inventée, ce doublement du temps d’accès à la mémoire n’était pas une limitation car les mémoires RAM étaient nettement plus rapides que les processeurs. Aujourd’hui, la situation est complètement inversée puisque les processeurs sont déjà fortement ralentis par les temps d’accès à la mémoire RAM. Doubler ce temps d’accès aurait un impact négatif sur les performances des processeurs. Pour faire face à ce problème, les processeurs actuels disposent tous d’un Translation Lookaside Buffer (TLB). Ce TLB est en fait une sorte de mémoire cache qui permet de stocker dans une mémoire rapide se trouvant sur le processeur certaines lignes de la table des pages. Les détails de gestion du TLB sortent du cadre de ce cours [HennessyPatterson]. Avec l’utilisation du TLB, et gràce au principe de localité qui fait que les accès mémoire se font très souvent dans un ensemble limité de pages, la plupart des traductions des adresses virtuelles en adresses physique peuvent être obtenues sans devoir directement consulter la table des pages.
La table des pages d’un processus contrôle les adresses physiques auxquelles le processus a accès. Pour garantir la sécurité d’un système informatique, il faut bien entendu éviter qu’un processus ne puisse modifier lui-même et sans contrôle sa table des pages. Toutes les manipulations de la table des pages ou du registre de table des pages se font sous le contrôle du système d’exploitation. La modification du registre de table des pages est une opération privilégiée qui ne peut être exécutée que par le noyau du système d’exploitation.
Pour permettre la gestion des accès et des fonctionnalités de sécurité, une entrée de la table des pages contient également des bits de permission qui sont contrôlés par le système d’exploitation et spécifient quelles opérations peuvent être effectuées sur chaque page. Une entrée de la table des pages contient trois bits de permissions :
- R bit. Ce bit indique si le processus peut accéder en lecture à la page se trouvant en mémoire physique.
- W bit. Ce bit indique si le processus peut modifier le contenu de la page se trouvant en mémoire physique
- X bit. Ce bit indique si la page contient des instructions qui peuvent être exécutées par le processeur (si vrai), ou des données (si faux).
Ces bits de protection sont généralement fixés par le système d’exploitation. Par exemple, le segment code qui ne contient que des instructions à exécuter pourra être stocké dans des pages avec les bits R et X mais pas le bit W pour éviter que le processus ne modifie les instructions qu’il exécute. Le stack par contre sera placé dans des pages avec les bits R et W mais pas le bit X [2] . Le heap peut utiliser les mêmes bits de protection. Enfin, les pages qui n’ont pas été allouées au processus, notamment celles se trouvant entre le heap et le stack auront toutes leurs bits de protection mis à faux. L’appel système brk(2) ou sbrk(2) aura pour effet de réserver certaines pages afin de permettre d’y allouer de la mémoire dynamiquement. L’utilisation des bits de protection permet au processeur de détecter les accès à de la mémoire qui n’a pas été allouée au processus. Un tel accès provoquera la génération d’une segmentation fault et l’envoi du signal correspondant.
Même si ces bits de protection sont contrôlés par le système d’exploitation, il est parfois utile à un processus de modifier les bits de permissions qui sont associés à certaines de ses pages. Cela peut se faire via l’appel système mprotect(2).
#include <sys/mman.h>
int mprotect(const void *addr, size_t len, int prot);
Cet appel système prend trois arguments. Le premier est un pointeur vers le début de la zone mémoire dont il faut modifier les bits de protection. Le second est la longueur de la zone mémoire concernée et le dernier la protection souhaitée. Celle-ci est spécifiée en utilisant les constantes PROT_NONE, PROT_READ, PROT_WRITE et PROT_EXEC qui peuvent être combinées en utilisant une disjonction logique. La protection demandée ne peut pas être plus libérale que la protection qui est déjà fixée par le système d’exploitation. Dans ce cas, le système d’exploitation génère un signal SIGSEGV.
Utilisation des dispositifs de stockage¶
La mémoire virtuelle permet non seulement à des pages d’un processus d’être placées à différents endroits de la mémoire, mais aussi elle permet de combiner la mémoire RAM et les dispositifs de stockage de façon transparente pour les processus.
Une partie des pages qui composent la mémoire virtuelle peut être stockée sur un dispositif de stockage (disque dur, SSD, ...). En pratique, la mémoire RAM peut jouer le rôle d’une sorte de mémoire cache pour la mémoire virtuelle. Les pages qui sont le plus fréquemment utilisées sont placées en mémoire RAM par le système d’exploitation. Les pages les moins utilisées sont quant à elles placées sur un dispositif de stockage et ramenées en mémoire RAM lorsqu’elles sont utilisées par le processeur.
Pour bien comprendre cette utilisation de la mémoire virtuelle, il nous faut revenir à la table des pages. Celle-ci comprend autant d’entrées qu’il y a de pages dans l’espace d’adressage d’un processus. Nous avons vu qu’une entrée de cette table pouvait être structurée comme dans la figure ci-dessous.
Entrée de la table des pages
Le bit de validité indique si la page est présente en mémoire RAM ou non. Lorsque la page est présente en mémoire RAM, les bits de poids faible de l’entrée de la table des pages contiennent l’adresse physique de la page en mémoire RAM. Lorsque le bit de validité a comme valeur faux, cela signifie que la page n’existe pas (elle n’a jamais été créée) ou qu’elle est actuellement stockée sur un dispositif de stockage. Si la page n’existe pas, aucun de ses bits de permission n’aura comme valeur vrai et tout accès à cette page provoquera une segmentation fault. Si par contre la page existe mais se trouve sur un dispositif de stockage, alors l’information de localisation pointera vers une structure de données qui est maintenue par le système d’exploitation et contient la localisation physique de la donnée sur un dispositif de stockage.
Schématiquement, ces informations de localisation des pages peuvent être de deux types. Lorsqu’un dispositif de stockage, ou une partition d’un tel dispositif, est dédié au stockage de pages de la mémoire virtuelle, alors la localisation d’une page est composée de l’identifiant du dispositif et du numéro du secteur sur le dispositif. Ce sera le cas lorsque par exemple une partition de swap est utilisée. Sous Linux, le fichier /proc/swaps contient la liste des partitions de swap qui sont utilisées pour stocker les pages de la mémoire virtuelle avec leur type, leur taille et leur utilisation. Une telle partition de swap peut être créée avec l’utilitaire mkswap(8). Elle est activée en exécutant la commande swapon(8). Celle-ci est généralement lancée automatiquement lors du démarrage du système.
$ cat /proc/swaps
Filename Type Size Used Priority
/dev/sda3 partition 8193140 444948 -1
Outre les partitions de swap, il est également possible de stocker des pages de la mémoire virtuelle dans des fichiers. Dans ce cas, la localisation d’une page comprend le dispositif, l’identifiant du fichier (son inode comme nous le verrons lorsque nous couvrirons les systèmes de fichiers) et l’offset à partir duquel la page est accessible dans ce fichier. En pratique, les partitions de swap sont un peu plus rapides que les fichiers de swap car les secteurs qui composent une telle partition sont contigus, ce qui n’est pas toujours le cas avec un fichier de swap. D’un autre côté, il est plus facile d’ajouter ou de retirer des fichiers de swap que des partitions de swap sur un dispositif de stockage. En pratique, les deux techniques peuvent être utilisées.
A ce stade, il est utile d’analyser à nouveau le fonctionnement de la mémoire virtuelle. En toute généralité, celle-ci est découpée en pages et comprend une mémoire RAM et un ou plusieurs dispositifs de stockage. Pour simplifier la présentation, nous supposons qu’un seul disque dur est utilisé.
