Mise en œuvre des systèmes de fichiers¶
Nous avons vu dans les sections précédentes comment un système d’exploitation comme UNIX permettait un accès et une interface unifiés aux périphériques de stockage via le système de fichier.
De nombreuses mises en œuvre de systèmes de fichiers existent. Elles répondent à des besoins différents en terme de performance ou de fiabilité, et visant des technologies de stockage variées. Par exemple, un système de fichier pour le stockage sur bande magnétique à très grande capacité, utilisées pour de l’archivage de données à long terme, sera l’objet de choix de conception très différents de ceux faits pour un système de fichiers généralistes destiné à héberger le système d’exploitation, les logiciels, et les données d’un utilisateur de machine personnelle sur un disque dur ou un SSD. Dans le cas d’un stockage sur bande, le système de fichier doit prendre en compte le fait que l’accès se fait de façon strictement linéaire (la bande magnétique est déroulée devant une tête de lecture), et que l’objectif est de maximiser la performance d’écriture des archives, si nécessaire au détriment de la rapidité d’accès à un fichier en particulier. Dans le cas d’un système de fichiers généraliste en revanche, il est nécessaire de supporter de manière efficace des accès aléatoires à des fichiers et répertoires, tout en conservant des performances correctes pour les accès linéaires à de grands fichiers.
Nous allons explorer dans cette section des éléments de mise en œuvre des systèmes de fichiers en nous concentrant sur le cas des systèmes de fichiers généralistes utilisés dans les systèmes UNIX et en particulier le système de fichier ext4. Ce système de fichier est le plus couramment utilisé par les distributions de Linux.
Organisation d’un disque et des partitions¶
Chaque périphérique de stockage (disque, clé USB, etc.) est géré par un gestionnaire de périphérique spécifique, associé à un driver de périphérique. Ces deux éléments forment l’interface entre le matériel et le logiciel, pilotée par le kernel du système d’exploitation. Les différents périphériques de stockage ont des organisations physiques très différentes. La figure suivante présente l’exemple d’un disque dur.
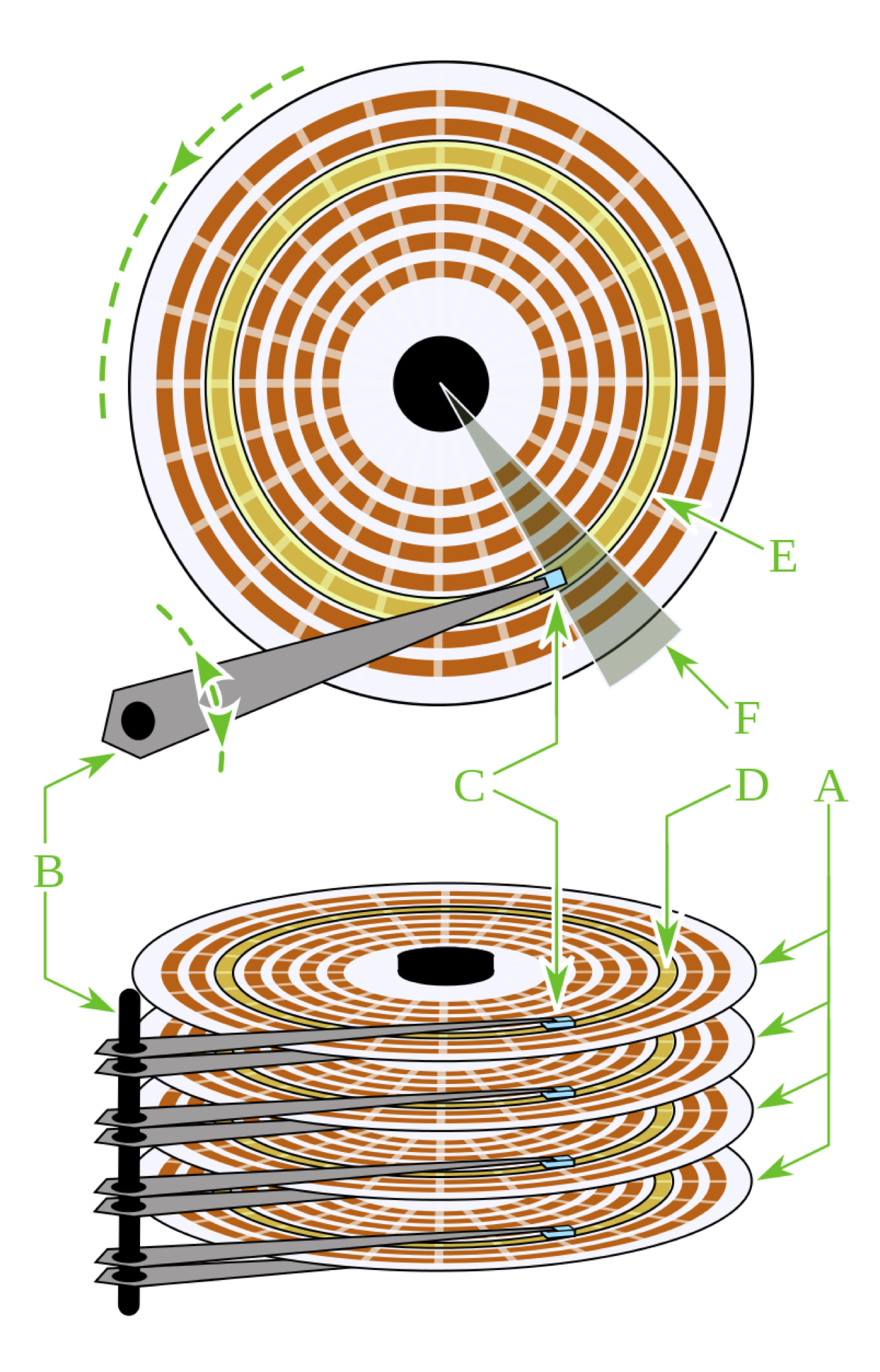
Structure d’un disque dur. Crédits : Wikimedia / Domaine public
Un disque dur est formé de plusieurs plateaux (A), qui sont des disques rotatifs sur lesquels une tête de lecture/écriture (C) peut lire ou écrire des données en agissant sur la polarisation magnétique de la surface du matériau. Le plus souvent, les deux faces d’un même plateau sont utilisées. L’écriture sur chaque se fait sur des pistes concentriques (E) et chaque piste est divisée en secteurs (F).
