Sur un système Unix, il est fréquent que des processus différents doivent communiquer entre eux et coordonner leurs activités. Dans ce chapitre, nous détaillons plusieurs mécanismes permettant à des processus ayant un ancêtre commun ou non de coordonner leurs activités.
Historiquement, le premier mécanisme de coordination entre processus a été l'utilisation des signaux. Nous avons déjà utilisé des signaux sans les avoir détaillés explicitement pour terminer des processus avec la commande kill(1). Nous décrivons plus en détails les principales utilisations des signaux dans ce chapitre.
Lorsque deux processus ont un ancêtre commun, il est possible de les relier en utilisant un pipe(2). Si ils n'ont pas d'ancêtre commun, il est possible d'utiliser une fifo pour obtenir un effet similaire. Une fifo peut être créée en utilisant la commande mkfifo(1) ou la fonction mkfifo(3). mkfifo(3) s'utilise comme l'appel système open(2). Pour créer une nouvelle fifo, il suffit de lui donner un nom sous la forme d'une chaîne de caractères et tout processus qui connait le nom de la fifo pourra l'utiliser.
Les sémaphores que nous avons utilisés pour coordonner plusieurs threads sont également utilisables entre processus moyennant quelques différences que nous détaillerons.
Enfin, des processus liés ou non doivent parfois accéder aux mêmes fichiers. Ces accès concurrents, si ils ne sont pas correctement coordonnés, peuvent conduire à des corruptions de fichiers. Nous présenterons les mécanismes de locking (verrouillage) qui sont utilisés dans Unix et Linux pour coordonner l'accès à des fichiers.
Signaux¶
L'envoi et la réception de signaux est le mécanisme de communication entre processus le plus primitif sous Unix. Un signal est une forme d'interruption logicielle [StevensRago2008]. Comme nous l'avons vu précédemment, un microprocesseur utilise les interruptions pour permettre au système d'exploitation de réagir aux événements extérieurs qui surviennent, et aux demandes d'action de la part du processeur ou d'un programme. Un signal Unix est un mécanisme qui permet à un processus de réagir de façon asynchrone à un événement qui s'est produit. Certains de ces événements sont directement liés au fonctionnement du matériel. D'autres sont provoqués par le processus lui-même ou un autre processus s'exécutant sur le système.
Pour être capable d'utiliser les signaux à bon escient, il est important de bien comprendre comment ceux-ci sont implémentés dans le système d'exploitation.
Il existe deux types de signaux.
Un signal synchrone est un signal qui a été directement causé par l'exécution d'une instruction du processus. Un exemple typique de signal synchrone est le signal
SIGFPEqui est généré par le système d'exploitation lorsqu'un processus provoque une exception lors du calcul d'expressions mathématiques. C'est le cas notamment lors d'une division par zéro. La sortie ci-dessous illustre ce qu'il se produit lors de l'exécution du programme/Fichiers/src/sigfpe.c.$ ./sigfpe Calcul de : 1252/0 Floating point exceptionUn signal asynchrone est un signal qui n'a pas été directement causé par l'exécution d'une instruction du processus. Il peut être produit par le système d'exploitation ou généré par un autre processus comme lorsque nous avons utilisé kill(1) dans un shell pour terminer un processus.
Le système Unix fournit plusieurs appels systèmes qui permettent de manipuler les signaux. Un processus peut recevoir des signaux synchrones ou asynchrones. Pour chaque signal, le système d'exploitation définit un traitement par défaut. Pour certains signaux, leur réception provoque l'arrêt du processus. Pour d'autres, le signal est ignoré et le processus peut continuer son exécution. Un processus peut redéfinir le traitement des signaux qu'il reçoit en utilisant l'appel système signal(2). Celui-ci permet d'associer un handler ou fonction de traitement de signal à chaque signal. Lorsqu'un handler a été associé à un signal, le système d'exploitation exécute ce handler dès que ce signal survient. Unix permet également à un processus d'envoyer un signal à un autre processus en utilisant l'appel système kill(2).
Avant d'analyser en détails le fonctionnement des appels systèmes signal(2) et kill(2), il est utile de parcourir les principaux signaux. Chaque signal est identifié par un entier positif et signal.h définit des constantes pour chaque signal reconnu par le système. Sous Linux, les principaux signaux sont :
SIGALRM. Ce signal survient lorsqu'une alarme définie par la fonction alarm(3posix) ou l'appel système setitimer(2) a expiré. Par défaut, la réception de ce signal provoque la terminaison du processus.SIGBUS. Ce signal correspond à une erreur au niveau matériel. Par défaut, la réception de ce signal provoque la terminaison du processus.SIGSEGV. Ce signal correspond à une erreur dans l'accès à la mémoire, typiquement une tentative d'accès en dehors de la zone mémoire allouée au processus. Par défaut, la réception de ce signal provoque la terminaison du processus.SIGFPE. Ce signal correspond à une erreur au niveau de l'utilisation des fonctions mathématiques, notamment en virgule flottante mais pas seulement. Par défaut, la réception de ce signal provoque la terminaison du processus.SIGTERM. Ce signal est le signal utilisé par défaut par la commande kill(1) pour demander la fin d'un processus. Par défaut, la réception de ce signal provoque la terminaison du processus.SIGKILL. Ce signal permet de forcer la fin d'un processus. Alors qu'un processus peut définir un handler pour le signalSIGTERM, il n'est pas possible d'en définir un pourSIGKILL. Ce signal est le seul qui ne peut être traité et ignoré par un processus.SIGUSR1etSIGUSR2sont deux signaux qui peuvent être utilisés par des processus sans conditions particulières. Par défaut, la réception d'un tel signal provoque la terminaison du processus.SIGCHLD. Ce signal indique qu'un processus fils s'est arrêté ou a fini son exécution. Par défaut ce signal est ignoré.SIGHUP. Aux débuts de Unix, ce signal servait à indiquer que la connexion avec le terminal avait été rompue. Aujourd'hui, il est parfois utilisé par des processus serveurs qui rechargent leur fichier de configuration lorsqu'ils reçoivent ce signal.SIGINT. Ce signal est envoyé par le shell lorsque l'utilisateur tape Ctrl-C pendant l'exécution d'un programme. Il provoque normalement la terminaison du processus.
Une description détaillée des différents signaux sous Unix et Linux peut se trouver dans signal(7), [BryantOHallaron2011], [StevensRago2008] ou encore [Kerrisk2010].
Note
Comment arrêter proprement un processus ?
Trois signaux permettent d'arrêter un processus : SIGTERM, SIGINT et SIGKILL. Lorsque l'on doit forcer l'arrêt d'un processus, il est préférable d'utiliser le signal SIGTERM car le processus peut prévoir une routine de traitement de ce signal. Cette routine peut par exemple fermer proprement toutes les ressources (fichiers, ...) utilisées par le processus. Lorsque l'on tape Ctrl-C dans le shell, c'est le signal SIGINT qui est envoyé au processus qui est en train de s'exécuter. Le signal SIGKILL ne peut pas être traité par le processus. Lorsque l'on envoie ce signal à un processus, on est donc certain que celui-ci s'arrêtera. Malheureusement, cet arrêt sera brutal et le processus n'aura pas eu le temps de libérer proprement toutes les ressources qu'il utilisait. Quand un processus ne répond plus, il est donc préférable de d'abord essayer SIGINT ou SIGTERM et de n'utiliser SIGKILL qu'en dernier recours.
Envoi de signaux¶
Un processus peut envoyer un signal à un autre processus en utilisant l'appel système kill(2).