La mémoire virtuelle
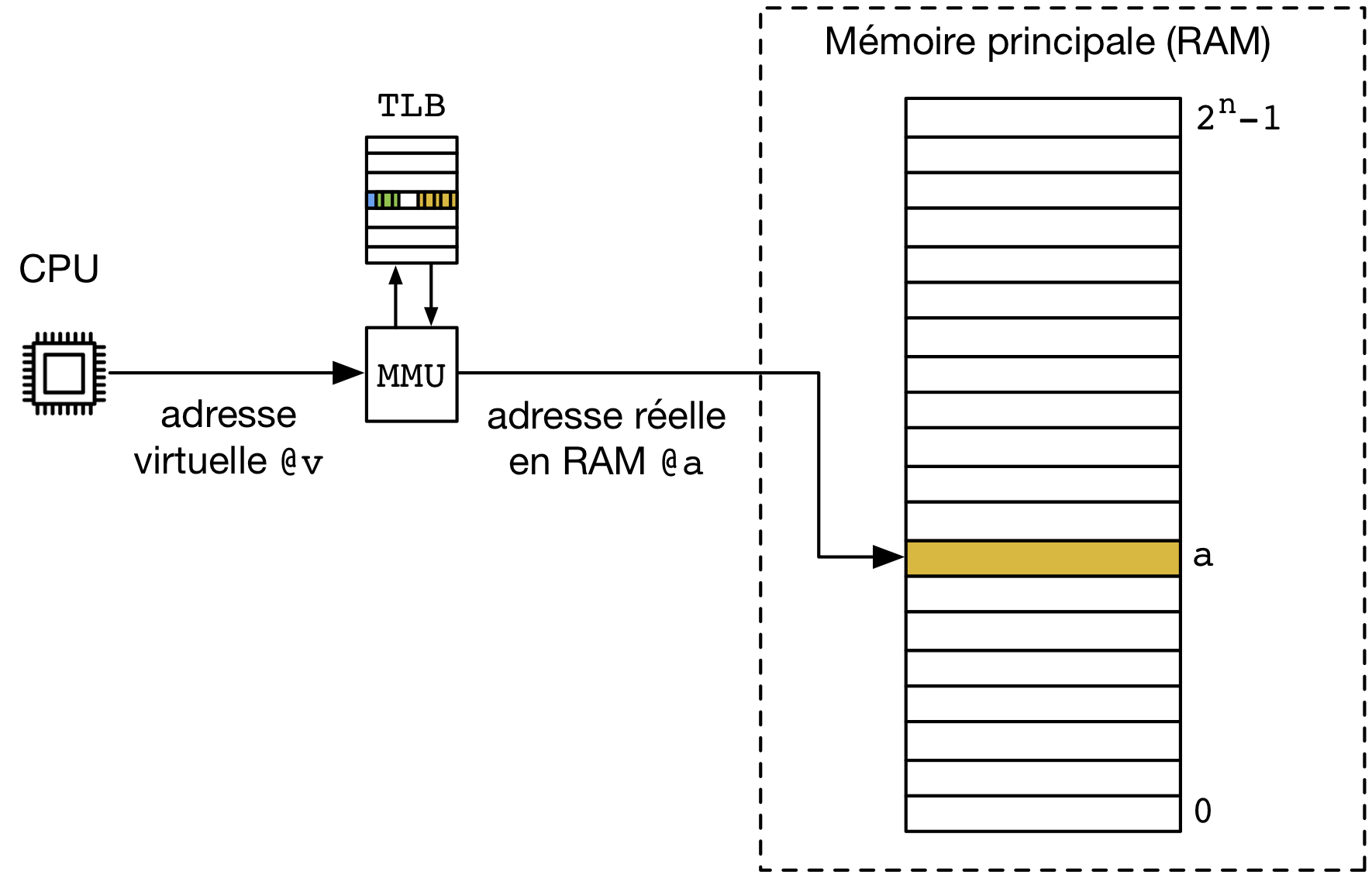
Les processus utilisent des adresses virtuelles pour représenter les positions des données et des instructions en mémoire virtuelles. Ces adresses virtuelles sont donc utilisées par le CPU chaque fois qu’il doit charger ou sauvegarder une donnée ou une instruction en mémoire. Comme nous l’avons vu, le MMU permet de traduire les adresses virtuelles en adresses réelles. Pour des raisons de performance, le MMU est intégré directement sur le processeur et il comprend un TLB qui sert de cache pour les entrées de la table des pages du processus qui est en train de s’exécuter.
Considérons une opération de lecture faite par le CPU. Pour réaliser cette opération, le CPU fournit l’adresse virtuelle au MMU. Celui-ci va consulter le TLB pour traduire l’adresse virtuelle demandée. Cette traduction peut nécessiter différentes opérations. Supposons que l’entrée de la table des pages demandées se trouve dans le TLB.
- Si le bit de validité de la page est vrai, la page demandée se situe en mémoire RAM. Dans ce cas, le MMU vérifie via les bits de permissions si l’accès demandé (dans ce cas une lecture, mais un raisonnement similaire est valable pour une écriture ou le chargement d’une instruction) est valide.
- Si l’accès est autorisé, le MMU retourne l’adresse réelle et le processeur accède aux données.
- Si l’accès n’est pas autorisé, le processeur génère une interruption. Le processus ayant tenté d’accéder à une zone de mémoire ne faisant pas partie de son espace d’adressage virtuel, c’est au système d’exploitation de réagir. Celui-ci enverra un signal segmentation fault, SIGSEGV, au processus qui a tenté cet accès.
Si le bit de validité de la page est faux, la page demandée ne se trouve pas en mémoire RAM. Deux cas de figure sont alors possibles :
- les bits de permission ne permettent aucun accès à la page. Dans ce cas, la page n’existe pas et le MMU va générer une interruption qui va provoquer l’exécution d’une routine de traitement d’interruption du système d’exploitation. Lors du traitement de cette opération, le noyau va envoyer un signal segmentation fault au processus qui a tenté cet accès.
- les bits de permission permettent l’accès à la page. On parle dans ce cas de page fault, c’est-à-dire qu’une page nécessaire à l’exécution du processus n’est pas disponible en mémoire RAM. Vu les temps d’accès et la complexité d’accéder à une page sur un disque dur (via une partition, un fichier de swap ou un fichier normal), le MMU ne peut pas accéder directement à la donnée sur le disque dur. Le MMU va donc générer une interruption qui va forcer l’exécution d’une routine de traitement d’interruption par le noyau. Cette routine va identifier la page manquante et préparer son transfert du disque dur vers la mémoire. Ce transfert peut durer plusieurs dizaines de millisecondes, ce qui est un temps très long par rapport à l’exécution d’instructions par le processeur. Tant que cette page n’est pas disponible en mémoire RAM, le processus ne peut pas continuer son exécution. Il passe dans l’état Blocked et le thread est alors associé à la structure d’attente correspondant à cette opération. Le scheduler va alors pouvoir sélectionner un autre thread en état Ready et lui allouer le processeur via un changement de contexte. Lorsque la page manquante aura été rapatriée depuis le disque dur en mémoire RAM, le thread pourra repasser en mode Ready et le scheduler redonnera accès à ce thread à un processeur, afin de retenter l’accès mémoire qui vient d’échouer.
Durant son exécution, un système doit pouvoir gérer des pages qui se trouvent en mémoire RAM et des pages qui sont stockées sur le disque dur. Lorsque la mémoire RAM est entièrement remplies de pages, il peut être nécessaire d’y libérer de l’espace mémoire en déplaçant des pages vers un des dispositifs de stockage. C’est le rôle des algorithmes de remplacement de pages.
Stratégies de remplacement de pages¶
C’est le système d’exploitation qui prend en charge les transferts de pages entre les dispositifs de stockage et la mémoire. Tant que la mémoire RAM n’est pas remplie, ces transferts sont simples, il suffit de ramener une ou plusieurs pages du dispositif de stockage vers la mémoire RAM. En général, le système d’exploitation cherchera à exploiter le principe de localité lors de ces transferts. Lorsqu’une page manque en mémoire RAM, le noyau programmera le chargement de cette page, mais aussi d’autres pages du même processus ayant des adresses proches.
Lorsque la mémoire RAM est remplie et qu’il faut ramener une page depuis un dispositif de stockage, le problème est plus délicat. Pour pouvoir charger cette nouvelle page en mémoire RAM, le système d’exploitation doit libérer de la mémoire. Pour cela, il doit implémenter une stratégie de remplacement de pages en mémoire. Cette stratégie définit quelle page doit être préférentiellement retirée de la mémoire RAM et placée sur le dispositif de stockage pour faire de la place pour la nouvelle page. Différentes stratégies sont possibles. Elles résultent en général d’un compromis entre la quantité d’information de contrôle qui doit être stockée dans la table des pages et les performances de la stratégie de remplacement des pages.
Une première stratégie de remplacement de pages pourrait être de sauvegarder les identifiants des pages dans une file FIFO. Chaque fois qu’une page est créée par le noyau, son identifiant est placé à la fin de cette file FIFO. Lorsque la mémoire est pleine et qu’une page doit être retirée de la mémoire RAM, le noyau pourrait choisir la page dont l’identifiant se trouve en tête de la file FIFO. Cette stratégie a l’avantage d’être simple à implémenter, mais remettre sur disque la page la plus anciennement créée n’est pas toujours la solution la plus efficace du point de vue des performances. En effet, cette page peut très bien être une des pages les plus utilisées par le processeur. Si elle est remise sur le disque, elle risque de devoir être récupérée peu de temps après.
Au niveau des performances, la meilleure stratégie de remplacement de pages serait de sauvegarder sur le disque dur les pages qui seront utilisées par le processeur d’ici le plus de temps possible. Malheureusement, cette stratégie nécessite de prévoir le futur, ce qui n’est évidemment pas possible (comme nous l’avons vu au chapitre précédent avec l’algorithme de scheduling hypothétique shortest-job-first) ... Une solution alternative serait de comptabiliser les accès aux différentes pages et de sauvegarder sur disque les pages qui ont été les moins utilisées. Cette solution est séduisante du point de vue théorique car en disposant de statistiques sur l’utilisation des pages, le système d’exploitation devrait pouvoir être capable de mieux prédire les pages qui seront nécessaires dans le futur et les conserver en mémoire RAM. Du point de vue de l’implémentation par contre, cette solution est loin d’être réaliste. En effet, pour maintenir un compteur du nombre d’accès à une page, il faut consommer de la mémoire supplémentaire dans chaque entrée de la table des pages. Mais il faut aussi que le TLB puisse incrémenter ce compteur lors de chaque accès à une de ces entrées. Cela augmente inutilement la complexité du TLB.