Différents disques durs auront des caractéristiques différentes comme leur nombre de plateau ou de têtes de lecture/écriture. Il en va de même pour un périphérique de stockage de type SSD, utilisant des puces de mémoire non volatile (mémoire flash) dont la disposition et la configuration peut différer de manière importante d’un modèle à l’autre.
L’utilisation d’un driver et d’un contrôleur de périphérique, mais aussi de l’électronique de gestion embarquée du disque dur ou du SSD permet toutefois au système d’exploitation de ne pas avoir à gérer directement ces notions spécifiques de plateau, secteur, pistes, ou de puces de mémoire flash, lors de la lecture ou de l’écriture de données. À la place, un périphérique de stockage est vu comme une suite de secteurs contigües, formant un espace d’adressage linéaire. Une taille typique de secteur pour un disque dur est de 512 octets, tandis qu’un SSD présente souvent les données stockées à une granularité de 4 Kilo-octets. Nous ne ferons pas de distinction entre disque dur et SSD dans la suite du chapitre, et utiliserons l’appellation générique de “disque” pour couvrir les deux types de périphériques de stockage.
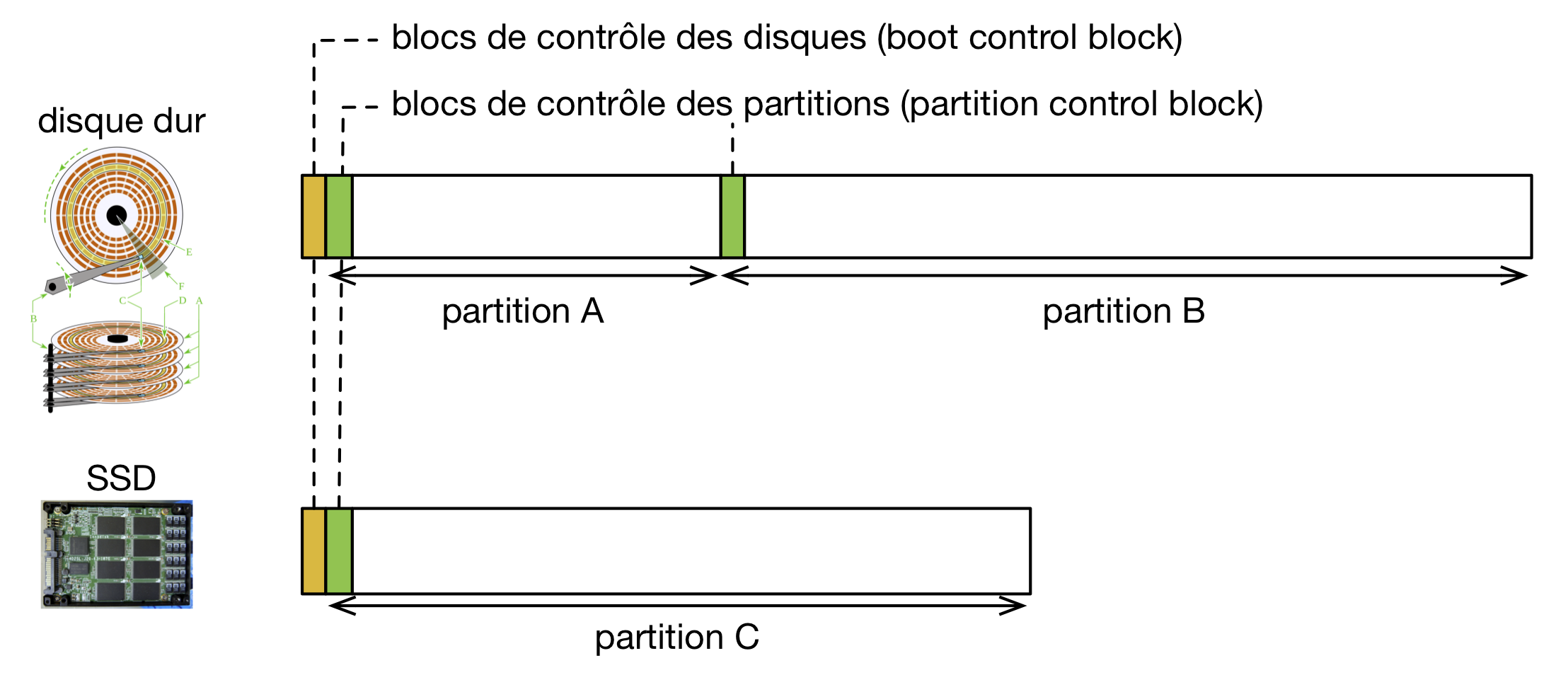
Disques, partitions et blocs de contrôle.
Un disque comporte toujours une zone de démarrage permettant de stocker des métadonnées utile pour sa gestion. Ce bloc de contrôle du disque est souvent appelé en anglais boot control block car un de ses rôles principaux est de contenir, à une adresse fixe, le code de démarrage du système d’exploitation lorsque ce disque joue le rôle de disque de démarrage (les gestionnaires de démarrage comme grub permettent de démarrer des systèmes d’exploitation différents stockés sur des partitions différentes du même disque ou sur des disques différents). Outre ce code de démarrage, ce bloc de contrôle contient la liste des partitions du disque. Chaque partition peut stocker des données en utilisant un système de fichier différent. Sur notre exemple, le disque SSD ne contient qu’une partition, tandis que le disque dur en contient deux. La partition C sur le disque SSD pourrait, par exemple, utiliser le système de fichiers ext4, la partition A sur le disque dur être utilisée comme espace de swap pour le système de gestion de la mémoire virtuelle, et la partition B utiliser le système de fichiers ExFAT. Chaque partition démarre par son propre bloc de contrôle. Le rôle de ce bloc de contrôle est de contenir les métadonnées nécessaires pour réaliser l’opération de montage du système de fichier contenu dans la partition. Sa structure est spécifique au système de fichier utilisé, mais des informations classiques y figurant incluent l’organisation de l’index des fichiers ou de l’index de l’espace libre, ou encore une indication sur le fait que ls système de fichier a été démonté proprement ou non lors de sa dernière utilisation. Nous reviendrons sur l’ensemble de ces notions au cours de notre exploration de la mise en œuvre d’un système de fichier qui suit.