#include <sys/types.h>
#include <signal.h>
int kill(pid_t pid, int sig);
Cet appel système prend deux arguments. Le second est toujours le numéro du signal à délivrer ou la constante définissant ce signal dans signal.h. Le premier argument indique à quel(s) processus le signal doit être délivré :
pid>0. Dans ce cas, le signal est délivré au processus ayant comme identifiantpid.pid==0. Dans ce cas, le signal est délivré à tous les processus qui font partie du même groupe de processus [1] que le processus qui exécute l'appel système kill(2).pid==-1. Dans ce cas, le signal est délivré à tous les processus pour lesquels le processus qui exécute kill(2) a les permissions suffisantes pour leur envoyer un signal.pid<-1. Dans ce cas, le signal est délivré à tous les processus qui font partie du groupeabs(pid).
Par défaut, un processus ne peut envoyer un signal qu'à un processus qui s'exécute avec les mêmes permissions que le processus qui exécute l'appel système kill(2).
Traitement de signaux¶
Pour des raisons historiques, il existe deux appels systèmes permettant à un processus de spécifier comment un signal particulier doit être traité. Le premier est l'appel système signal(2). Il prend deux arguments : le numéro du signal dont le traitement doit être modifié et la fonction à exécuter lorsque ce signal est reçu. Le second est sigaction(2). Cet appel système est nettement plus générique et plus complet que signal(2) mais il ne sera pas traité en détails dans ces notes. Des informations complémentaires sur l'utilisation de sigaction(2) peuvent être obtenues dans [Kerrisk2010] ou [StevensRago2008].
#include <signal.h>
typedef void (*sighandler_t)(int);
sighandler_t signal(int signum, sighandler_t handler);
Le premier argument de l'appel système signal(2) est généralement spécifié en utilisant les constantes définies dans signal.h. Le second argument est un pointeur vers une fonction de type void qui prend comme argument un entier. Cette fonction est la fonction qui sera exécutée par le système d'exploitation à la réception du signal. Ce second argument peut également être la constante SIG_DFL si le signal doit être traité avec le traitement par défaut documenté dans signal(7) et SIG_IGN si le signal doit être ignoré. La valeur de retour de l'appel système signal(2) est la façon dont le système d'exploitation gérait le signal passé en argument avant l'exécution de l'appel système (typiquement SIG_DFL ou SIG_IGN) ou SIG_ERR en cas d'erreur.
L'exemple ci-dessous est un programme simple qui compte le nombre de signaux SIGUSR1 et SIGUSR2 qu'il reçoit et se termine dès qu'il a reçu cinq signaux.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <signal.h>
#include <unistd.h>
#include <stdint.h>
#include <stdio.h>
volatile sig_atomic_t n_sigusr1=0;
volatile sig_atomic_t n_sigusr2=0;
static void sig_handler(int);
int main (int argc, char *argv[]) {
if(signal(SIGUSR1,sig_handler)==SIG_ERR) {
perror("signal");
exit(EXIT_FAILURE);
}
if(signal(SIGUSR2,sig_handler)==SIG_ERR) {
perror("signal");
exit(EXIT_FAILURE);
}
while( (n_sigusr1+n_sigusr2) <5) {
// vide
}
printf("Fin du processus\n");
printf("Reçu %d SIGUSR1 et %d SIGUSR2\n",n_sigusr1,n_sigusr2);
return(EXIT_SUCCESS);
}
static void sig_handler(int signum) {
if(signum==SIGUSR1) {
n_sigusr1++;
}
else {
if(signum==SIGUSR2) {
n_sigusr2++;
}
else {
char *msg="Reçu signal inattendu\n";
write(STDERR_FILENO,msg,strlen(msg));
_exit(EXIT_FAILURE);
}
}
}
Lors de son exécution, ce programme affiche :
$ ./sigusr &
[1] 45602
$ kill -s SIGUSR1 45602
$ kill -s SIGUSR2 45602
$ kill -s SIGUSR2 45602
$ kill -s SIGUSR1 45602
$ kill -s SIGUSR1 45602
$ Fin du processus
Reçu 3 SIGUSR1 et 2 SIGUSR2
[1]+ Done ./sigusr
Il est intéressant d'analyser le code source du programme ci-dessus. Commençons d'abord par une lecture rapide pour comprendre la logique du programme sans s'attarder sur les détails. La fonction main utilise l'appel système signal(2) pour enregistrer un handler pour les signaux SIGUSR1 et SIGUSR2. La fonction sig_handler sera exécutée dès réception d'un de ces signaux. Cette fonction prend comme argument le numéro du signal reçu. Cela permet de traiter plusieurs signaux dans la même fonction. Ensuite, la boucle while est une boucle active qui ne se terminera que lorsque la somme des variables n_sigusr1 et n_sigusr2 sera égale à 5. Ces deux variables sont modifiées uniquement dans la fonction sig_handler. Elles permettent de compter le nombre de signaux de chaque type qui ont été reçus.
Une lecture plus attentive du code ci-dessus révèle plusieurs points importants auxquels il faut être attentif lorsque l'on utilise les signaux.
Tout d'abord, lorsqu'un processus comprend une (ou plusieurs) fonction(s) de traitement de signaux, il y a plusieurs séquences d'instructions qui peuvent être exécutées par le processus. La première est la suite d'instructions du processus lui-même qui démarre à la fonction main. Dès qu'un signal est reçu, cette séquence d'instructions est interrompue pour exécuter la séquence d'instructions de la fonction de traitement du signal. Ce n'est que lorsque cette fonction se termine que la séquence principale peut reprendre son exécution à l'endroit où elle a été interrompue.
L'existence de deux ou plusieurs séquences d'instructions peut avoir des conséquences importantes sur le bon fonctionnement du programme et peut poser de nombreuses difficultés d'implémentation. En effet, une fonction de traitement de signal doit pouvoir être exécutée à n'importe quel moment. Elle peut donc démarrer à n'importe quel endroit de la séquence d'instructions du processus. Si le processus et une fonction de traitement de signal accèdent à la même variable, il y a un risque que celle-ci soit modifiée par la fonction de traitement du signal pendant qu'elle est utilisée dans le processus. Si l'on n'y prend garde, ces accès venant de différentes séquences d'instructions peuvent poser des problèmes similaires à ceux posés par l'utilisation de threads. Une routine de traitement de signal est cependant moins générale qu'un thread et les techniques utilisables dans les threads ne sont pas applicables aux fonctions de traitement des signaux. En effet, quand la fonction de traitement de signal démarre, il est impossible de bloquer son exécution sur un mutex pour revenir au processus principal. Celle-ci doit s'exécuter jusqu'à sa dernière instruction.
Lorsque l'on écrit une routine de traitement de signal, plusieurs précautions importantes doivent être prises. Tout d'abord, une fonction de traitement de signal doit manipuler les variables avec précautions. Comme elle est potentiellement exécutée depuis n'importe quel endroit du code, elle ne peut pas s'appuyer sur le stack. Elle ne peut utiliser que des variables globales pour influencer le processus principal. Comme ces variables peuvent être utilisées à la fois dans le processus et la routine de traitement de signal, il est important de les déclarer en utilisant le mot-clé volatile. Cela force le compilateur à recharger la valeur de la variable de la mémoire à chaque fois que celle-ci est utilisée. Mais cela ne suffit pas car il est possible que le processus exécute l'instruction de chargement de la valeur de la variable, puis qu'un signal lui soit délivré, ce qui provoquera l'exécution de la fonction de traitement du signal. Lorsque celle-ci se terminera le processus poursuivra son exécution sans recharger la valeur de la variable potentiellement modifiée par la fonction de traitement du signal. Face à ce problème, il est préférable d'utiliser uniquement des variables de types sig_atomic_t dans les fonctions de traitement de signaux. Ce type permet de stocker un entier. Lorsque ce type est utilisé, le compilateur garantit que tous les accès à la variable se feront de façon atomique sans accès concurrent possible entre le processus et la fonction de traitement des signaux.