Stocker dans le TLB l’instant du dernier accès à une page de façon à pouvoir déterminer quelles sont les pages auxquelles le système a accédé depuis le plus longtemps est une autre solution séduisante d’un point de vue théorique. Du point de vue de l’implémentation, c’est loin d’être facilement réalisable. Tout d’abord, pour que cet instant soit utile, il faut probablement disposer d’une résolution d’une milliseconde voire mieux. Une telle résolution consommera au moins quelques dizaines de bits dans chaque entrée de la table des pages. En outre, le TLB devra pouvoir mettre à jour cette information lors de chaque accès.
Face à ces difficultés d’implémentation, la plupart des stratégies de remplacement de pages s’appuient sur deux bits qui se trouvent dans chaque entrée de la table des pages [HennessyPatterson]. Il est relativement facile de supporter ces deux bits dans une mise en œuvre matérielle du TLB et leur présence n’augmente pas de façon significative la mémoire occupée par une entrée de la table des pages.
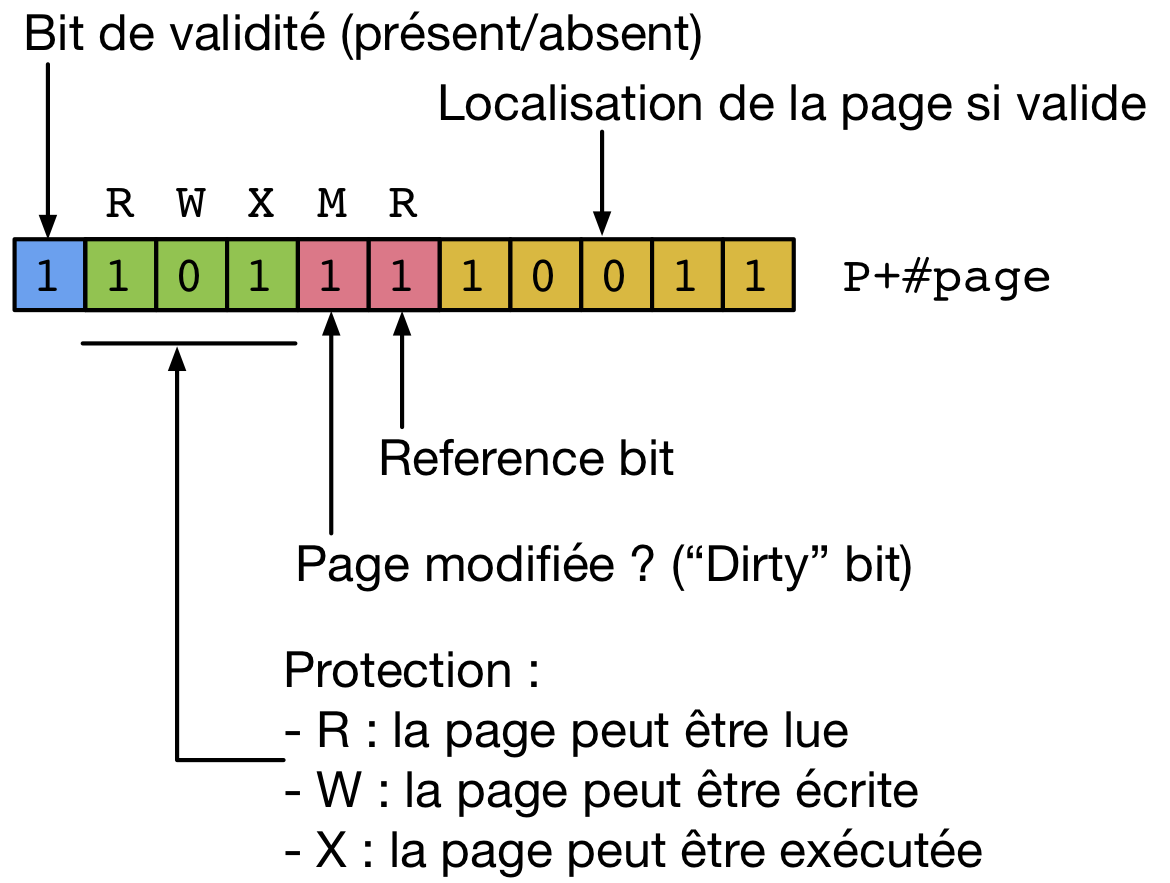
Une entrée complète de la table des pages
Outre les bits de validité et de permission, une entrée de la table des pages contient les bits de contrôle suivants :
- le bit de référence est mis à vrai par le MMU dans le TLB à chaque accès à une donnée se trouvant dans la page correspondante, que cet accès soit en lecture ou en écriture
- le bit de modification ou dirty bit est mis à vrai par le MMU chaque fois qu’une opération d’écriture est réalisée dans cette page.
Ces deux bits sont mis à jour par le MMU à l’intérieur du TLB. Lorsqu’une entrée de la table des pages est retirée du TLB pour être remise en mémoire, que ce soit à l’occasion d’un changement de contexte ou parce que le TLB est plein, les valeurs de ces deux bits sont recopiées dans l’entrée correspondante de la table des pages. En somme, le TLB fonctionne comme une cache en write-back pour ces deux bits de contrôle.
Les bits de référence et de modification sont utilisés par la plupart des algorithmes de remplacement de pages. Le bit de référence est généralement utilisé par le système d’exploitation pour déterminer quelles sont les pages auxquelles un processus accède actuellement. Pour cela, le noyau va régulièrement remettre à faux les bits de validité des entrées des tables de pages. Lorsque une entrée de la table des pages est chargée dans le TLB suite à un page fault, son bit de référence est mis à vrai. Il en va de même chaque fois que le processeur accède à une donnée dans cette page.
La stratégie de remplacement utilisant une file FIFO que nous avons mentionné précédemment peut être améliorée en utilisant le bit de référence. Plutôt que de remettre sur disque la page dont l’identifiant est en tête de la file il suffit de regarder son bit de référence. Si celui-ci a la valeur faux, la page n’a pas été utilisée récemment et peut donc être retirée de la mémoire RAM. Sinon, le bit de référence est remis à faux et l’identifiant de la page est replacé en fin de file. L’algorithme de remplacement de page passe ensuite à la page suivante dans la file et continue jusqu’à trouver suffisamment de pages ayant leur bit de référence mis à faux.
Une autre stratégie est de combiner le bit de référence et le dirty bit. Dans ce cas, le noyau du système d’exploitation va régulièrement remettre à la valeur faux tous les bits de référence (par exemple toutes les secondes). Lorsque la mémoire RAM est pleine et qu’il faut libérer de l’espace mémoire pour charger de nouvelles pages, l’algorithme de remplacement de pages va grouper les pages en mémoire en quatre classes.
- La première classe comprend les pages dont le bit de référence et le bit de modification ont comme valeur faux. Ces pages n’ont pas été utilisées récemment et sont identiques à la version qui est déjà stockée sur disque. Elles peuvent donc être retirée de la mémoire RAM sans nécessiter de transfert vers le disque.
- La deuxième classe comprend les pages dont le bit de référence a comme valeur faux mais le bit de modification a comme valeur vrai. Ces pages n’ont pas été utilisées récemment, mais doivent être transférées vers le disque avant d’être retirées de la mémoire RAM.
- La troisième classe comprend les pages dont le bit de référence a comme valeur vrai mais le bit de modification a comme valeur faux. Ces pages ont été utilisées récemment mais peuvent être retirées de la mémoire RAM sans nécessiter de transfert vers le disque.
- La dernière classe comprend les pages dont les bits de référence et de modification ont comme valeur vrai. Ces pages ont étés utilisées récemment et il faut les transférer vers le disque avant de les retirer de la mémoire RAM.
Si l’algorithme de remplacement de pages doit retirer des pages de la mémoire RAM, il commencera par retirer des pages de la première classe, et ensuite de la deuxième, ...
Des algorithmes plus performants ont été proposés et sont utilisés en pratique. Une description détaillée de ces algorithmes sort du cadre de ce cours d’introduction mais peut être trouvée dans un livre consacré aux systèmes d’exploitation comme [Tanenbaum+2009].
Note
Swapping et pagination
Grâce à l’utilisation de la mémoire virtuelle qui est découpée en pages, il est possible de stocker certaines parties de processus sur un dispositif de stockage plutôt qu’en mémoire RAM. Cette technique de pagination permet au système d’exploitation de gérer efficacement la mémoire et de réserver la mémoire RAM aux parties de processus qui sont nécessaires à leur exécution. Grâce à la découpe en pages, il est possible de transférer de petites parties d’un processus temporairement sur un dispositif de stockage. Aujourd’hui, la pagination est très largement utilisée, mais ce n’est pas la seule technique qui permette de placer temporairement l’espace mémoire utilisé par un processus sur disque. Le swapping est une technique plus ancienne mais qui est encore utilisée en pratique. Le swapping est plus radical que la pagination puisque cette technique permet au noyau de sauvegarder sur disque la quasi totalité de la mémoire utilisée par un processus. Le noyau fera appel au swapping lorsque la mémoire RAM est surchargée et pour des processus qui sont depuis longtemps bloqués par exemple en attente d’un opération d’entrée/sortie. Lorsque le noyau manque de mémoire, il est plus efficace de sauvegarder un processus complet plutôt que de transférer des pages de différents processus. Un tel processus swappé sera réactivé et ramené en mémoire par le noyau lorsqu’il repassera dans l’état Running, par exemple suite à la réussite d’une opération d’entrée/sortie.