Note
Le cas de la partition de swap
Nous avons vu dans la section consacrée à la mémoire virtuelle qu’une partition de swap pouvait être crée avec mkswap(8) et activée avec swapon(8). La partition de swap ne contient pas à proprement parler de système de fichier. Elle est traitée comme un grand espace uniforme par le système d’exploitation pour y stocker les copies des pages mémoire évincées par l’algorithme de remplacement de page. La partition de swap est scindée en autant de cadres de pages que possible (par exemple, de 4 Ko sur les systèmes de la famille x86 comme IA-32). Seul le premier cadre de page est utilisé pour stocker les métadonnées permettant l’utilisation de la partition de swap.
Structure du système de fichiers¶
Un système de fichier divise toujours l’espace de stockage disponible en un nombre de blocs. Souvent, la taille de ces blocs est la même que la taille des pages mémoires utilisées par le système, e.g., 4 Ko sur x86. Nous considérerons ici uniquement le cas de blocs de taille fixe. Un fichier occupe toujours un nombre entier de blocs, même si sa taille est inférieure à un multiple de la taille de ces blocs. Par exemple, un fichier de 100 octets occupera au moins un bloc (4 Ko = 4.096 octets) et un fichier de 16.500 octets occupera au moins 4 blocs (16Ko ou 16.536 octets). L’espace perdu est nommé la fragmentation interne, suivant la même définition que celle utilisée lors de la description des algorithmes de gestion dynamique de la mémoire dynamique.
On doit conserver, pour chaque fichier, la liste des blocs qu’il occupe. Des méta-données supplémentaires sont par ailleurs nécessaires pour permettre le contrôle d’accès (identifiant du propriétaire et du groupe du fichier, bits de permission, etc.) ou pour y collecter des métriques informatives à l’intention des utilisateurs et administrateurs du système (e.g., la date de la dernière écriture ou celle du dernier accès), comme nous l’avons vu au chapitre précédent.
Outre la liste des blocs de données associées à chaque fichier, il est nécessaire de maintenir la liste des blocs libres. Cette liste permet de réserver des blocs pour de nouveaux fichiers, ou pour étendre des fichiers existants.
Utilisation d’une table d’allocation des fichiers¶
Il existe deux grandes approches pour gérer le stockage des métadonnées et des listes de blocs. La première approche est représentée par les systèmes FAT (File Allocation Table) et ses successeurs (FAT32, ExFAT). Elle utilise une unique table d’allocation dédiée (d’où le nom FAT qui reprend cette notion de table) pour stocker les identifiants des blocs occupés par chaque fichier. Un fichier est identifié par un numéro unique, utilisé comme index dans cette table (on rappelle que l’association entre un nom de fichier en toute lettres, tel que manipulé par l’utilisateur ou un programme, est actée par l’existence d’une entrée dans un répertoire). L’entrée correspondant au numéro du fichier dans la table contient alors, outre les métadonnées, l’identifiant du premier bloc du fichier. On peut alors considérer deux approches pour stocker la liste des blocs associés à un fichier. Elles sont illustrées par la figure suivante.
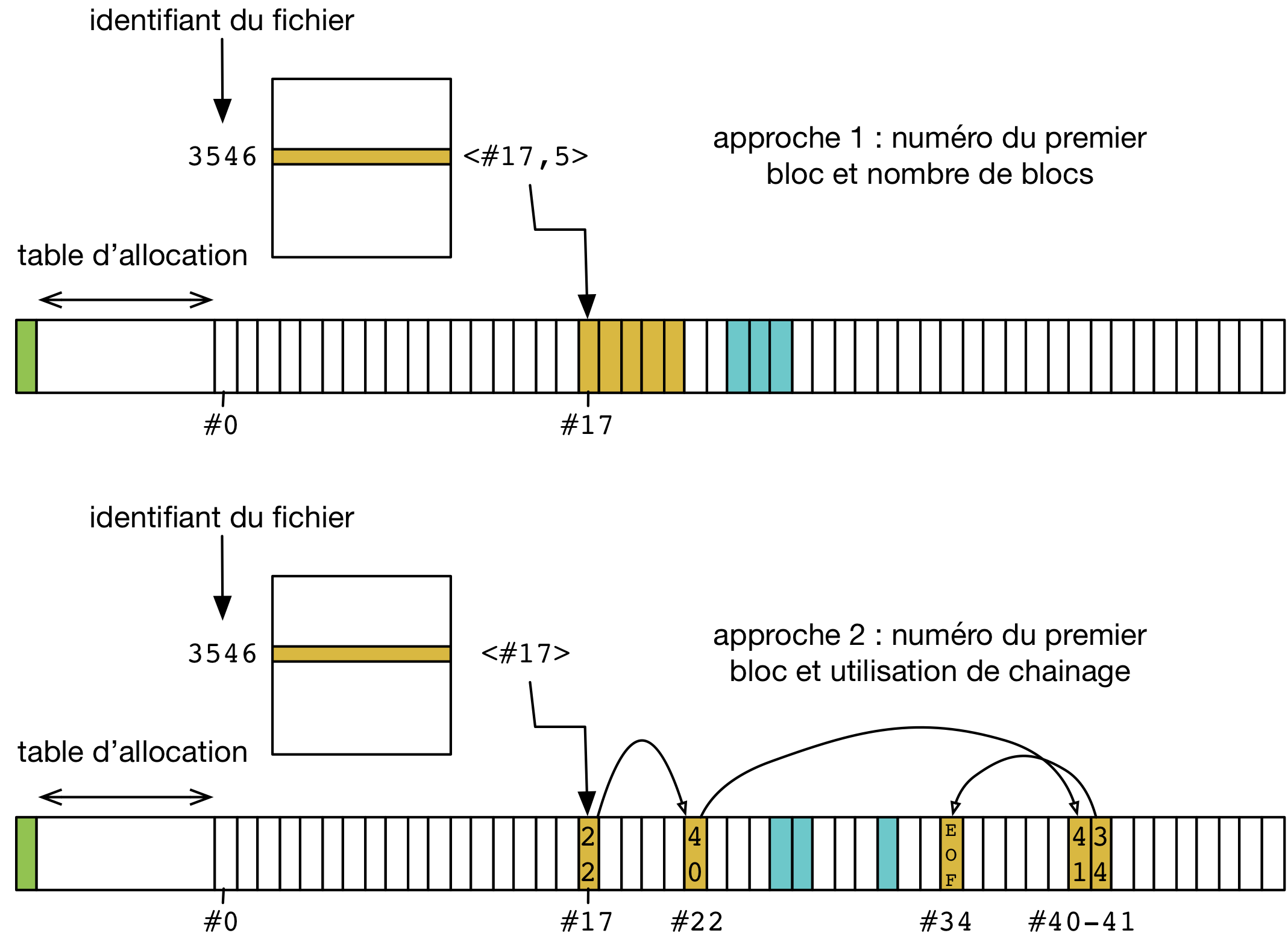
Utilisation d’une table d’allocation et deux approches pour la conservation de la liste des blocs pour un fichier.