L'utilisation de sig_atomic_t n'est pas la seule précaution à prendre lorsque l'on écrit une fonction de traitement des signaux. Il faut également faire attention aux fonctions de la librairie et aux appels systèmes que l'on utilise. Sachant qu'un signal peut être reçu à n'importe quel moment, il est possible qu'un processus reçoive un signal et exécute une fonction de traitement du signal pendant l'exécution de la fonction fct de la librairie standard. Si la fonction de traitement du signal utilise également la fonction fct, il y a un risque d'interférence entre l'exécution de ces deux fonctions. Ce sera le cas notamment si la fonction utilise un buffer statique ou modifie la variable errno. Dans ces cas, la fonction de traitement du signal risque de modifier une valeur ou une zone mémoire qui a déjà été modifiée par le processus principal et cela donnera un résultat incohérent. Pour éviter ces problèmes, il ne faut utiliser que des fonctions réentrantes à l'intérieur des fonctions de traitement des signaux. Des fonctions comme printf(3), scanf(3) ne sont pas réentrantes et ne doivent pas être utilisées dans une section de traitement des signaux. La (courte) liste des fonctions qui peuvent être utilisées sans risque est disponible dans la section 2.4 de l'Open Group Base Specification
Ces restrictions sur les instructions qui peuvent être utilisées dans une fonction de traitement des signaux ne sont pas les seules qui affectent l'utilisation des signaux. Ceux-ci souffrent d'autres limitations.
Pour bien les comprendre, il est utile d'analyser comment ceux-ci sont supportés par le noyau. Il y a deux stratégies possibles pour implémenter les signaux sous Unix. La première stratégie est de considérer qu'un signal est un message qui est envoyé depuis le noyau ou un processus à un autre processus. Pour traiter ces messages, le noyau contient une queue qui stocke tous les signaux destinés à un processus donné. Avec cette stratégie d'implémentation, l'appel système kill(2) génère un message et le place dans la queue associée au processus destination. Le noyau stocke pour chaque processus un tableau de pointeurs vers les fonctions de traitement de chacun des signaux. Ce tableau est modifié par l'appel système signal(2). Chaque fois que le noyau réactive un processus, il vérifie si la queue associée à ce processus contient un ou plusieurs messages concernant des signaux. Si un message est présent, le noyau appelle la fonction de traitement du signal correspondant. Lorsque la fonction se termine, l'exécution du processus reprend à l'instruction qui avait été interrompue.
La seconde stratégie est de représenter l'ensemble des signaux qu'un processus peut recevoir sous la forme de drapeaux binaires. En pratique, il y a un drapeau par signal. Avec cette stratégie d'implémentation, l'appel système kill(2) modifie le drapeau correspondant du processus destination du signal (sauf si ce signal est ignoré par le processus, dans ce cas le drapeau n'est pas modifié). L'appel système signal(2) modifie également le tableau contenant les fonctions de traitement des signaux associé au processus. Chaque fois que le noyau réactive un processus, que ce soit après un changement de contexte ou après l'exécution d'un appel système, il vérifie les drapeaux relatifs aux signaux du processus. Si un des drapeaux est vrai, le noyau appelle la fonction de traitement associée à ce signal.
La plupart des variantes de Unix, y compris Linux, utilisent la seconde stratégie d'implémentation pour les signaux. L'avantage principal de l'utilisation de drapeaux pour représenter les signaux reçus par un processus est qu'il suffit d'un bit par signal qui peut être reçu par le processus. La première stratégie nécessite de maintenir une queue par processus et la taille de cette queue varie en fonction du nombre de signaux reçus. Par contre, l'utilisation de drapeaux a un inconvénient majeur : il n'y a pas de garantie sur la délivrance des signaux. Lorsqu'un processus reçoit un signal, cela signifie qu'il y a au moins un signal de ce type qui a été envoyé au processus, mais il est très possible que plus d'un signal ont été envoyés au processus.
Pour illustrer ce problème, considérons le programme ci-dessous qui compte simplement le nombre de signaux SIGUSR1 reçus.
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <unistd.h>
volatile sig_atomic_t n_sigusr1=0;
static void sig_handler(int);
int main (int argc, char *argv[]) {
if(signal(SIGUSR1,sig_handler)==SIG_ERR) {
perror("signal");
exit(EXIT_FAILURE);
}
int duree=60;
while(duree>0) {
printf("Exécution de sleep(%d)\n",duree);
duree=sleep(duree);
}
printf("Fin du processus\n");
printf("Reçu %d SIGUSR1\n",n_sigusr1);
return(EXIT_SUCCESS);
}
static void sig_handler(int signum) {
if(signum==SIGUSR1) {
n_sigusr1++;
}
}
Depuis un shell, il est possible d'envoyer plusieurs fois le signal SIGUSR1 rapidement avec le script /Fichiers/src/nkill.sh. Ce script prend deux arguments : le nombre de signaux à envoyer et le processus destination.
#!/bin/bash
if [ $# -ne 2 ]
then
echo "Usage: `basename $0` n pid"
exit 1
fi
n=$1
pid=$2
for (( c=1; c<=$n; c++ ))
do
kill -s SIGUSR1 $pid
done
La sortie ci-dessous présente une exécution de ce script avec le processus /Fichiers/src/sigusrcount.c en tâche de fond.
$ ./sigusrcount &
[1] 47845
$ Exécution de sleep(60)
$./nkill.sh 10 47845
Exécution de sleep(52)
$ ./nkill.sh 10 47845
Exécution de sleep(46)
$ ./nkill.sh 10 47845
Exécution de sleep(31)
$ Fin du processus
Reçu 3 SIGUSR1
Il y a plusieurs points intéressants à noter concernant l'exécution de ce programme. Tout d'abord, même si 30 signaux SIGUSR1 ont été générés, seuls 3 de ces signaux ont effectivement étés reçus. Les signaux ne sont manifestement pas fiables sous Unix et cela peut s'expliquer de deux façons. Premièrement, les signaux sont implémentés sous la forme de bitmaps. La réception d'un signal modifie simplement la valeur d'un bit dans le bitmap du processus. En outre, durant l'exécution de la fonction qui traite le signal SIGUSR1, ce signal est bloqué par le système d'exploitation pour éviter qu'un nouveau signal n'arrive pendant que le premier est traité.
Un deuxième point important à relever est l'utilisation de sleep(3). Par défaut, cette fonction de la librairie permet d'attendre un nombre de secondes passé en argument. Si sleep(3) a mis le processus en attente pendant au moins le temps demandé, elle retourne 0 comme valeur de retour. Mais sleep(3) est un des exemples de fonctions ou appels systèmes qui sont dits lents. Un appel système lent est un appel système dont l'exécution peut être interrompue par la réception d'un signal. C'est notamment le cas pour l'appel système read(2) [2]. Lorsqu'un signal survient pendant l'exécution d'un tel appel système, celui-ci est interrompu pour permettre l'exécution de la fonction de traitement du signal. Après l'exécution de cette fonction, l'appel système se termine [3] en retournant une erreur et met errno à EINTR de façon à indiquer que l'appel système a été interrompu. Le processus doit bien entendu traiter ces interruptions d'appels systèmes si il utilise des signaux.
Nous terminons cette section en analysant deux cas pratiques d'utilisation des signaux. Le premier est relatif aux signaux synchrones et nous développons une fonction de traitement du signal SIGFPE pour éviter qu'un programme ne s'arrête suite à une division par zéro. Ensuite, nous utilisons alarm(3posix) pour implémenter un temporisateur simple.