Utilisations de la mémoire virtuelle¶
Comme nous l’avons vu précédemment, la mémoire virtuelle est découpée en pages et elle permet de découpler les adresses utilisées par les processus des adresses physiques. Grâce à la table des pages, il est possible de placer les pages d’un processus à n’importe quel endroit de la mémoire RAM. Mais la mémoire virtuelle permet également d’interagir avec les dispositifs de stockage comme si ils faisaient partie de la mémoire accessible au processus.
Fichiers mappés en mémoire¶
Lorsqu’un processus Unix veut lire ou écrire des données dans un fichier, il utilise en général les appels systèmes open(2), read(2), write(2) et close(2) directement ou à travers une librairie de plus haut niveau comme la libraire d’entrées/sorties standard. Ce n’est pas la seule façon d’accéder à des données sur un dispositif de stockage. Grâce à la mémoire virtuelle, il est possible de placer le contenu d’un fichier ou d’une partie de fichier dans une zone de la mémoire du processus. Cette opération peut être effectuée en utilisant l’appel système mmap(2). Cet appel système permet de rendre des pages d’un fichier accessibles à travers la table des pages du processus comme illustré dans la figure ci-dessous.
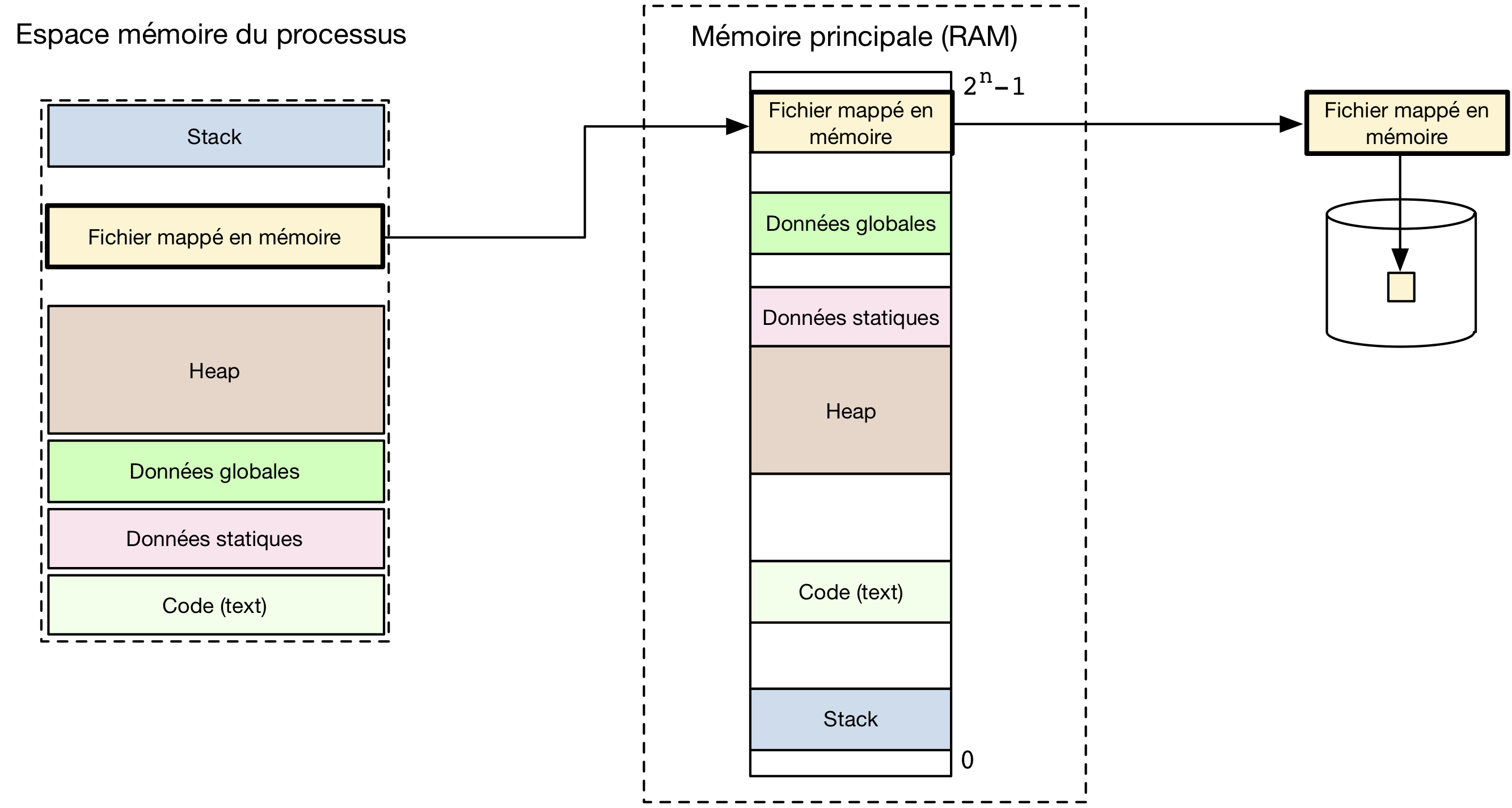
Fichiers mappés en mémoire
#include <sys/mman.h>
void *mmap(void *addr, size_t length, int prot, int flags,
int fd, off_t offset);
L’appel système mmap(2) prend six arguments, c’est un des appels systèmes qui utilise le plus d’arguments. Il permet de rendre accessible une portion d’un fichier via la mémoire d’un processus. Le cinquième argument est le descripteur du fichier qui doit être mappé. Celui-ci doit avoir été préalablement ouvert avec l’appel système open(2). Le sixième argument spécifie l’offset à partir duquel le fichier doit être mappé, 0 correspondant au début du fichier. Le premier argument est l’adresse à laquelle la première page du fichier doit être mappée. Généralement, cet argument est mis à NULL de façon à laisser le noyau choisir l’adresse la plus appropriée. Si cette adresse est spécifiée, elle doit être un multiple de la taille des pages. Le deuxième argument est la longueur de la zone du fichier qui doit être mappée en mémoire. Le troisième argument contient des drapeaux qui spécifient les permissions d’accès aux données mappées. Cet argument peut soit être PROT_NONE, ce qui indique que la page est inaccessible soit une permission classique :
- PROT_EXEC, les pages mappées contiennent des instructions qui peuvent être exécutées
- PROT_READ, les pages mappées contiennent des données qui peuvent être lues
- PROT_WRITE, les pages mappées contiennent des données qui peuvent être modifiées
Ces drapeaux peuvent être combinés avec une disjonction logique. Le quatrième argument est un drapeau qui indique comment les pages doivent être mappées en mémoire. Ce drapeau spécifie comment un fichier qui est mappé par deux ou plusieurs processus doit être traité. Deux drapeaux sont possibles :
- MAP_PRIVATE. Dans ce cas, les pages du fichier sont mappées dans chaque processus, mais si un processus modifie une page, cette modification n’est pas répercutée aux autres processus qui ont mappé la même page de ce fichier.
- MAP_SHARED. Dans ce cas, plusieurs processus peuvent accéder et modifier la page qui est mappée en mémoire. Lorsqu’un processus modifie le contenu d’une page, la modification est visible aux autres processus. Par contre, le fichier qui est mappé en mémoire n’est modifié que lorsque le noyau du système d’exploitation décide d’écrire les données modifiées sur le dispositif de stockage. Ces écritures dépendent de nombreux facteurs, dont la charge du système. Si un processus veut être sûr des écritures sur disque des modifications qu’il a fait à un fichier mappé un mémoire, il doit exécuter l’appel système msync(2) ou supprimer le mapping via munmap(2).
Ces deux drapeaux peuvent dans certains cas particuliers être combinés avec d’autres drapeaux définis dans la page de manuel de mmap(2).
Lorsque mmap(2) réussit, il retourne l’adresse du début de la zone mappée en mémoire. En cas d’erreur, la constante MAP_FAILED est retournée et errno est mis à jour en conséquence.
L’appel système msync(2) permet de forcer l’écriture sur disque d’une zone mappée en mémoire. Le premier argument est l’adresse du début de la zone qui doit être écrite sur disque. Le deuxième argument est la longueur de la zone qui doit être écrite sur le disque. Enfin, le dernier contient un drapeau qui spécifie comment les pages correspondantes doivent être écrites sur le disque. La drapeau MS_SYNC indique que l’appel msync(2) doit bloquer tant que les données n’ont pas été écrites. Le drapeau MS_ASYNC indique au noyau que l’écriture doit être démarrée, mais l’appel système peut se terminer avant que toutes les pages modifiées aient été écrites sur disque.
#include <sys/mman.h>
int msync(void *addr, size_t length, int flags);
Lorsqu’un processus a fini d’utiliser un fichier mappé en mémoire, il doit d’abord supprimer le mapping en utilisant l’appel système munmap(2). Cet appel système prend deux arguments. Le premier doit être un multiple de la taille d’une page [6]. Le second est la taille de la zone pour laquelle le mapping doit être retiré.