- Une première approche consiste à stocker dans l’entrée de la table correspondant au fichier l’identifiant du premier bloc et le nombre de blocs contigües occupés par le fichier. Outre sa simplicité, cette méthode a l’avantage de garantir que le fichier sera stocké sur des zones consécutives du disque. Particulièrement pour les disques dur (dispositifs mécaniques) cela permet d’assurer qu’un minimum de mouvements de la tête de lecture/écriture seront nécessaires pour lire le fichier de façon linéaire. Par contre, cette approche comporte deux désavantages :
- Tout d’abord, il n’est pas toujours possible d’augmenter la taille du fichier sans procéder à une coûteuse copie du fichier à un autre endroit du disque. Par exemple, on peut augmenter la taille du fichier jaune sur la partie haute de la figure de deux blocs seulement. Pour augmenter d’avantage sa taille, en revanche, il devient nécessaire de copier tous les blocs de ce fichier dans une zone libre différente sur le disque avant de pouvoir réaliser l’extension.
- Ensuite, cette approche tend à créer une importante fragmentation externe, c’est à dire de l’espace libre perdu entre des zones occupées, sans qu’il soit possible d’aménager la place nécessaire pour un grand fichier en une seule zone contigüe. Ce problème est similaire au problème de fragmentation externe rencontré par les gestionnaires de mémoire dynamique, et est illustré dans le chapitre correspondant.
- Une seconde approche est d’utiliser un chaînage entre les blocs formant le fichier. L’entrée de la table d’allocation pour un fichier ne contient alors que l’identifiant du premier bloc de ce fichier. Chaque bloc du fichier est utilisé pour stocker les données à l’exception d’une petite zone qui contient l’identifiant du prochain bloc (ou la valeur EOF, pour end of file, signifiant la fin du fichier). L’accès au fichier se fait en parcourant la liste chaînée de ses blocs. L’avantage de cette approche est que la taille du fichier n’est pas limitée par autre chose que l’espace disponible sur le disque. Par contre, outre sa plus grande complexité de mise en œuvre, elle présente elle aussi deux désavantages :
- Premièrement, il faut éviter de stocker les fichiers sur des blocs éparpillés sur le disque (non contigües), bien que le stockage chaîné de la liste des blocs le permette. En effet, l’éparpillement aura un impact important sur la performance, nécessitant des mouvements supplémentaires de la tête de lecture/écriture pour un disque dur et ne permettant pas de tirer partie de la grande granularité de lecture/écriture pour un disque dur ou un SSD. Il faut, en d’autres termes, privilégier la localité dans les allocations de blocs pour un même fichier.
- Deuxièmement, cette approche n’est pas adaptée pour des accès aléatoires au contenu des fichiers, c’est à dire à une adresse quelconque, car elle nécessite alors de lire et parcourir l’ensemble du fichier jusqu’au bloc désiré afin de suivre les informations de chaînage.
Les systèmes de fichiers de la famille FAT combinent en réalité ces deux approches. Les fichiers sont placés sur des zones (groupes de blocs) contigües et la table ne contient que l’identifiant du premier bloc. Toutefois, le dernier bloc de cette zone peut contenir un pointeur vers une nouvelle zone (un nouveau groupe de bloc) dans le cas où le fichier doit croître au delà de ce qui est possible en étendant le bloc existant. Cette approche hybride permet de combiner les avantages des deux approches discutées. Toutefois, elle ne règle pas le problème de la propension à la fragmentation externe et à l’éparpillement de ce type de système de fichiers : si un grand nombre de fichiers sont créés, supprimés, ou voient leur taille changer au cours du temps, et si le disque est fort rempli, alors les fichiers ont tendance à occuper de nombreuses petites zones éparpillées et la performance est sévèrement réduite.
Les systèmes FAT (et leurs successeurs comme NTFS) ont, outre leur simplicité, a leur avantage que l’espace utilisé pour stocker les métadonnées (la table d’allocation) est réduit au minimum nécessaire. Le reste du disque peut être utilisé pour stocker les données elles-mêmes.
Note
Utilisation d’un défragmenteur
Au contraire de la mémoire dynamique, il est possible d’agir pour réduire la fragmentation externe d’un système de fichier et pour augmenter la localité (i.e., le fait que les blocs pour un même fichier soient le plus possible contigües sur le disque).
Un appel à malloc(3) renvoie une adresse en mémoire qui est utilisée ensuite par l’application. Une fois que l’appel à malloc(3) a renvoyé cette adresse, il n’est plus possible de la modifier. L’algorithme de gestion de mémoire dynamique ne peut donc plus agir a posteriori pour diminuer la fragmentation externe, c’est à dire récupérer de l’espace perdu sous forme de “trous” entre des zones allouées mais non libérées.
L’association entre un numéro de fichier (dans la table d’allocation) et le placement sur le disque n’est jamais exposé directement aux applications, et n’a donc pas besoin d’être définitif. Il est donc tout à fait possible de modifier le placement des blocs du fichier dynamiquement, sans que ce changement ne soit visible par le reste du système d’exploitation et par les applications. Les systèmes d’exploitation de la famille Windows incluent ainsi un utilitaire système appelé le “défragmenteur” (defrag en anglais), s’appliquant aux systèmes de fichiers FAT et NTFS. Son objectif est d’appliquer un algorithme d’optimisation, regroupant les fichiers en des zones de blocs contigües uniques par des opérations de déplacement, augmentant ainsi leur localité et la performance de leurs accès. Cet utilitaire récupére par ailleurs l’espace perdu par la fragmentation externe en groupant ces zones en une zone unique, sans espace vide intermédiaire. Un nom plus exact pour cet outil serait donc le “rapprocheur/défragmenteur” ... On notera que l’utilisation d’un tel outil est rarement nécessaire pour les systèmes de fichiers utilisés sous UNIX comme ext4, qui prennent des mesures pour corriger le problème de façon dynamique lors des opérations d’écriture.