Traitement de signaux synchrones¶
Le programme ci-dessous prend en arguments en ligne de commande une séquence d'entiers et divise la valeur 1252 par chaque entier passé en argument. Il enregistre la fonction sigfpe_handler comme fonction de traitement du signal SIGFPE.
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <string.h>
#include <unistd.h>
static void sigfpe_handler(int);
int main (int argc, char *argv[]) {
int n=1252;
void (*handler)(int);
handler=signal(SIGFPE,sigfpe_handler);
if(handler==SIG_ERR) {
perror("signal");
exit(EXIT_FAILURE);
}
for(int i=1;i<argc;i++) {
char *endptr;
printf("Traitement de argv[%d]=%s\n",i,argv[i]);
fflush(stdout);
long val=strtol(argv[i],&endptr,10);
if(*endptr=='\0') {
int resultat=n/(int) val;
printf("%d/%d=%d\n",n,(int) val,resultat);
}
else {
printf("Argument incorrect : %s\n",argv[i]);
}
}
return(EXIT_SUCCESS);
}
static void sigfpe_handler(int signum) {
char *msg="Signal SIGFPE reçu\n";
write(STDOUT_FILENO,msg,strlen(msg));
}
Lors de son exécution, ce programme affiche la sortie ci-dessous :
$ ./sigfpe2 1 2 aa 0 9
Traitement de argv[1]=1
1252/1=1252
Traitement de argv[2]=2
1252/2=626
Traitement de argv[3]=aa
Argument incorrect : aa
Traitement de argv[4]=0
Signal SIGFPE reçu
Signal SIGFPE reçu
...
La fonction sigfpe_handler traite bien le signal SIGPFE reçu, mais après son exécution, elle tente de recommencer l'exécution de la ligne int resultat=n/(int) val;, ce qui provoque à nouveau un signal SIGPFE. Pour éviter ce problème, il faut permettre à la fonction de traitement du signal de modifier la séquence d'exécution de la fonction main après la réception du signal. Une solution pourrait être d'utiliser l'instruction goto comme suit :
if(*endptr=='\0') {
int resultat=n/(int) val;
printf("%d/%d=%d\n",n,(int) val,resultat);
goto fin:
erreur:
printf("%d/%d=NaN\n",n,(int) val);
fin:
}
else {
printf("Argument incorrect : %s\n",argv[i]);
}
// ...
static void sigfpe_handler(int signum) {
goto erreur:
}
En C, ce genre de construction n'est pas possible car l'étiquette d'un goto doit nécessairement se trouver dans la même fonction que l'invocation de goto. La seule possibilité pour faire ce genre de saut entre fonctions en C, est d'utiliser les fonctions setjmp(3) et longjmp(3). Dans un programme normal, ces fonctions sont à éviter encore plus que les goto car elles rendent le code très difficile à lire.
#include <setjmp.h>
int setjmp(jmp_buf env);
void longjmp(jmp_buf env, int val);
La fonction setjmp(3) est équivalente à la déclaration d'une étiquette. Elle prend comme argument un jmp_buf. Cette structure de données, définie dans setjmp.h permet de sauvegarder l'environnement d'exécution, c'est-à-dire les valeurs des registres y compris %eip et %esp au moment où elle est exécutée. Lorsque setjmp(3) est exécutée dans le flot normal des instructions du programme, elle retourne la valeur 0. La fonction longjmp(3) prend deux arguments. Le premier est une structure de type jmp_buf et le second un entier. Le jmp_buf est l'environnement d'exécution qu'il faut restaurer lors de l'exécution de longjmp(3) et le second argument la valeur de retour que doit avoir la fonction setjmp(3) correspondante après l'exécution de longjmp(3).
Le programme ci-dessous illustre l'utilisation de setjmp(3) et longjmp(3).
#include <stdio.h>
#include <stdlib.h>
#include <setjmp.h>
jmp_buf label;
void f() {
printf("Début fonction f\n");
if(setjmp(label)==0) {
printf("Exécution normale\n");
}
else {
printf("Exécution après longjmp\n");
}
}
void g() {
printf("Début fonction g\n");
longjmp(label,1);
printf("Ne sera jamais affiché\n");
}
int main (int argc, char *argv[]) {
f();
g();
return(EXIT_SUCCESS);
}
Le programme débute en exécutant la fonction f. Dans cette exécution, la fonction setjmp(3) retourne la valeur 0. Ensuite, la fonction main appelle la fonction g qui elle exécute longjmp(label,1). Cela provoque un retour à la fonction f à l'endroit de l'exécution de setjmp(label) qui cette fois-ci va retourner la valeur 1. Lors de son exécution, le programme ci-dessus affiche :
Début fonction f
Exécution normale
Début fonction g
Exécution après longjmp
Avec les fonctions setjmp(3) et longjmp(3), il est presque possible d'implémenter le traitement attendu pour le signal SIGFPE. Il reste un problème à résoudre. Lorsque la routine de traitement du signal SIGFPE s'exécute, ce signal est bloqué par le système d'exploitation jusqu'à ce que cette fonction se termine. Si elle effectue un longjmp(3), elle ne se terminera jamais et le signal continuera à être bloqué. Pour éviter ce problème, il faut utiliser les fonctions sigsetjmp(3) et siglongjmp(3). Ces fonctions sauvegardent dans une structure de données sigjmp_buf non seulement l'environnement d'exécution mais aussi la liste des signaux qui sont actuellement bloqués. La fonction sigsetjmp(3) prend un argument supplémentaire : un entier qui doit être non nul si l'on veut effectivement sauvegarder la liste des signaux bloqués. Lorsque siglongjmp(3) s'exécute, l'environnement et la liste des signaux bloqués sont restaurés.
Le programme ci-dessous présente l'utilisation de sigsetjmp(3) et siglongjmp(3).
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <setjmp.h>
sigjmp_buf buf;
static void sigfpe_handler(int);
int main (int argc, char *argv[]) {
int n=1252;
if(signal(SIGFPE,sigfpe_handler)==SIG_ERR) {
perror("signal");
exit(EXIT_FAILURE);
}
for(int i=1;i<argc;i++) {
char *endptr;
int r;
printf("Traitement de argv[%d]=%s\n",i,argv[i]);
long val=strtol(argv[i],&endptr,10);
if(*endptr=='\0') {
r=sigsetjmp(buf,1);
if(r==0) {
int resultat=n/(int) val;
printf("%d/%d=%d\n",n,(int) val,resultat);
}
else {
printf("%d/%d=NaN\n",n,(int) val);
}
}
else {
printf("Argument incorrect : %s\n",argv[i]);
}
}
return(EXIT_SUCCESS);
}
static void sigfpe_handler(int signum) {
// ignorer la donnée et passer à la suivante
siglongjmp(buf,1);
}
Lors de son exécution, il affiche la sortie standard suivante.