#include <sys/mman.h>
int munmap(void *addr, size_t length);
A titre d’exemple d’utilisation de mmap(2) et munmap(2), le programme ci-dessous implémente l’équivalent de la commande cp(1). Il prend comme arguments deux noms de fichiers et copie le contenu du premier dans le second. La copie se fait en mappant le premier fichier entièrement en mémoire et en utilisant la fonction memcpy(3) pour réaliser la copie. Cette solution fonctionne avec de petits fichiers. Avec de gros fichiers, elle n’est pas très efficace car tout le fichier doit être mappé en mémoire.
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/mman.h>
#include <fcntl.h>
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main (int argc, char *argv[]) {
int file1, file2;
void *src, *dst;
struct stat file_stat;
char dummy=0;
if (argc != 3) {
fprintf(stderr,"Usage : cp2 source dest\n");
exit(EXIT_FAILURE);
}
// ouverture fichier source
if ((file1 = open (argv[1], O_RDONLY)) < 0) {
perror("open(source)");
exit(EXIT_FAILURE);
}
if (fstat (file1,&file_stat) < 0) {
perror("fstat");
exit(EXIT_FAILURE);
}
// ouverture fichier destination
if ((file2 = open (argv[2], O_RDWR | O_CREAT | O_TRUNC, file_stat.st_mode)) < 0) {
perror("open(dest)");
exit(EXIT_FAILURE);
}
// le fichier destination doit avoir la même taille que le source
if (lseek (file2, file_stat.st_size - 1, SEEK_SET) == -1) {
perror("lseek");
exit(EXIT_FAILURE);
}
// écriture en fin de fichier
if (write (file2, &dummy, sizeof(char)) != 1) {
perror("write");
exit(EXIT_FAILURE);
}
// mmap fichier source
if ((src = mmap (NULL, file_stat.st_size, PROT_READ, MAP_SHARED, file1, 0)) == (void *)(-1)) {
perror("mmap(src)");
exit(EXIT_FAILURE);
}
// mmap fichier destination
if ((dst = mmap (NULL, file_stat.st_size, PROT_READ | PROT_WRITE, MAP_SHARED, file2, 0)) == (void *)(-1)) {
perror("mmap(src)");
exit(EXIT_FAILURE);
}
// copie complète
memcpy (dst, src, file_stat.st_size);
// libération mémoire
if(munmap(src,file_stat.st_size)<0) {
perror("munmap(src)");
exit(EXIT_FAILURE);
}
if(munmap(dst,file_stat.st_size)<0) {
perror("munmap(dst)");
exit(EXIT_FAILURE);
}
// fermeture fichiers
if(close(file1)<0) {
perror("close(file1)");
exit(EXIT_FAILURE);
}
if(close(file2)<0) {
perror("close(file2)");
exit(EXIT_FAILURE);
}
return(EXIT_SUCCESS);
}
Mémoire partagée¶
Dans les exemples précédents, nous avons supposé qu’il existait une correspondance biunivoque entre chaque page de la mémoire virtuelle et une page en mémoire RAM. C’est souvent le cas, mais ce n’est pas nécessaire. Il est tout à fait possible d’avoir plusieurs pages de la mémoire virtuelle qui appartiennent à des processus différents mais pointent vers la même page en mémoire physique. Ce partage d’une même page physique entre plusieurs pages de la mémoire virtuelle a plusieurs utilisations en pratique.
Revenons aux threads POSIX. Lorsqu’un processus crée un nouveau thread d’exécution, celui-ci a un accès complet au segment code, aux variables globales et au heap du processus. Par contre, le thread et le processus ont chacun un stack qui leur est propre. Comme nous l’avons indiqué lors de la présentation des threads, ceux-ci peuvent être implémentés en utilisant une librairie ou avec l’aide du système d’exploitation. Du point de vue de la mémoire, lorsqu’une librairie telle que gnuth est utilisée pour créer un thread, la librairie réserve une zone de mémoire sur le heap pour ce thread. Cette zone mémoire contient le stack qui est spécifique au thread. Celui-ci a été alloué en utilisant malloc(3) et a généralement une taille fixe. Avec la mémoire virtuelle, il est possible d’implémenter les threads plus efficacement avec l’aide du système d’exploitation. Lors de la création d’un thread, celui-ci va tout d’abord créer une nouvelle table des pages pour le thread. Celle-ci sera initialisée en copiant toutes les entrées de la table des pages du processus, sauf celles qui correspondent au stack. De cette façon, le processus père et le thread auront accès aux mêmes segments de code, aux même variables globales et au même heap. Toute modification faite par le processus père à une variable globale ou à une information stockée sur le heap sera immédiatement accessible au thread et inversement. L’entrée de la table des pages du thread correspondant à son stack pointera vers une page qui sera spécifique au thread. Cette page aura été initialisée par le système d’exploitation avec l’argument passé par le processus à la fonction pthread_create(3). La figure ci-dessous illustre ce partage de table des pages après la création d’un thread.

Tables des pages après création d’un thread. Les segments de même nom et de même couleur sont partagés par les deux threads, sauf pour le segment de Stack qui est spécifique.
En exploitant intelligemment la table des pages, il est également possible de permettre à deux processus distincts d’avoir accès à la même zone de mémoire physique. Si deux processus peuvent accéder simultanément à la même zone de mémoire, ils peuvent l’utiliser pour communiquer plus efficacement qu’en utilisant des pipes par exemple. Cette technique porte le nom de mémoire partagée. Elle nécessite une modification de la table des pages des processus qui veulent partager une même zone mémoire. Pour comprendre le fonctionnement de cette mémoire partagée, considérons le cas de deux processus : P1 et P2 qui veulent pouvoir utiliser une page commune en mémoire. Pour cela, plusieurs interactions entre les processus et le système d’exploitation sont nécessaires comme nous allons le voir.
Avant de permettre à deux processus d’accéder à la même page en mémoire physique, il faut d’abord se poser la question de l’origine de cette page physique. Deux solutions sont possibles. La première est de prendre cette page parmi les pages qui appartiennent à l’un des processus, par exemple P1. Lorsque la page est partagée, le système d’exploitation peut modifier la table des pages du processus P2 de façon à lui permettre d’y accéder. La seconde est que le noyau du système d’exploitation fournisse une nouvelle page qui pourra être partagée. Cette page “appartient” au noyau mais celui-ci la rend accessible aux processus P1 et P2 en modifiant leurs tables des pages. Linux utilise la seconde technique. Elle a l’avantage de permettre un meilleur contrôle par le système d’exploitation du partage de pages entre différents processus. De plus, lorsqu’une zone de mémoire partagée a été créée via le système d’exploitation, elle survit à la terminaison de ce processus. Une mémoire partagée créée par un processus peut donc être utilisée par d’autres processus.
Sous Linux, la mémoire partagée peut s’utiliser via les appels systèmes shmget(2), shmat(2) et shmdt(2). L’appel système shmget(2) permet de créer un segment de mémoire partagée. Le premier argument de shmget(2) est une clé qui identifie le segment de mémoire partagée. Cette clé est en pratique encodée sous la forme d’un entier qui identifie le segment de mémoire partagée. Elle sert d’identifiant du segment de mémoire partagée dans le noyau. Un processus doit connaître la clé qui identifie un segment de mémoire partagée pour pouvoir y accéder. Le deuxième argument de shmget(2) est la taille du segment. En pratique, celle-ci sera arrondie au multiple entier supérieur de la taille d’une page. Enfin, le troisième argument sont des drapeaux qui contrôlent la création du segment et les permissions qui y sont associées.
#include <sys/ipc.h>
#include <sys/shm.h>
int shmget(key_t key, size_t size, int shmflg);
L’appel système shmget(2) retourne un entier qui identifie le segment de mémoire partagée à l’intérieur du processus si il réussit et -1 sinon. Il peut être utilisé de deux façons. Un processus peut appeler shmget(2) pour créer un nouveau segment de mémoire partagée. Pour cela, il choisit une clé unique qui identifie ce segment et utilise le drapeau IPC_CREAT. Celui-ci peut être combiné avec les drapeaux qui sont supportés par l’appel système open(2). Ainsi, le fragment de code ci-dessous permet de créer une page de mémoire partagée qui a 1252 comme identifiant et est accessible en lecture et en écriture par tous les processus qui appartiennent au même utilisateur ou au même groupe que le processus courant. Si cet appel à shmget(2) réussit, le segment de mémoire est initialisé à la valeur 0.
key_t key=1252;
int shm_id = shmget(key, 4096, IPC_CREAT | S_IRUSR | S_IWUSR | S_IRGRP | S_IWGRP );
if (shm_id == -1) {
perror("shmget");
exit(EXIT_FAILURE);
}
La fonction shmget(2) peut aussi être utilisée par un processus pour obtenir l’autorisation d’accéder à un segment de mémoire partagée qui a été créé par un autre processus. Dans ce cas, le drapeau IPC_CREAT n’est pas passé en argument.