Stockage indexé¶
Une deuxième approche pour stocker la liste des blocs occupés par un fichier est d’utiliser directement un bloc complet comme bloc d’index vers des blocs de données. Ainsi, il n’y a plus de spécialisation de zone du disque pour stocker d’un côté les métadonnées et de l’autre les données. C’est l’approche qui est suivie par les systèmes de fichiers les plus courants sous UNIX et Linux, comme ext3, ext4, etc. Elle est illustrée par la figure suivante.
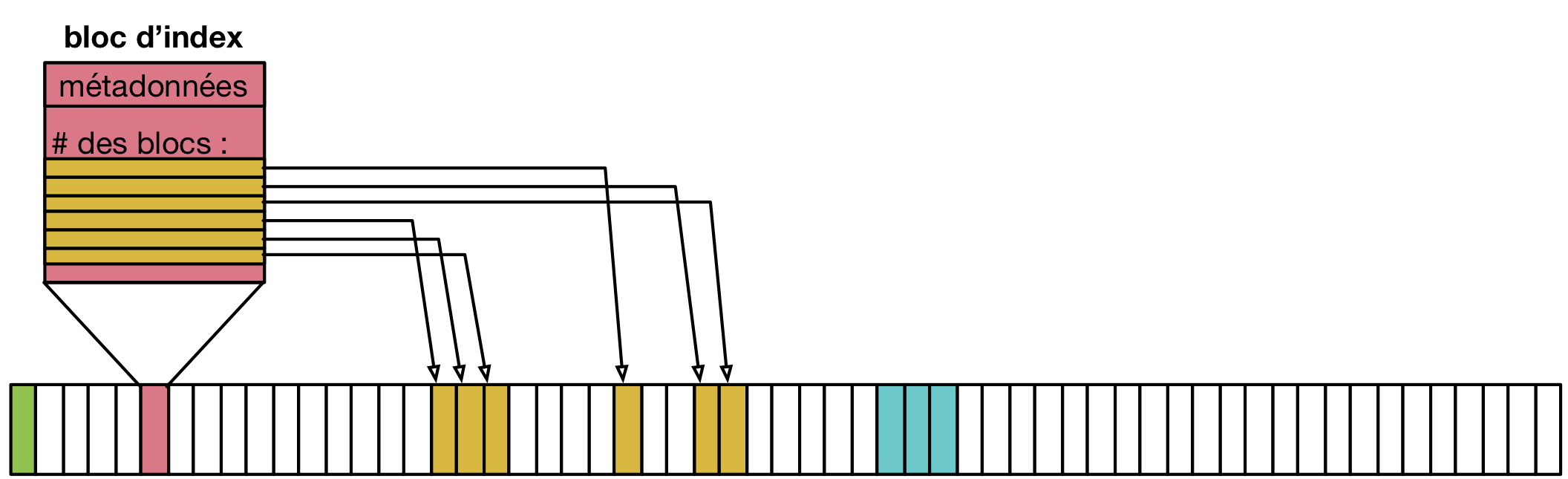
Principe de l’indexation des blocs d’un fichier dans un inode occupant lui même un des blocs du disque.
Dans cet exemple, le bloc rose sert d’index pour le fichier. Il contient directement les métadonnées (propriétaire du fichier, groupe, etc.) et une liste de numéros des blocs jaunes formant le contenu du fichier.
Un premier avantage de cette approche est qu’il n’est pas nécessaire de limiter à l’avance le nombre maximal de fichiers en choisissant une taille pour la table d’indexation : il est possible de stocker des nouveaux fichiers tant qu’il existe au moins deux blocs libres, un pour les bloc d’index et un pour les données (voir aucun si le fichier est vide, e.g. il a été créé en utilisant touch(1)).
Un désavantage est que l’espace nécessaire pour tout fichier est toujours augmenté d’un bloc (par exemple de 4 Ko) ce qui est largement plus volumineux qu’une entrée dans une table d’indexation. Un fichier même très petit occupera donc au moins deux blocs : un fichier de 18 octets contenant uniquement la chaîne “Bonjour LINFO1252” occuperait ainsi deux blocs de 4 Ko sur le disque, soit un total de 8 Ko.
L’utilisation de blocs d’index indexant individuellement chaque bloc de données résout les problèmes de fragmentation externe, chaque bloc pouvant être utilisé même s’il est isolé, mais comme pour l’indexation avec une liste chaînée, peut amener à un éparpillement des blocs en particulier lorsque le disque est très rempli.
L’utilisation d’un bloc d’index unique a par ailleurs pour effet de limiter la taille maximale d’un fichier. Le nombre d’identifiants de blocs de donnée que l’on peut stocker dans ce bloc d’index est effectivement limité par la taille d’un bloc. Par exemple, si on sait stocker 800 index vers des blocs de données dans le bloc d’index, à la suite des métadonnées, alors la taille maximale d’un fichier sera de 800x 4 Ko soit un peu plus de 3 Mo.
Système de fichiers ext4¶
Le système de fichiers ext4 est le plus couramment utilisé sous Linux. Ce système de fichiers utilise une approche hybride entre les solutions discutées précédemment. Des blocs d’index appelés inodes contiennent les métadonnées associées aux fichiers ainsi que la liste des blocs de données. Une partition est scindée en groupes de blocs. Dans chacun de ces groupes, une zone est réservée pour stocker les inodes. Le reste est formé de blocs de données. L’avantage de la scission en groupes de blocs est de ne pas stocker trop loin sur le disque les métadonnées et les données correspondantes, pour ainsi éviter des va-et-vient trop important des têtes de lecture/écriture. Le stockage des inodes dans une zone spéciale permet de les limiter à une taille fixe plus réduite que celle d’un bloc complet. Le système ext4 supporte, par ailleurs, des tailles de blocs de données variables. Une description complète de ext4 sort du contexte de ce cours, mais la manière dont celui-ci résout le problème de la limitation du nombre d’entrées vers des blocs de données dans un inode est intéressante à étudier.
Dans ext4, et dans d’autres systèmes de fichiers pour UNIX avant lui, un inode contient un nombre limité de liens directs vers des blocs de données. Une configuration standard est de 12 liens “directs” de ce type. En utilisant seulement ces liens directs, et avec une taille de bloc de 4 Ko, cela indique qu’un fichier peut être d’une taille maximum de 12x4=48 Ko. La structure de l’inode permet d’utiliser des liens supplémentaires et donc des fichiers plus volumineux en utilisant plusieurs niveaux d’indirections. On compte trois niveaux d’indirection (simple, double, et triple), comme illustré sur la figure suivante.