./sigfpe3 1 2 3 0 a 0 3
Traitement de argv[1]=1
1252/1=1252
Traitement de argv[2]=2
1252/2=626
Traitement de argv[3]=3
1252/3=417
Traitement de argv[4]=0
1252/0=NaN
Traitement de argv[5]=a
Argument incorrect : a
Traitement de argv[6]=0
1252/0=NaN
Traitement de argv[7]=3
1252/3=417
Temporisateurs¶
Parfois il est nécessaire dans un programme de limiter le temps d'attente pour réaliser une opération. Un exemple simple est lorsqu'un programme attend l'entrée d'un paramètre via l'entrée standard mais peut remplacer ce paramètre par une valeur par défaut si celui-ci n'est pas entré endéans quelques secondes. Lorsqu'un programme attend une information via l'entrée standard, il exécute l'appel système read(2) directement ou via des fonctions de la librairie comme fgets(3) ou getchar(3). Par défaut, celui-ci est bloquant, cela signifie qu'il ne se terminera que lorsqu'une donnée aura été lue. Si read(2) est utilisé seul, il n'est pas possible de borner le temps d'attente du programme et d'interrompre l'appel à read(2) après quelques secondes. Pour obtenir ce résultat, une possibilité est d'utiliser un signal. En effet, read(2) est un appel système lent qui peut être interrompu par la réception d'un signal. Il y a plusieurs façons de demander qu'un signal soit généré après un certain temps. Le plus général est setitimer(2). Cet appel système permet de générer un signal SIGALRM après un certain temps ou périodiquement. L'appel système alarm(3posix) est plus ancien mais plus simple à utiliser que setitimer(2). Nous l'utilisons afin d'illustrer comment un signal peut permettre de limiter la durée d'attente d'un appel système.
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <unistd.h>
#include <stdbool.h>
static void sig_handler(int);
int main (int argc, char *argv[]) {
char c;
printf("Tapez return en moins de 5 secondes !\n");
fflush(stdout);
if(signal(SIGALRM,sig_handler)==SIG_ERR) {
perror("signal");
exit(EXIT_FAILURE);
}
// sigalrm interrompt les appels système
if(siginterrupt(SIGALRM,true)<0) {
perror("siginterrupt");
exit(EXIT_FAILURE);
}
alarm(5);
int r=read(STDIN_FILENO,&c,1);
if((r==1)&&(c=='\n')) {
alarm(0); // reset timer
printf("Gagné\n");
exit(EXIT_SUCCESS);
}
printf("Perdu !\n");
exit(EXIT_FAILURE);
}
static void sig_handler(int signum) {
// rien à faire, read sera interrompu
}
Ce programme utilise alarm(3posix) pour limiter la durée d'un appel système read(2). Pour ce faire, il enregistre d'abord une fonction pour traiter le signal SIGALRM. Cette fonction est vide dans l'exemple, son exécution permet juste d'interrompre l'appel système read(2). Par défaut, lorsqu'un signal survient durant l'exécution d'un appel système, celui-ci est automatiquement redémarré par le système d'exploitation pour éviter à l'application de devoir traiter tous les cas possibles d'interruption d'appels système. La fonction siginterrupt(3) permet de modifier ce comportement par défaut et nous l'utilisons pour forcer l'interruption d'appels systèmes lorsque le signal SIGALRM est reçu. L'appel à alarm(0) permet de désactiver l'alarme qui était en cours.
Lors de son exécution, ce programme affiche la sortie suivante.
Tapez return en moins de 5 secondes !
Perdu !
En essayant le programme ci-dessus, on pourrait conclure qu'il fonctionne parfaitement. Il a cependant un petit défaut qui peut s'avérer genant si par exemple on utilise la même logique pour écrire une fonction read_time qui se comporte comme read(2) sauf que son dernier argument est un délai maximal. Sur un système fort chargé, il est possible qu'après l'exécution de alarm(5) le processus soit mis en attente par le système d'exploitation qui exécute d'autres processus. Lorsque l'alarme expire, la fonction de traitement de SIGALRM est exécutée puis seulement l'appel à read(2) s'effectue. Celui-ci étant bloquant, le processus restera bloqué jusqu'à ce que les données arrivent ce qui n'est pas le comportement attendu.
Pour éviter ce problème, il faut empêcher l'exécution de read(2) si le signal SIGALRM a déjà été reçu. Cela peut se réaliser en utilisant sigsetjmp(3) pour définir une étiquette avant l'exécution du bloc contenant l'appel à alarm(3posix) et l'appel à read(2). Si le signal n'est pas reçu, l'appel à read(2) s'effectue normalement. Si par contre le signal SIGALRM est reçu entre l'appel à alarm(3posix) et l'appel à read(2), alors l'exécution de siglongjmp(3) dans sig_handler empêchera l'exécution de l'appel système read(2) ce qui est bien le comportement attendu.
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <unistd.h>
#include <stdbool.h>
#include <setjmp.h>
sigjmp_buf env;
static void sig_handler(int);
int main (int argc, char *argv[]) {
char c;
printf("Tapez return en moins de 5 secondes !\n");
fflush(stdout);
if(signal(SIGALRM,sig_handler)==SIG_ERR) {
perror("signal");
exit(EXIT_FAILURE);
}
// sigalrm interrompt les appels système
if(siginterrupt(SIGALRM,true)<0) {
perror("siginterrupt");
exit(EXIT_FAILURE);
}
int r=0;
if(sigsetjmp(env,1)==0) {
// sig_handler n'a pas encore été appelé
alarm(5);
r=read(STDIN_FILENO,&c,1);
}
else {
// sig_handler a déjà été exécuté
// le délai a déjà expiré, inutile de faire read
}
alarm(0); // arrêt du timer
if((r==1)&&(c=='\n')) {
printf("Gagné\n");
exit(EXIT_SUCCESS);
}
else {
printf("Perdu !\n");
exit(EXIT_FAILURE);
}
}
static void sig_handler(int signum) {
siglongjmp(env,1);
}
L'appel système alarm(3posix) s'appuie sur setitimer(2), mais les deux types d'alarmes ne doivent pas être combinés. Il en va de même pour sleep(3) qui peut être implémenté en utilisant SIGALRM. Linux contient d'autres appels systèmes et fonctions pour gérer différents types de temporisateurs. Ceux-ci sont décrits de façon détaillée dans [Kerrisk2010].
Note
Signaux, threads, fork(2) et execve(2)
Le noyau du système d'exploitation maintient pour chaque processus une structure de données contenant la liste des signaux qui sont ignorés, ont été reçus et les pointeurs vers les fonctions de traitement pour chaque signal. Cette structure de données est associée à chaque processus. La création de threads ne modifie pas cette structure de données et lorsqu'un signal est délivré à un processus utilisant des threads, c'est généralement le thread principal qui recevra et devra traiter le signal. Lors de l'exécution de fork(2), la structure de données relative aux signaux du processus père est copiée dans le processus fils. Après fork(2), les deux processus peuvent évoluer séparément et le fils peut par exemple modifier la façon dont il traite un signal sans que cela n'affecte le processus père. Lors de l'exécution de execve(2), la structure de données relative aux signaux est réinitialisée avec les traitements par défaut pour chacun des signaux.
Sémaphores nommés¶
Nous avons présenté les sémaphores lors de l'étude du fonctionnement des threads et les mécanismes qui permettent de les coordonner. Chaque sémaphore utilise une structure de données qui est dans une mémoire accessible aux différents threads/processus qui doivent se coordonner. Lorsque des sémaphores sont utilisés pour coordonner des threads, cette structure de données est soit stockée dans la zone réservée aux variables globales, soit sur le heap (tas). Lorsque des processus doivent se coordonner, il ne partagent pas nécessairement [4] de la mémoire. Dans ce cas, la fonction sem_init(3) ne peut pas être utilisée pour créer de sémaphore. Par contre, il est possible d'utiliser des sémaphores "nommés" (named semaphores). Ces sémaphores utilisent une zone de mémoire qui est gérée par le noyau et qui peut être utilisée par plusieurs processus. Un sémaphore nommé est identifié par un nom. Sous Linux, ce nom correspond à un fichier sur un système de fichiers et tout processus qui connait le nom d'un sémaphore et possède les permissions l'autorisant à y accéder peut l'utiliser. Trois appels systèmes sont utilisés pour créer, utiliser et supprimer un sémaphore nommé. Une présentation générale des sémaphores est disponible dans la page de manuel sem_overview(7).