Il est important de noter que si l’appel à shmget(2) réussit, cela indique que le processus dispose des permissions pour accéder au segment de mémoire partagée, mais à ce stade il n’est pas accessible depuis la table des pages du processus. Cette modification à la table des pages du processus se fait en utilisant shmat(2). Cet appel système permet d’attacher un segment de mémoire partagée à un processus. Il prend comme premier argument l’identifiant du segment de mémoire retourné par shmget(2). Le deuxième argument est un pointeur vers la zone mémoire via laquelle le segment doit être accessible dans l’espace d’adressage virtuel du processus. Généralement, c’est la valeur NULL qui est spécifiée comme second argument et le noyau choisit l’adresse à laquelle le segment de mémoire est attaché dans le processus. Il est aussi possible de spécifier une adresse dans l’espace d’adressage du processus. Le troisième argument permet, en utilisant le drapeau SHM_RDONLY, d’attacher le segment en lecture seule. shmat(2) retourne l’adresse à laquelle le segment a été attaché en cas de succès et (void *) -1 en cas d’erreur.
#include <sys/types.h>
#include <sys/shm.h>
void *shmat(int shmid, const void *shmaddr, int shmflg);
int shmdt(const void *shmaddr);
L’appel système shmdt(2) permet de détacher un segment de mémoire qui avait été attaché en utilisant shmat(2). L’argument passé à shmdt(2) doit être l’adresse d’un segment de mémoire attaché préalablement par shmat(2). Lorsqu’un processus se termine, tous les segments auxquels il était attaché sont détachés lors de l’appel à exit(2). Cela n’empêche pas un programme de détacher correctement tous les segments de mémoire qu’il utilise avant de se terminer.
Le fragment de code ci-dessous présente comment un segment de mémoire peut être attaché et détaché après avoir été créé avec shmget(2).
void * addr = shmat(shm_id, NULL, 0);
if (addr == (void *) -1) {
perror("shmat");
exit(EXIT_FAILURE);
}
// ...
if(shmdt(addr)==-1) {
perror("shmdt");
exit(EXIT_FAILURE);
}
Note
Attention aux pointeurs en mémoire partagée
Lorsque deux processus partagent le même segment de mémoire partagée, ils ont tous les deux accès directement à la mémoire. Il est ainsi possible de stocker dans cette mémoire un tableau de nombres ou de caractères. Chacun des processus pourra facilement accéder aux données stockées dans le tableau. Il faut cependant être vigilant lorsque l’on veut stocker une structure de données utilisant des pointeurs dans un segment de mémoire partagée. Considérons une liste simplement chaînée. Cette liste peut être implémentée en utilisant une structure contenant la donnée stockée dans l’élément de la liste (par exemple un entier) et un pointeur vers l’élément suivant dans la liste (et NULL en fin de liste). Imaginons que les deux processus ont attaché le segment de mémoire destiné à contenir la liste avec l’appel shmat(2) présenté ci-dessus et que l’adresse retournée par shmat(2) est celle qui correspond au premier élément de la liste. Comme le système d’exploitation choisit l’adresse à laquelle le segment de mémoire partagée est stocké dans chaque processus, l’appel à shmat(2) retourne potentiellement une adresse différente dans les deux processus. Si ils peuvent tous les deux accéder au premier élément de la liste, il n’en sera pas de même pour le second élément. En effet, si cet élément a été créé par le premier processus, le pointeur contiendra l’adresse du second élément dans l’espace d’adressage virtuel du premier processus. Cette adresse ne correspondra en général pas à celle du second élément dans l’espace d’adressage du second processus. Pour cette raison, il est préférable de ne pas utiliser de pointeurs dans un segment de mémoire partagé.
Comme les segments de mémoire partagée sont gérés par le noyau du système d’exploitation, ils persistent après la terminaison du processus qui les a créé. C’est intéressant lorsque l’on veut utiliser des segments de mémoire partagée pour la communication entre plusieurs processus dont certains peuvent se terminer par une erreur. Malheureusement, le nombre de segments de mémoire partagée qui peuvent être utilisés sur un système Unix est borné. Lorsque la limite fixée par la configuration du noyau est atteinte, il n’est plus possible de créer de nouveau segment de mémoire partagée. Sous Linux ces limites sont visibles dans les fichiers /proc/sys/kernel/shmmni (nombre maximum d’identifiants de segments de mémoire partagée) et /proc/sys/kernel/shmall (taille totale maximale de la mémoire partagée) ou via shmctl(2). Cet appel système permet de réaliser de nombreuses fonctions de contrôle de la mémoire partagée et notamment la destruction de segments de mémoire partagée qui ont été créés par shmget(2). shmctl(2) s’appuie sur les structures de données qui sont maintenues par le noyau pour les segments de mémoire partagée. Lorsqu’un segment de mémoire partagée est crée, le noyau lui associe une structure de type shmid_ds.
struct shmid_ds {
struct ipc_perm shm_perm; /* Propriétaire et permissions */
size_t shm_segsz; /* Taille du segment (bytes) */
time_t shm_atime; /* Instant de dernier attach */
time_t shm_dtime; /* Instant de dernier detach */
time_t shm_ctime; /* Instant de dernière modification */
pid_t shm_cpid; /* PID du créateur */
pid_t shm_lpid; /* PID du dernier `shmat(2)`_ / `shmdt(2)`_ */
shmatt_t shm_nattch; /* Nombre de processus attachés */
};
Ce descripteur de segment de mémoire partagée, décrit dans shmctl(2) contient plusieurs informations utiles. Son premier élément est une structure qui reprend les informations sur le propriétaire et les permissions qui ont été définies ainsi que la taille du segment. Le descripteur de segment comprend ensuite les instants auxquels les dernières opérations shmat(2), shmdt(2) et la dernière modification au segment ont été faites. Le dernier élément contient le nombre de processus qui sont actuellement attachés au segment. L’appel système shmctl(2) prend trois arguments. Le premier est un identifiant de segment de mémoire partagée retourné par shmget(2). Le deuxième est une constante qui spécifie une commande. Nous utiliserons uniquement la commande IPC_RMID qui permet de retirer le segment de mémoire partagée dont l’identifiant est passé comme premier argument. Si il n’y a plus de processus attaché au segment de mémoire partagée, celui-ci est directement supprimé. Sinon, il est marqué de façon à ce que le noyau retire le segment dès que le dernier processus s’en détache. shmctl(2) retourne 0 en cas de succès et -1 en cas d’échec.
#include <sys/ipc.h>
#include <sys/shm.h>
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
Le segment de mémoire partagée qui a été créé dans les exemples précédents peut être supprimé avec le fragment de code ci-dessous.
if (shmctl(shm_id, IPC_RMID, 0) != 0) {
perror("shmctl");
exit(EXIT_FAILURE);
}
En pratique, comme le noyau ne détruit un segment de mémoire partagée que lorsqu’il n’y a plus de processus qui y est attaché, il peut être utile de détruire le segment de mémoire partagée juste après avoir effectué l’appel shmat(2). C’est ce que l’on fera par exemple si un processus père utilise un segment de mémoire partagée pour communiquer avec son processus fils.
La mémoire partagée est utilisée non seulement pour permettre la communication entre processus, mais également avec les librairies partagées. Celles-ci sont chargées automatiquement lors de l’exécution d’un processus qui les utilise. Les instructions qui font partie de ces librairies partagées sont chargées dans la même zone mémoire que celle qui est utilisée pour la mémoire partagée. Sous Linux, cette zone mémoire est située entre le heap et le stack comme illustré dans la figure ci-dessous.
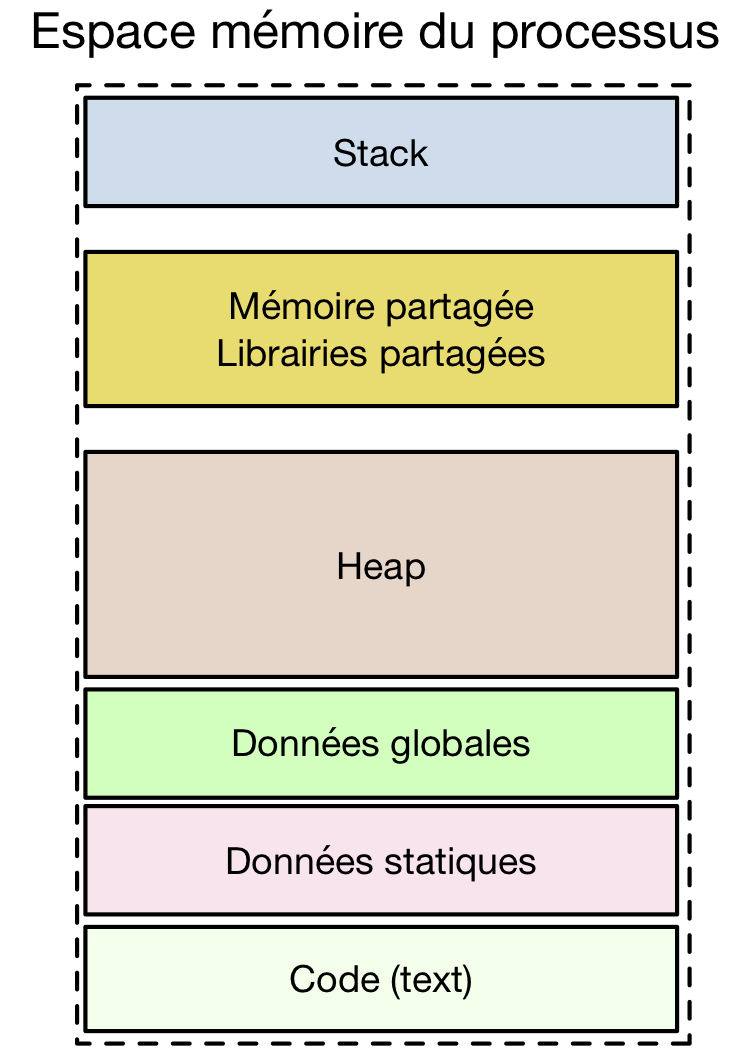
Organisation en mémoire d’un processus
Lorsqu’il exécute un processus, le noyau maintient dans les structures de données qui sont relatives à ce processus la liste des segments de mémoire partagée et des librairies partagées qu’il utilise. Sous Linux, cette information est visible via le pseudo-système de fichiers /proc. Le fichier /proc/PID/maps représente de façon textuelle la table des segments de mémoire qui sont partagés dans le processus PID.