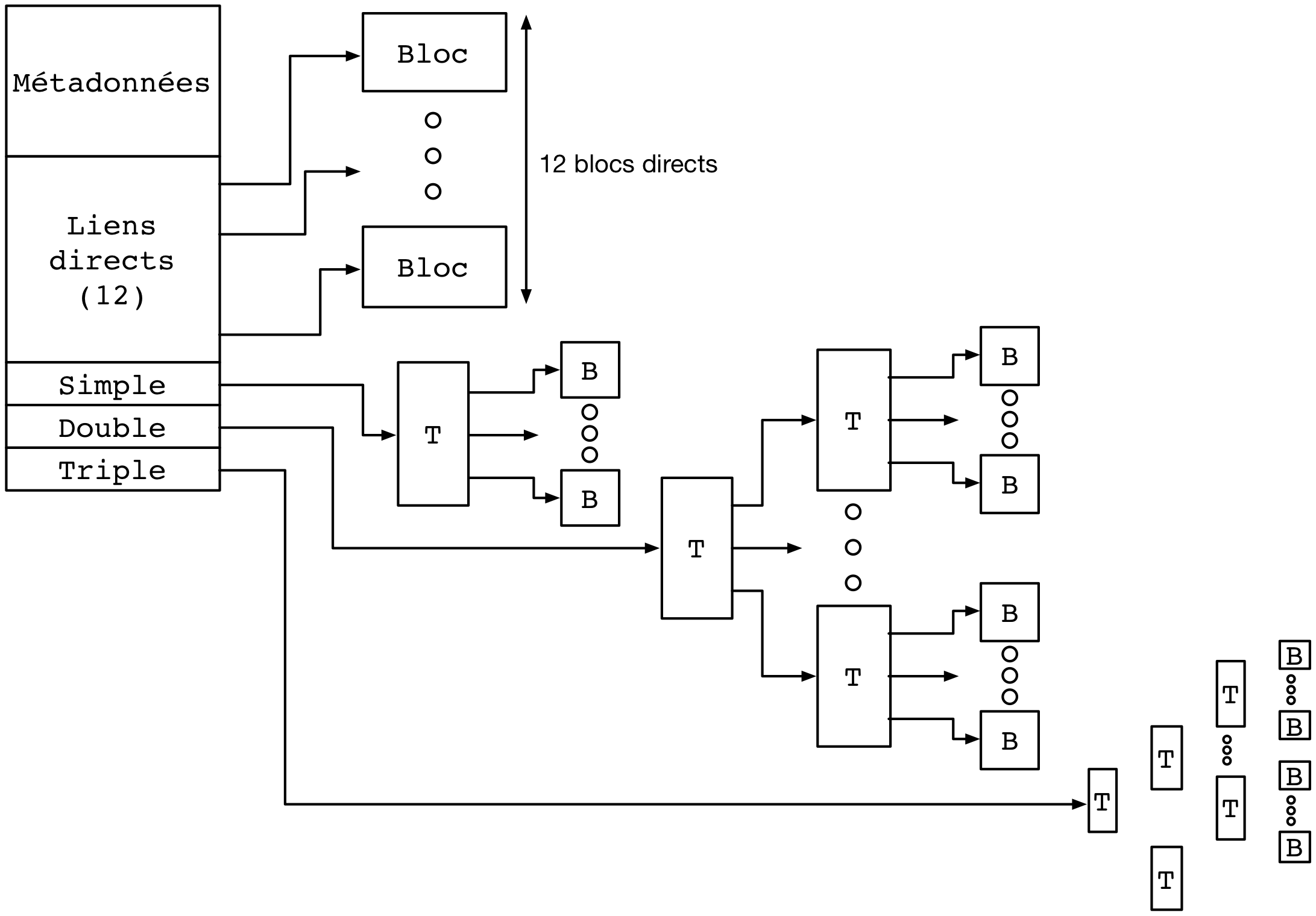
Différents niveaux d’indirections pour supporter des grands fichiers à partir d’un inode de taille fixe.
Le premier pointeur d’indirection pointe vers un bloc d’index supplémentaire (choisi parmi les blocs de données) dont le contenu sera des numéros de blocs de données formant le contenu du fichier (premier niveau d’indirection). Si un bloc de données a une taille de 4 Ko et que chaque numéro de bloc occupe 4 octets, alors un total de 4 Mo (1.024 blocs de 4 Ko) pourra être indexé par ce bloc, en plus des 48 Ko indexés par les liens directs. Avec deux niveaux d’indirection, le pointeur dans l’inode pointe vers un bloc contenant lui même les identifiants de blocs d’index. En utilisant les mêmes paramètres, le fichier peut contenir 4 Go de données supplémentaires. Le même principe est applicable avec un troisième niveau d’indirection, permettant d’atteindre une taille de fichier maximale de 4 To + 4 Go + 4 Mo + 48 Ko.
Stockage des répertoires¶
Un répertoire dans un système de fichier comme ext4 est stocké de la même manière qu’un fichier, à ceci près qu’un indicateur (le flag b dans les métadonnées) est mis à vrai, et que le bloc de données associés à l’inode comprendra alors une liste de structures de données dirent. Ces structures contiennent l’association entre des noms de fichiers et sous-répertoires et les inodes correspondants. Lorsque le nombre d’entrées dirent dans le répertoire dépasse la capacité d’un bloc, des blocs accessibles via les niveaux d’indirection sont utilisés, tout comme pour les fichiers. On notera que ext4 utilise une optimisation qui est de stocker directement dans l’inode du répertoire les entrées dirent lorsque leur nombre est très petit, évitant ainsi d’utiliser un bloc pour peu de données.
Gestion de l’espace libre¶
Il est nécessaire de conserver la liste des blocs disponibles afin de pouvoir rapidement réserver de l’espace pour la création d’un nouveau fichier ou l’accroissement de la taille d’un fichier existant. Bien entendu, cette information pourrait être retrouvée en passant en revue l’ensemble des inodes valides (i.e., accessibles depuis une entrée d’un répertoire lui même accessible depuis la racine du système de fichier) mais effectuer cette opération de recherche à chaque montage du système de fichier pour créer la structure de donnée correspondante en mémoire aurait un coût prohibitif. De plus, la taille de la structure de donnée résultante peut vite être très importante et occuper beaucoup d’espace. Avec un disque de 4 To et des blocs de 4 Ko, on peut estimer le nombre de bits nécessaires (si chaque bit représente si un bloc est ou non disponible) à 1.073.741.824, soit 128 Mo. Cette structure de donnée (un champ de bit) est donc stockée sur le disque lui-même. Dans le système ext4, chaque groupe de bloc inclue une zone réservée pour stocker ce “bitmap” des blocs libres.