#include <fcntl.h> /* For O_* constants */
#include <sys/stat.h> /* For mode constants */
#include <semaphore.h>
sem_t *sem_open(const char *name, int oflag);
sem_t *sem_open(const char *name, int oflag,
mode_t mode, unsigned int value);
int sem_close(sem_t *sem);
int sem_unlink(const char *name);
sem_open(3) permet d'ouvrir ou de créer un sémaphore nommé. Tout comme l'appel système open(2), il existe deux variantes de sem_open(3). La première prend 2 arguments et permet d'utiliser un sémaphore nommé déjà existant. La seconde prend quatre arguments et permet de créer un nouveau sémaphore nommé et l'initialise à la valeur du quatrième argument. La fonction sem_open(3) s'utilise de la même façon que l'appel système open(2) sauf qu'elle retourne un pointeur vers une structure de type sem_t et qu'en cas d'erreur elle retourne SEM_FAILED et utilise errno pour fournir une information sur le type d'erreur. La fonction sem_close(3) permet à un processus d'arrêter d'utiliser un sémaphore nommé. Enfin, la fonction sem_unlink(3) permet de supprimer un sémaphore qui avait été créé avec sem_open(3). Tout comme il est possible d'utiliser l'appel système unlink(2) sur un fichier ouvert par un processus, il est possible d'appeler sem_unlink(3) avec comme argument un nom de sémaphore utilisé actuellement par un processus. Dans ce cas, le sémaphore sera complètement libéré lorsque le dernier processus qui l'utilise aura effectué sem_close(3). Les fonctions sem_post(3) et sem_wait(3) s'utilisent de la même façon qu'avec les sémaphores non-nommés que nous avons utilisé précédemment.
A titre d'exemple, considérons un exemple simple d'utilisation de sémaphores nommés dans lequel un processus doit attendre la fin de l'exécution d'une fonction dans un autre processus pour pouvoir s'exécuter. Avec les threads, nous avions résolu ce problème en initialisant un sémaphore à 0 dans le premier thread alors que le second démarrait par un sem_wait(3). Le première exécute sem_post(3) dès qu'il a fini l'exécution de sa fonction critique.
Le programme ci-dessous illustre le processus qui s'exécute en premier.
sem_t *semaphore;
void before() {
// do something
for(int j=0;j<1000000;j++) {
}
printf("before done, pid=%d\n",(int) getpid());
sem_post(semaphore);
}
int main (int argc, char *argv[]) {
int err;
semaphore=sem_open("lsinf1252",O_CREAT,S_IRUSR | S_IWUSR,0);
if(semaphore==SEM_FAILED) {
error(-1,"sem_open");
}
sleep(20);
before();
err=sem_close(semaphore);
if(err!=0) {
error(err,"sem_close");
}
return(EXIT_SUCCESS);
}
Ce processus commence par utiliser sem_open(3) pour créer un sémaphore qui porte le nom lsinf1252 et est initialisé à zéro puis se met en veille pendant vingt secondes. Ensuite il exécute la fonction before qui se termine par l'exécution de sem_post(semaphore). Cet appel a pour résultat de libérer le second processus dont le code est présenté ci-dessous :
sem_t *semaphore;
void after() {
sem_wait(semaphore);
// do something
for(int j=0;j<1000000;j++) {
}
printf("after done, pid=%d\n",(int) getpid());
}
int main (int argc, char *argv[]) {
int err;
// semaphore a été créé par before
semaphore=sem_open("lsinf1252",0);
if(semaphore==SEM_FAILED) {
error(-1,"sem_open");
}
after();
err=sem_close(semaphore);
if(err!=0) {
error(err,"sem_close");
}
err=sem_unlink("lsinf1252");
if(err!=0) {
error(err,"sem_unlink");
}
return(EXIT_SUCCESS);
}
Ce processus utilise le sémaphore qui a été créé par un autre processus pour se coordonner. La fonction after démarre par l'exécution de sem_wait(3) qui permet d'attendre que l'autre processus ait terminé l'exécution de la fonction before. Les sémaphores nommés peuvent être créés et supprimés comme des fichiers. Il est donc normal que le sémaphore soit créé par le premier processus et supprimé par le second. Sous Linux, les sémaphores nommés sont créés comme des fichiers dans le système de fichiers virtuel /dev/shm :
$ ls -l /dev/shm/
-rw------- 1 obo stafinfo 32 Apr 10 15:37 sem.lsinf1252
Les permissions du fichier virtuel représentent les permissions associées au sémaphore. La sortie ci-dessous présente une exécution des deux processus présentés plus haut.
$ ./process-sem-before &
[1] 5222
$ ./process-sem-after
before done, pid=5222
after done, pid=5223
[1]+ Done ./process-sem-before
Il est important de noter que les sémaphores nommés sont une ressource généralement limitée. Lorsqu'il a été créé, un sémaphore nommé utilise des ressources du système jusqu'à ce qu'il soit explicitement supprimé avec sem_unlink(3). Il est très important de toujours bien effacer les sémaphores nommés dès qu'ils ne sont plus nécessaires. Sans cela, l'espace réservé pour ces sémaphores risque d'être rempli et d'empêcher la création de nouveaux sémaphores par d'autres processus.
Partage de fichiers¶
Les fichiers sont l'un des principaux moyens de communication entre processus. L'avantage majeur des fichiers est leur persistence. Les données sauvegardées dans un fichier persistent sur le système de fichiers après la fin du processus qui les a écrites. L'inconvénient majeur de l'utilisation de fichiers par rapport à d'autres techniques de communication entre processus est la relative lenteur des dispositifs de stockage en comparaison avec les accès à la mémoire. Face à cette lenteur des dispositifs de stockage, la majorité des systèmes d'exploitation utilisent des buffers qui servent de tampons entre les processus et les dispositifs de stockage. Lorsqu'un processus écrit une donnée sur un dispositif de stockage, celle-ci est d'abord écrite dans un buffer géré par le système d'exploitation et le processus peut poursuivre son exécution sans devoir attendre l'exécution complète de l'écriture sur le dispositif de stockage. La taille de ces buffers varie généralement dynamiquement en fonction de la charge du système. Les données peuvent y rester entre quelques fractions de seconde et quelques dizaines de secondes. Un processus peut contrôler l'utilisation de ce buffer en utilisant l'appel système fsync(2). Celui-ci permet de forcer l'écriture sur le dispositif de stockage des données du fichier identifié par le descripteur de fichiers passé en argument. L'appel système sync(2) force quant à lui l'écriture de toutes les données actuellement stockées dans les buffers du noyau sur les dispositifs de stockage. Cet appel système est notamment utilisé par un processus système qui l'exécute toutes les trente secondes afin d'éviter que des données ne restent trop longtemps dans les buffers du noyau.
L'utilisation d'un même fichier par plusieurs processus est une des plus anciennes techniques de communication entre processus. Pour comprendre son fonctionnement, il est utile d'analyser les structures de données qui sont maintenues par le noyau du système d'exploitation pour chaque fichier et chaque processus. Comme nous l'avons présenté dans le chapitre précédent, le système de fichiers utilise des inodes pour stocker les méta-données et la liste des blocs de chaque fichier. Lorsqu'un processus ouvre un fichier, le noyau du système d'exploitation lui associe le premier descripteur de fichier libre dans la table des descripteurs de fichiers du processus. Ce descripteur de fichier pointe alors vers une structure maintenue par le noyau qui est souvent appelée un open file object. Un open file object contient toutes les informations qui sont nécessaires au noyau pour pouvoir effectuer les opérations de manipulation d'un fichier ouvert par un processus. Parmi celles-ci, on trouve notamment :
- le mode dans lequel le fichier a été ouvert (lecture seule, écriture, lecture/écriture). Ce mode est initialisé à l'ouverture du fichier. Le noyau vérifie le mode lors de l'exécution des appels systèmes read(2) et write(2) mais pas les permissions du fichier sur le système de fichiers.