Un exemple d’un tel fichier maps est présenté ci-dessous. Il contient une carte de l’ensemble des pages qui appartiennent à un processus. Le fichier comprend six colonnes. La première est la zone de mémoire virtuelle. La seconde sont les bits de permission avec r pour la permission de lecture, w pour l’écriture et x pour l’exécution. Le dernier bit de permission est à la valeur p lorsque la page est en copy-on-write et s lorsqu’il s’agit d’un segment de mémoire partagé. Les trois dernières colonnes sont relatives au stockage des pages sur le disque.
00400000-00402000 r-xp 00000000 00:1a 49485798 /tmp/a.out
00602000-00603000 rw-p 00002000 00:1a 49485798 /tmp/a.out
3d3f200000-3d3f220000 r-xp 00000000 08:01 268543 /lib64/ld-2.12.so
3d3f41f000-3d3f420000 r--p 0001f000 08:01 268543 /lib64/ld-2.12.so
3d3f420000-3d3f421000 rw-p 00020000 08:01 268543 /lib64/ld-2.12.so
3d3f421000-3d3f422000 rw-p 00000000 00:00 0
3d3f600000-3d3f786000 r-xp 00000000 08:01 269510 /lib64/libc-2.12.so
3d3f786000-3d3f986000 ---p 00186000 08:01 269510 /lib64/libc-2.12.so
3d3f986000-3d3f98a000 r--p 00186000 08:01 269510 /lib64/libc-2.12.so
3d3f98a000-3d3f98b000 rw-p 0018a000 08:01 269510 /lib64/libc-2.12.so
3d3f98b000-3d3f990000 rw-p 00000000 00:00 0
3d3fa00000-3d3fa83000 r-xp 00000000 08:01 269516 /lib64/libm-2.12.so
3d3fa83000-3d3fc82000 ---p 00083000 08:01 269516 /lib64/libm-2.12.so
3d3fc82000-3d3fc83000 r--p 00082000 08:01 269516 /lib64/libm-2.12.so
3d3fc83000-3d3fc84000 rw-p 00083000 08:01 269516 /lib64/libm-2.12.so
7f7c57e42000-7f7c57e45000 rw-p 00000000 00:00 0
7f7c57e60000-7f7c57e61000 rw-s 00000000 00:04 66355276 /SYSV00000000
7f7c57e61000-7f7c57e63000 rw-p 00000000 00:00 0
7fffc479c000-7fffc47b1000 rw-p 00000000 00:00 0 [stack]
L’exemple ci-dessus présente la carte de mémoire d’un processus qui utilise trois librairies partagées. Le segment de mémoire partagée se trouve aux adresses virtuelles 7f7c57e60000-7f7c57e61000. Il est accessible en lecture et en écriture.
Implémentation de fork(2)¶
La mémoire partagée joue un rôle clé dans l’exécution efficace des appels systèmes fork(2) et execve(2). Considérons d’abord fork(2). Cet appel est fondamental sur un système Unix. Au fil des années, les développeurs de Unix et de Linux ont cherché à optimiser ses performances. Une implémentation naïve de l’appel système fork(2) est de copier physiquement toutes les pages utilisées en mémoire RAM par le processus père. Ensuite, le noyau peut créer une table des pages pour le processus fils qui pointe vers les copies des pages du processus père. De cette façon, le processus père et le processus fils utilisent exactement les mêmes instructions. Ils peuvent donc poursuivre leur exécution à partir des mêmes données en mémoire. Mais chaque processus pourra faire les modifications qu’il souhaite aux données stockées en mémoire. Cette implémentation était utilisée par les premières versions de Unix, mais elle est peu efficace, notamment pour les processus qui consomment beaucoup de mémoire. Pour le shell, qui généralement exécute fork(2) suivi immédiatement par execve(2), copier l’entièreté de la mémoire du processus père est un pur gaspillage de ressources.
La mémoire virtuelle permet d’optimiser l’appel système fork(2) et de le rendre nettement plus rapide. Lors de la création d’un processus fils, le noyau du système d’exploitation commence par créer une table des pages pour le processus fils. En initialisant cette table avec les mêmes entrées que celles du processus père, le noyau permet aux deux processus d’accéder aux mêmes instructions et aux mêmes données. Pour les instructions se trouvant dans le segment code et dont les entrées de la table des pages sont généralement en read-only, cette solution fonctionne correctement. Le processus père et le processus fils peuvent exécuter exactement les mêmes instructions tout en n’utilisant qu’une seule copie de ces instructions en mémoire.
Malheureusement, cette solution ne fonctionne plus pour les pages contenant les données globales, le stack et le heap. En effet, ces pages doivent pouvoir être modifiées de façon indépendante par le processus père et le processus fils. C’est notamment le cas pour la zone mémoire qui contient la valeur de retour de l’appel système fork(2). Par définition, cette zone mémoire doit contenir une valeur différente dans le processus père et le processus fils. Pour éviter ce problème, le noyau pourrait copier physiquement les pages contenant les variables globales, le heap et le stack. Cela permettrait, notamment dans le cas de l’exécution de fork(2) par le shell d’améliorer les performances de fork(2) sans pour autant compromettre la sémantique de cet appel système. Il existe cependant une alternative à cette copie physique. Il s’agit de la technique du copy-on-write.
Sur un système qui utilise copy-on-write, l’appel système fork(2) est mis en œuvre de la façon suivante. Lors de l’exécution de fork(2), le noyau copie toutes les entrées de la table des pages du processus père vers la table des pages du processus fils. Ce faisant, le noyau modifie également les permissions de toutes les pages utilisées par le processus père. Les pages correspondant au segment de code sont toutes marquées en lecture seule. Les pages correspondant aux données globales, heap et stack sont marquées avec un statut spécial (copy-on-write). Celui-ci autorise les accès en lecture à la page sans restriction. Si un processus tente un accès en écriture sur une de ces pages, le MMU interrompt l’exécution du processus et force l’exécution d’une routine d’interruption du noyau. Celle-ci analyse la tentative d’accès à la mémoire qui a échoué. Si la page était en lecture seule (par exemple une page du segment de code), un signal SIGSEGV est envoyé au processus concerné. Si par contre la page était marquée copy-on-write, alors le noyau alloue une nouvelle page physique et y recopie la page où la tentative d’accès a eu lieu. La table des pages du processus qui a fait la tentative d’accès est modifiée pour pointer vers la nouvelle page avec une permission en lecture et en écriture. La permission de l’entrée de la table des pages de l’autre processus est également modifiée de façon à autoriser les écritures et les lectures. Les deux processus disposent donc maintenant d’une copie différente de cette page et ils peuvent la modifier à leur guise. Cette technique de copy-on-write permet de ne copier que les pages qui sont modifiées par le processus père ou le processus fils. C’est un gain de temps appréciable par rapport à la copie complète de toutes les pages.
Dans le pseudo fichier /proc/PID/maps présenté précédemment, le bit p indique que les pages correspondantes sont en copy-on-write.
Interactions entre les processus et la mémoire¶
La mémoire virtuelle est gérée par le système d’exploitation. La plupart des processus supportent très bien d’avoir certaines de leurs pages qui sont sauvegardées sur disque lorsque la mémoire est saturée. Cependant, dans certains cas très particuliers, il peut être intéressant pour un processus de contrôler quelles sont ses pages qui restent en mémoire et quelles sont celles qui sont stockées sur le disque dur. Linux fournit plusieurs appels systèmes qui permettent à un processus de surveiller et éventuellement d’influencer la stratégie de remplacement des pages.
#include <unistd.h>
#include <sys/mman.h>
int mincore(void *addr, size_t length, unsigned char *vec);
L’appel système mincore(2) permet à un processus d’obtenir de l’information sur certaines de ses pages. Il prend comme premier argument une adresse, qui doit être un multiple de la taille des pages. Le deuxième est la longueur de la zone mémoire pour laquelle le processus demande de l’information. Le dernier argument est un pointeur vers une chaîne de caractères qui doit contenir autant de caractères que de pages dans la zone de mémoire analysée. Cette chaîne de caractères contiendra des drapeaux pour chaque page de la zone mémoire concernée. Les principaux sont :
- MINCORE_INCORE indique que la page est en mémoire RAM
- MINCORE_REFERENCED indique que la page a été référencée
- MINCORE_MODIFIED indique que la page a été modifiée
Un exemple d’utilisation de mincore(2) est repris dans le programme /MemoireVirtuelle/src/mincore.c ci-dessous.