Bien entendu, différents algorithmes existent pour choisir la zone la plus adéquate pour créer un nouveau fichier, en évitant si possible la fragmentation et en essayant de maximiser la localité. Leur description dépasse le contexte de ce cours, mais on retrouve des similarités entre ces algorithmes et ceux utilisés pour la gestion dynamique de la mémoire que nous avons abordé précédemment.
Note
Mon fichier est-il vraiment effacé ?
L’effacement d’un fichier avec la commande rm(1) consiste simplement en l’effacement de l’inode qui pointe vers ses blocs de contenu. Les blocs de contenu sont alors déclarés comme libres et pourront être réutilisés pour la création de nouveaux fichiers. Sauf précaution particulière, le contenu des blocs de données n’est pas modifié.
Des logiciels spécifiques permettent de passer en revue l’ensemble des blocs de données libres pour détecter des fichiers complets effacés, qui n’auraient pas encore été recouverts par le contenu de nouveaux fichiers. Ils se basent sur cela, entre autres, sur l’analyse des caractéristiques de fichiers classiques (fichiers d’images, vidéos, etc.). Ils sont utilisés par exemple par les forces de police pour recouvrer des preuves que des criminels n’ayant pas suivi LINFO1252 auraient tenté d’effacer avec un simple rm(1). Des administrateurs systèmes peuvent aussi utiliser des outils comme extundelete sur une version montée en lecture seule d’un système de fichier, pour recouvrer des fichiers effacés par mégarde (il n’y a pas de notion de corbeille en ligne de commande, contrairement à ce que l’on peut trouver dans un environnement graphique).
Si on souhaite effacer un fichier de façon permanente, c’est à dire en modifiant ses blocs de données plusieurs fois en y écrivant des données aléatoires (ou bien des 0 partout), il est possible d’utiliser l’utilitaire shred(1). Celui-ci permet de spécifier le nombre de passes d’écritures souhaitées sur les données. En effet, dans certains cas une seule passe n’est pas suffisante, en tout cas sur un disque dur. Avec du matériel spécialisé, il est possible de retrouver avec un probabilité qui décroit au fur et à mesure des écritures ultérieures, la polarisation passée d’un bit stocké sur le disque. L’exemple ci-dessous montre l’utilisation de shred(1) pour effacer définitivement un fichier sensible. L’option -v permet d’obtenir une sortie “verbeuse” détaillant les étapes des opérations. L’option -n permet de spécifier le nombre de passes d’effacement à effectuer. On voit ici que shred(1) alterne entre l’écriture de valeurs aléatoires, de 0, et de 1. L’option -z permet de demander l’écriture de 0 à la fin, pour rendre moins détectable l’opération d’effacement. On voit par ailleurs que l’utilitaire renomme de nombreuses fois le fichier, afin de faire disparaître l’entrée du contenu du répertoire.
$ cat ma_carte_de_credit Linus Torvalds Aktia Savings Bank 1234 5678 9123 4567 EXP 01/21 CRC 123 $ shred -vzu -n 5 ma_carte_de_credit shred: ma_carte_de_credit: pass 1/6 (random)... shred: ma_carte_de_credit: pass 2/6 (000000)... shred: ma_carte_de_credit: pass 3/6 (random)... shred: ma_carte_de_credit: pass 4/6 (ffffff)... shred: ma_carte_de_credit: pass 5/6 (random)... shred: ma_carte_de_credit: pass 6/6 (000000)... shred: ma_carte_de_credit: removing shred: ma_carte_de_credit: renamed to 000000000000000000 shred: 000000000000000000: renamed to 00000000000000000 shred: 00000000000000000: renamed to 0000000000000000 shred: 0000000000000000: renamed to 000000000000000 shred: 000000000000000: renamed to 00000000000000 shred: 00000000000000: renamed to 0000000000000 shred: 0000000000000: renamed to 000000000000 shred: 000000000000: renamed to 00000000000 shred: 00000000000: renamed to 0000000000 shred: 0000000000: renamed to 000000000 shred: 000000000: renamed to 00000000 shred: 00000000: renamed to 0000000 shred: 0000000: renamed to 000000 shred: 000000: renamed to 00000 shred: 00000: renamed to 0000 shred: 0000: renamed to 000 shred: 000: renamed to 00 shred: 00: renamed to 0 shred: ma_carte_de_credit: removed
Performance des systèmes de fichiers¶
Les accès aux périphériques de stockage sont particulièrement lents, même en utilisant des technologies SSD et des contrôleurs de périphériques de dernière génération. À titre d’exemple, les latences d’accès à la mémoire principales se comptent en dizaines ou centaines de nano-secondes, tandis que la latence d’accès à un SSD connecté avec un contrôleur de périphérique à la norme NVMe (la plus rapide disponible hors serveurs haute performance) est plutôt de l’ordre de quelques dizaines ou centaines de micro-secondes, soit un rapport de un à mille. La différence en bande passante, elle, est moins importante mais reste d’un facteur de 10 à 20 entre les mémoires un les SSD les plus performants. Un disque dur classique présente quand à lui des latences d’accès de quelques millisecondes, et une bande passante environ 5 à 10 fois moins mois élevée que celle d’un SSD.
L’utilisation du principe de cache permet d’augmenter sensiblement la performance des systèmes de fichier. On retrouve des caches à plusieurs niveaux :
- Tout d’abord, les périphériques de stockage eux-même (et/ou les contrôleurs de périphériques) disposent souvent d’un cache permettant de stocker un petit nombre d’opérations d’écriture en attente, et donc de diminuer la latence de ces opérations du point de vue du système d’exploitation.
- Ensuite, le système d’exploitation utilise une partie de la mémoire pour servir de cache pour les blocs lus et écrits par le système de fichiers. Sous Linux, l’ensemble des pages qui ne sont pas autrement utilisées par les applications sont inclues dans ce “Page Cache” (ou disk cache). Lors de la lecture d’un bloc ou d’un inode par le système de fichier, son contenu est ajouté à une page libre du page cache (si nécessaire, une page ancienne est évincée par l’algorithme de remplacement de page). Les accès en lecture suivants se font alors dans le cache. Les accès en écriture se font eux aussi dans le cache, et son répercutés lors de l’éviction de la page de la mémoire, ou lorsque le processus aura utilisé l’appel système fsync(2).