- l'offset pointer qui est la tête de lecture/écriture dans le fichier
- une référence vers le fichier sur le système de fichiers. Dans un système de fichiers Unix, il s'agit généralement du numéro de l'inode du fichier ou d'un pointeur vers une structure contenant cet inode et des informations comme le dispositif de stockage sur lequel il est stocké.
A titre d'exemple, considérons l'exécution de la commande suivante depuis le shell :
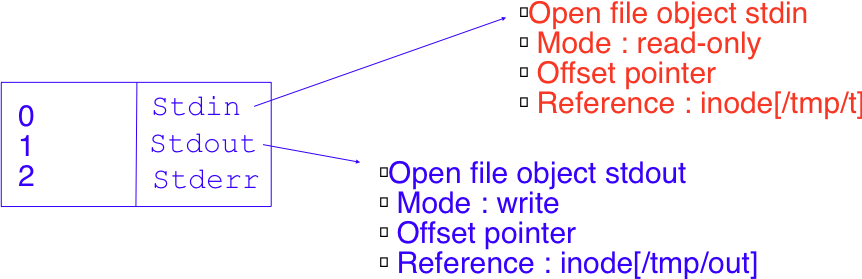
$ cat < /tmp/t > /tmp/out
Lors de son exécution, deux open file objects sont créés dans le noyau. Le premier est relatif au fichier /tmp/t qui est associé au descripteur stdin. Le second est lié au fichier /tmp/out et est associé au descripteur stdout. Ces open-file objects sont représentés graphiquement dans la figure ci-dessous.
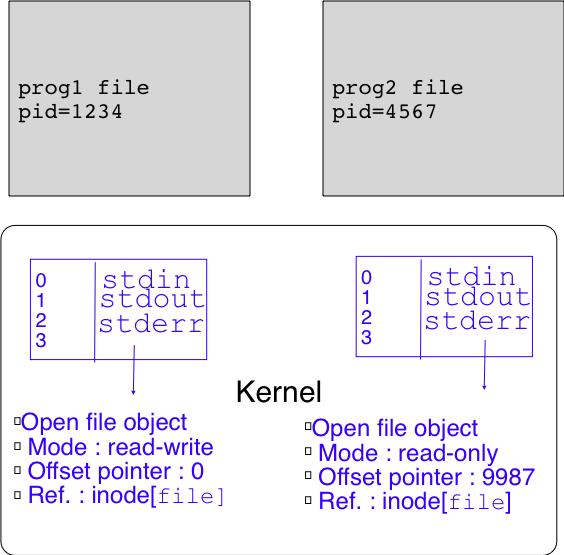
Les open file objects sont également utilisés lorsque plusieurs processus ouvrent le même fichier. Considérons l'exécution simultanée des deux commandes suivantes :
$ prog1 file &
$ prog2 file &
Lors de l'exécution de ces deux processus, le noyau va attribuer un descripteur de fichier à chacun d'eux. Si file est le premier fichier ouvert par chaque processus, il sera associé au descripteur 3. Le noyau créera un open-file object pour le fichier file utilisé par le processus prog1 et un autre open-file object pour le fichier file utilisé par le processus prog2. Ces deux open-file objects référencient le même inode et donc le même fichier, mais ils peuvent avoir des modes et des offset pointers qui sont totalement indépendants. Tous les accès faits par le processus prog2 sont complètement indépendants des accès faits par le processus prog1. Cette utilisation d'un même fichier par deux processus distincts est représentée graphiquement dans la figure ci-dessous.
Sous Unix et Linux, il est important d'analyser également ce qu'il se passe lors de la création d'un processus en utilisant l'appel système fork(2). Imaginons que le processus prog1 discuté ci-dessous effectue fork(2) après avoir ouvert le fichier file. Dans ce cas, le noyau du système d'exploitation va dupliquer la table des descripteurs de fichiers du processus père pour créer celle du processus fils. Le processus père et le processus fils ont donc chacun une table des descripteurs de fichiers qui leur est propre. Cela permet, comme nous l'avons vu lorsque nous avons présenté les pipes, que le fils ferme un de ses descripteurs de fichiers sans que cela n'ait d'impact sur l'utilisation de ce descripteur de fichier par le processus père. Par contre, l'exécution de l'appel système fork(2) ne copie pas les open-file objects. Après exécution de fork(2) le descripteur de fichiers 3 dans le processus père pointe vers l'open-file object associé au fichier file et le même descripteur dans le processus fils pointe vers le même open-file object. Cette situation est représentée schématiquement dans la figure ci-dessous.
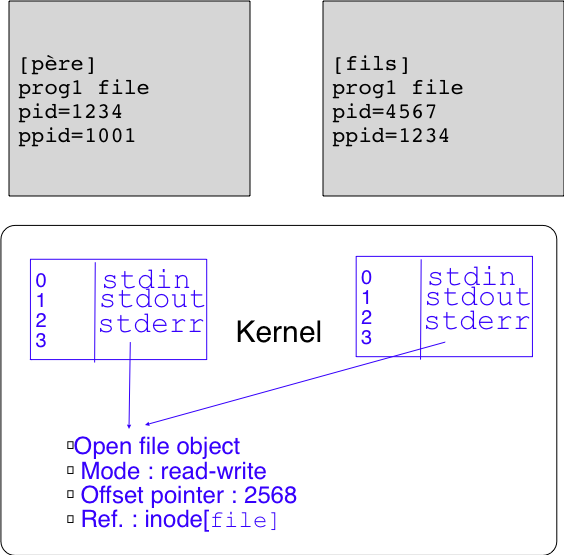
Cette utilisation d'un même open-file object par le processus père et le processus fils est une particularité importante de Unix. Elle permet aux deux processus d'écrire des données séquentiellement dans un fichier qui avait été initialement ouvert par le processus père, mais pose régulièrement des problèmes lors de la manipulation de fichiers.
Lorsqu'un fichier est utilisé par plusieurs processus simultanément, il est nécessaire de coordonner les activités de ces processus pour éviter que le fichier ne devienne corrompu. Outre les appels systèmes classiques open(2), read(2), write(2) et close(2), Unix offre plusieurs appels systèmes qui sont utiles lorsque plusieurs processus accèdent au même fichier.
Considérons d'abord un processus père et un processus fils qui doivent lire des données à des endroits particuliers dans un fichier. Pour cela, il est naturel d'utiliser l'appel système lseek(2) pour déplacer l'offset pointer et d'ensuite réaliser la lecture avec read(2). Malheureusement lorsqu'un père et un ou plusieurs fils [5] utilisent ces appels systèmes, il est possible qu'un appel à lseek(2) fait par le fils soit immédiatement suivi d'un appel à lseek(2) fait par le père avant que le fils ne puisse exécuter l'appel système read(2). Dans ce cas, le processus fils ne lira pas les données qu'il souhaitait lire dans le fichier. Les appels systèmes pread(2) et pwrite(2) permettent d'éviter ce problème. Ils complètent les appels systèmes read(2) et write(2) en prenant comme argument l'offset auquel la lecture ou l'écriture demandée doit être effectuée. pread(2) et pwrite(2) garantissent que les opérations d'écriture et de lecture qui sont effectuées avec ces appels systèmes seront atomiques.