#dfine _BSD_SOURCE
#define SIZE 10*4096
int main(int argc, char *argv[]) {
char *mincore_vec;
size_t page_size = getpagesize();
size_t page_index;
char *mem;
mem=(char *)malloc(SIZE*sizeof(char));
if(mem==NULL) {
perror("malloc");
exit(EXIT_FAILURE);
}
for(int i=0;i<SIZE/2;i++) {
*(mem+i)='A';
}
mincore_vec = calloc(sizeof(char), SIZE/page_size);
if(mincore_vec==NULL) {
perror("calloc");
exit(EXIT_FAILURE);
}
if(mincore(mem, SIZE, mincore_vec)!=0) {
perror("mincore");
exit(EXIT_FAILURE);
}
for (page_index = 0; page_index < SIZE/page_size; page_index++) {
printf("%lu :", (unsigned long)page_index);
if (mincore_vec[page_index]&MINCORE_INCORE) {
printf(" incore");
}
if (mincore_vec[page_index]&MINCORE_REFERENCED) {
printf(" referenced_by_us");
}
if (mincore_vec[page_index]&MINCORE_MODIFIED) {
printf(" modified_by_us");
}
printf("\n");
}
free(mincore_vec);
free(mem);
return (EXIT_SUCCESS);
}
Certains processus doivent pouvoir contrôler la façon dont leurs pages sont stockées en mémoire RAM ou sur disque. C’est le cas notamment des processus qui manipulent des clés cryptographiques. Pour des raisons de sécurité, il est préférable que ces clés ne soient pas sauvegardées sur le disque dur. Pour des raisons de performances, certains processus préfèrent également éviter que leurs pages ne soient stockées sur disque dur. Linux comprend plusieurs appels systèmes qui permettent à un processus d’influencer la stratégie de remplacement des pages du noyau.
#include <sys/mman.h>
int mlock(const void *addr, size_t len);
int munlock(const void *addr, size_t len);
int mlockall(int flags);
int munlockall(void);
L’appel système mlock(2) permet de forcer un ensemble de pages à rester en mémoire RAM tandis que munlock(2) fait l’inverse. L’appel système mlockall(2) quant à lui permet à un processus de demander que tout l’espace d’adressage qu’il utilise reste en permanence en mémoire RAM. mlockall(2) prend comme argument des drapeaux. Actuellement deux drapeaux sont supportés. MCL_CURRENT indique que toutes les pages actuellement utilisées par le processus doivent rester en mémoire. MCL_FUTURE indique que toutes les pages qui seront utilisées par le processus devront être en mémoire RAM au fur et à mesure de leur allocation. L’appel système madvise(2) permet également à un processus de donner des indications sur la façon dont il utilisera ses pages dans le futur.
Ces appels systèmes doivent être utilisés avec précaution. En forçant certaines de ses pages à rester en mémoire, un processus perturbe le bon fonctionnement de la mémoire virtuelle, ce qui risque de perturber les performances globales du système. En pratique, en dehors d’applications cryptographiques et de processus avec des exigences d’exécution en temps réel dont la description dépasse le cadre de ce cours, il n’y a pas d’intérêt à utiliser ces appels système.
L’utilisation de la mémoire influence fortement les performances des processus. Plusieurs utilitaires sous Linux permettent de mesurer la charge d’un système. Certains offrent une interface graphique. D’autres, comme top(1) ou vmstat(8) s’utilisent directement depuis un terminal. La commande vmstat(8) permet de suivre l’évolution de la charge du système et de la mémoire virtuelle.
$ vmstat 5
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
3 0 662260 259360 49044 583808 0 0 1 1 1 2 5 0 95 0 0
3 0 662260 259352 49044 583808 0 0 0 0 6018 4182 61 0 39 0 0
7 1 662260 254856 49044 587328 0 0 0 0 6246 4309 61 0 38 2 0
4 0 662260 221668 49044 608652 0 0 0 0 9731 5520 62 1 9 28 0
3 0 662260 260368 49044 583836 0 0 0 2 8291 4868 70 1 12 17 0
4 0 662260 260548 49044 583836 0 0 0 0 6042 4174 61 0 39 0 0
3 0 662260 260720 49044 583836 0 0 0 0 6003 4242 61 0 39 0 0
Lorsqu’elle est utilisée, la commande vmstat(8) retourne de l’information sur l’état du système. Dans l’exemple ci-dessus, elle affiche cet état toutes les 5 secondes. La sortie de vmstat(8) comprend plusieurs informations utiles.
- la colonne procs reprend le nombre de processus qui sont dans l’état Running ou Blocked.
- la colonne memory reprend l’information relative à l’utilisation de la mémoire. La colonne swpd est la quantité de mémoire virtuelle utilisée. La colonne free est la quantité de mémoire RAM qui est actuellement libre. Les colonnes buff et cache sont relatives aux buffers et à la cache qui sont utilisés par le noyau.
- la colonne swap reprend la quantité de mémoire qui a été transférée sur le disque (so) ou lue du disque (si)
- la colonne io reprend le nombre de blocs lus du disque (bi) et écrits (bo)
- la colonne system reprend le nombre d’interruptions (in) et de changements de contexte (cs)
- la dernière colonne (cpu) fournit des statistiques sur l’utilisation du cpu
Enfin, notons que l’appel système getrusage(2) peut être utilisé par un processus pour obtenir de l’information sur son utilisation des ressources du système et notamment les opérations de transfert de pages entre le mémoire RAM et les dispositifs de stockage.
execve(2) et la mémoire virtuelle¶
Pour terminer ce survol de la mémoire virtuelle, il est intéressant de revenir sur le fonctionnement de l’appel système execve(2). Celui-ci permet de remplacer l’image mémoire du processus en cours d’exécution par un exécutable chargé depuis le disque. L’appel système execve(2) utilise fortement la mémoire virtuelle. Plutôt que de copier l’entièreté de l’exécutable en mémoire, il se contente de créer les entrées correspondants au segment de code et aux variables globales dans la table des pages du processus. Ces entrées pointent vers le fichier exécutable qui est sauvegardé sur le disque. En pratique, celui-ci est découpé en deux parties. La première contient les instructions. Celles-ci sont mappées sous forme de pages sur lesquelles le processus a les permissions d’exécution et de lecture. La seconde partie du fichier correspond à la zone data, contenant les variables globales. Celle-ci est mappée dans des pages qui sont accessibles en lecture et en écriture. En pratique, la technique du copy-on-write est utilisée pour ne créer une copie spécifique au processus que si celui-ci modifie certaines données en mémoire. Ensuite, les pages relatives au heap et au stack peuvent être créées.
La sortie ci-dessous présente le contenu de /proc/PID/maps lors de l’exécution du programme /MemoireVirtuelle/src/cp2.c présenté plus haut. Celui-ci utilise deux fichiers mappés en mémoire avec mmap(2). Ceux-ci apparaissent dans la table des pages du processus, tout comme l’exécutable. Au niveau des permissions, on remarquera que le fichier source est mappé avec des pages en lecture seule tandis que le fichier destination est mappé en lecture/écriture.
$ cat /proc/29039/maps
00400000-004ab000 r-xp 00000000 00:19 49479785 /etinfo/users2/obo/sinf1252/SINF1252/2012/S12/src/cp2.exe
006ab000-006ac000 rw-p 000ab000 00:19 49479785 /etinfo/users2/obo/sinf1252/SINF1252/2012/S12/src/cp2.exe
006ac000-006af000 rw-p 00000000 00:00 0
00bc7000-00bea000 rw-p 00000000 00:00 0 [heap]
7fc43d5e4000-7fc43d6a4000 rw-s 00000000 00:19 51380745 /etinfo/users2/obo/sinf1252/SINF1252/2012/S12/src/t
7fc43d6a4000-7fc43d764000 r--s 00000000 00:19 49479785 /etinfo/users2/obo/sinf1252/SINF1252/2012/S12/src/cp2.exe
7fff5b912000-7fff5b927000 rw-p 00000000 00:00 0 [stack]
7fff5b9ff000-7fff5ba00000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
Footnotes
| [1] | En pratique, les adresses sur le disque dur ne sont pas stockées dans le MMU mais dans une table maintenue par le système d’exploitation. C’est le noyau qui est responsable des transferts entre le dispositif de stockage et la mémoire RAM. |
| [2] | Cette technique est utilisée dans les systèmes d’exploitation récents pour éviter qu’un problème de buffer overflow sur le stack ne conduise à l’exécution d’instructions qui ne font pas partie du processus. |
| [3] | Source : http://www.intel.com/content/www/us/en/solid-state-drives/ssd-320-specification.html |
| [4] | Source : http://www.seagate.com/staticfiles/support/disc/manuals/desktop/Barracuda%207200.11/100507013e.pdf |
| [5] | Une entrée de la table de pages occupe généralement 32 ou 64 bits suivant les architectures de processeurs. |
| [6] | Il est possible d’obtenir la taille des pages utilisée sur un système via les appels sysconf(3) ou getpagesize(2) |