L’utilisation du page cache facilite la mise en œuvre du mapping des fichiers en mémoire partagé. Les pages correspondant au fichier mappé sont marquées dans la table des pages du processus ayant appelé l’appel système mmap(2), mais ne seront pas rappatriées directement en mémoire physique. Cela aurait peu d’intérêt, en effet, si le processus n’accède in fine qu’à un sous-ensemble du fichier. L’accès à ces pages provoquera des défauts de page qui seront servis en lisant le contenu du fichier au fur et à mesure de son utilisation.
Le page cache permet de mettre en œuvre des optimisations de performance, au delà de pouvoir servir les requêtes pour des données récemment lues sans devoir les relire depuis le disque :
- Le positionnement de la tête de lecture/écriture est généralement une opération beaucoup plus longue que la lecture elle même. Les accès aux fichiers se font par ailleurs le plus souvent de façon linéaire. Il est donc bénéfique de profiter du positionnement de la tête de lecture sur la même piste pour lire plusieurs secteurs en une seule opération. Ainsi, si le bloc de numéro 125 est lu, les blocs 126, 127, etc. seront lus en même temps et l’accès se fera alors directement depuis le page cache. Cette stratégie dite de pré-chargement (prefetching ou read-ahead) est très bénéfique en particulier lorsque la localité des fichiers sur le disque est élevée.
- Il est très commun que la lecture d’un fichier se fasse de façon linéaire, sans jamais revenir en arrière pour relire des données. Dans ce cas, il est possible et même souhaitable d’évincer les copies de pages dont la lecture est complète dès le chargement de la prochaine page (ou ensemble de pages avec le préchargement). Cette stratégie dite free-behind permet d’éviter que des pages qui ne seront plus jamais accédées mais l’ayant été récemment prennent la place de pages plus anciennes mais de plus grande importance.
Note
Le scheduling des accès à un disque dur
Il existe de nombreuses optimisations à différents niveaux de la mise en œuvre des systèmes de fichiers. L’une d’entre elles est l’utilisation d’un scheduling optimisé au niveau du traitement des commandes par le disque dur lui même. Lorsque plusieurs demandes d’accès au disque pour lire ou écrire des blocs sont effectuées de manière concurrente (par différents threads et/ou différents processus) il est rarement optimal de servir ces commandes dans leur ordre d’arrivée : souvent, les blocs seront à des positions éloignées du disque, sur des plateaux différents, ou sur des faces différentes du même plateau. L’opération de déplacement de la tête de lecture écriture, ou le changement de côté du plateau accédé, sont des opérations coûteuses en latence. On parle en anglais de “seek latency”. Il est préférable de ré-ordonner les accès de façon à ce que les mouvements mécaniques du disque soient minimisés. On peut faire un parallèle avec les algorithmes utilisés pour les ascenseurs de très grands immeubles : ceux-ci ne répondent pas aux sollicitations dans l’ordre de l’appui sur les boutons mais bien en cherchant à maximimiser le nombre de personnes transportées, potentiellement en ne respectant pas de mesure d’équité – certains attendent alors plus que d’autres.
Robustesse et vérificateurs de systèmes de fichiers¶
Contrairement à la mémoire principale dont le contenu est effacé lors de l’arrêt de la machine, ce n’est pas le cas d’un périphérique de stockage dont le contenu doit pouvoir être monté de nouveau au prochain démarrage. Il faut évidemment qu’il n’y ait pas d’incohérence entre les différentes informations conservées sur le disque, comme le contenu des inodes, l’association entre les inodes et les blocs de contenu, et surtout la bitmap indiquant les blocs libres. Un scénario particulièrement dommageable est qu’un bloc soit indiqué comme libre alors qu’il est effectivement utilisé par un fichier. Ce bloc pourrait alors être alloué à deux fichiers différents, cassant les propriétés d’isolation (un processus n’ayant pas les droits sur le deuxième fichiers mais sur le premier pouvant voir du contenu appartenant du premier fichier) et des corruptions de données (le contenu d’un fichier écrasant le contenu de l’autre). Moins grave, mais pénalisant sur le long terme, un bloc indiqué comme occupé mais qui ne l’est pas ne sera jamais libéré et la capacité disponible du disque s’en trouvera ainsi réduite.
Il arrive qu’un arrêt brutal de la machine ne permette pas le démontage du système de fichier proprement. Or, l’utilisation du cache et le fait que les écritures sur le disques puissent ne pas être complètement répercutées peut entraîner des incohérences de l’état stocké sur ce disque. Des utilitaires système spéciaux, les vérificateurs de systèmes de fichiers, permettent de vérifier le contenu d’une partition avant son montage pour repérer et souvent, corriger, les erreurs rencontrées. Ils effectuent de nombreuses vérifications, dont un exemple est de reconstruire en mémoire le champs de bit correspondant aux blocs libres et de comparer celui-ci aux blocs effectivement liés par des fichiers. Un bloc marqué comme libre alors qu’il ne l’est en réalité par sera marqué comme tel, et un bloc effectivement libre sera ajouté au compte de l’espace disponible sur la partition. Sous Linux, l’utilitaire fsck(8) est le vérificateur pour les systèmes de fichiers de la famille ext, comme ext4.
Systèmes de fichiers journalisées¶
Le système de fichier ext4, à l’image de la plupart des systèmes de fichiers modernes, utilise le principe de la journalisation. Les opérations d’écriture sur le disque ne sont pas réalisées directement là où un bloc est stocké. À la place, une partie du disque est utilisée pour y écrire, dans l’ordre de leur arrivée, les modifications. Chaque modification est donc vue comme une transaction, et l’ensemble des transactions forme un journal. Les transactions peuvent être écrite de façon rapide sur le disque, et comme elles sont successives maximiser leur localité (i.e. elles vont être écrites les unes à côté des autres sur le disque). La propagation des changements vers les blocs eux-même peut ensuite être réalisée de façon paresseuse, avec une priorité moindre sur les accès directs. L’utilisation d’un système de fichiers journalisé améliore la performance mais aussi la robustesse. Si le disque est démonté brutalement ou perd son alimentation, il est possible de passer en revue le journal des transactions et de les appliquer de nouveau pour restaurer un état cohérent du système.