#include <unistd.h> ssize_t pread(int fd, void *buf, size_t count, off_t offset); ssize_t pwrite(int fd, const void *buf, size_t count, off_t offset);
Ce n'est pas le seul problème qui se pose lorsque plusieurs processus manipulent un même fichier. Considérons un logiciel de base de données qui comprend des processus qui lisent dans des fichiers qui constituent la base de données et d'autres qui modifient le contenu de ces fichiers. Ces opérations d'écritures et de lectures dans des fichiers partagés risquent de provoquer des problèmes d'accès concurrent similaires aux problèmes que nous avons dû traiter lorsque plusieurs threads se partagent une même mémoire. Pour réguler ces accès à des fichiers, Unix et Linux supportent des verrous (locks en anglais) que l'on peut associer à des fichiers. A première vue, un lock peut être comparé à un mutex. Un lock permet à un processus d'obtenir l'accès exclusif à un fichier ou une partie de fichier tout comme un mutex est utilisé pour réguler les accès à une variable. En théorie, il existe deux techniques d'utilisation de locks qui peuvent être utilisées sur un système Unix :
- mandatory locking. Dans ce cas, les processus placent des locks sur certains fichiers ou zones de fichiers et le système d'exploitation vérifie qu'aucun accès fait aux fichiers avec les appels systèmes standards ne viole ces locks.
- advisory locking. Dans ce cas, les processus doivent vérifier eux-mêmes que les accès qu'ils effectuent ne violent pas les locks qui ont été associés aux différents fichiers.
Certains systèmes Unix supportent les deux stratégies de locking, mais la plupart ne supportent que l'advisory locking. L'advisory locking est la stratégie la plus facile à implémenter dans le système d'exploitation. C'est aussi celle qui donne les meilleures performances. Nous limitons notre description à l'advisory locking. Le mandatory locking nécessite un support spécifique du système de fichiers qui sort du cadre de ce cours.
Deux appels systèmes sont utilisés pour manipuler les locks qui peuvent être associés aux fichiers : flock(2) et fcntl(2). flock(2) est la solution la plus simple. Cet appel système permet d'associer un verrou à un fichier complet.
#include <sys/file.h>
int flock(int fd, int operation);
Il prend comme argument un descripteur de fichier et une opération. Deux types de locks sont supportés. Un lock est dit partagé (shared lock, operation==LOCK_SH) lorsque plusieurs processus peuvent posséder un même lock vers un fichier. Un lock est dit exclusif (exclusive lock, operation==LOCK_EX) lorsqu'un seul processus peut posséder un lock vers un fichier à un moment donné. Il faut noter que les locks sont associés aux fichiers (et donc indirectement aux inodes) et non aux descripteurs de fichiers. Pour retirer un lock associé à un fichier, il faut utiliser LOCK_UN comme second argument à l'appel flock(2).
L'appel système fcntl(2) et la fonction lockf(3) sont nettement plus flexibles. Ils permettent de placer des locks sur une partie d'un fichier. lockf(3) prend trois arguments : un descripteur de fichiers, une commande et un entier qui indique la longueur de la section du fichier à associer au lock.
#include <unistd.h>
int lockf(int fd, int cmd, off_t len);
lockf(3) supporte plusieurs commandes qui sont chacune spécifiées par une constante définie dans unistd.h. La commande F_LOCK permet de placer un lock exclusif sur une section du fichier dont le descripteur est le premier argument. Le troisième argument est la longueur de la section sur laquelle le lock doit être appliqué. Par convention, la section s'étend de la position actuelle de l'offset pointer (pos) jusqu'à pos+len-1 si len est positif et va de pos-len à pos-1 si len est négatif. Si len est nul, alors la section concernée par le lock va de pos à l'infini (c'est-à-dire jusqu'à la fin du fichier, même si celle-ci change après l'application du lock).
L'appel à lockf(3) bloque si un autre processus a déjà un lock sur une partie du fichier qui comprend celle pour laquelle le lock est demandé. La commande F_TLOCK est équivalente à F_LOCK avec comme différence qu'elle ne bloque pas si un lock existe déjà sur le fichier mais retourne une erreur. F_TEST permet de tester la présence d'un lock sans tenter d'acquérir ce lock contrairement à F_TLOCK. Enfin, la commande F_ULOCK permet de retirer un lock placé précédemment.
En pratique, lockf(3) doit s'utiliser de la même façon qu'un mutex. C'est-à-dire qu'un processus qui souhaite écrire de façon exclusive dans un fichier doit d'abord obtenir via lockf(3) un lock sur la partie du fichier dans laquelle il souhaite écrire. Lorsque l'appel à lockf(3) réussit, il peut effectuer l'écriture via write(2) et ensuite libérer le lock en utilisant lockf(3). Tout comme avec les mutex, si un processus n'utilise pas lockf(3) avant d'écrire ou de lire, cela causera des problèmes.
L'appel système fcntl(2) est un appel "fourre-tout" qui regroupe de nombreuses opérations qu'un processus peut vouloir faire sur un fichier. L'application de locks est une de ces opérations, mais la page de manuel en détaille de nombreuses autres. Lorsqu'il est utilisé pour manipuler des locks, l'appel système fcntl(2) utilise trois arguments :
#include <unistd.h>
#include <fcntl.h>
int fcntl(int fd, int cmd, struct flock* );
Le premier argument est le descripteur de fichiers sur lequel le lock doit être appliqué. Le second est la commande. Tout comme lockf(3), fcntl(2) supporte différentes commandes qui sont spécifiées dans la page de manuel. Le troisième argument est un pointeur vers une structure flock qui doit contenir au minimum les champs suivants :
struct flock {
...
short l_type; /* Type of lock: F_RDLCK,
F_WRLCK, F_UNLCK */
short l_whence; /* How to interpret l_start:
SEEK_SET, SEEK_CUR, SEEK_END */
off_t l_start; /* Starting offset for lock */
off_t l_len; /* Number of bytes to lock */
pid_t l_pid; /* PID of process blocking our lock
(F_GETLK only) */
...
};
Cette structure permet de spécifier plus finement qu'avec la fonction lockf(3) la section du fichier sur laquelle le lock doit être placé. L'utilisation de locks force le noyau à maintenir des structures de données supplémentaires pour stocker ces locks et les processus qui peuvent être en attente sur chacun de ces locks. Conceptuellement, cette structure de données est associée à chaque fichier comme représenté dans la figure ci-dessous.

Gestion des locks par le kernel
Comme les locks sont associés à des fichiers, le noyau doit maintenir pour chaque fichier ouvert une liste de locks. Celle-ci peut être implémentée sous la forme d'une liste chaînée comme représenté ci-dessus ou sous la forme d'une autre structure de données. Le point important est que le noyau doit mémoriser pour chaque fichier utilisant des locks quelles sont les sections du fichier qui sont concernées par chaque lock, quel est le type de lock, quel est le processus qui possède le lock (pour autoriser uniquement ce processus à le retirer) et enfin une liste ou une queue des processus qui sont en attente sur ce lock.
Sous Linux, le système de fichiers virtuel /proc fournit une interface permettant de visualiser l'état des locks. Il suffit pour cela de lire le contenu du fichier /proc/locks.
cat /proc/locks
1: POSIX ADVISORY WRITE 12367 00:17:20628657 0 0
2: POSIX ADVISORY WRITE 12367 00:17:7996086 0 0
3: POSIX ADVISORY WRITE 12367 00:17:24084665 0 0
4: POSIX ADVISORY WRITE 12367 00:17:12634137 0 0
5: POSIX ADVISORY WRITE 30677 00:17:14534587 1073741824 1073742335
6: POSIX ADVISORY READ 30677 00:17:25756362 128 128
7: POSIX ADVISORY READ 30677 00:17:25756359 1073741826 1073742335
8: POSIX ADVISORY READ 30677 00:17:25756319 128 128
9: POSIX ADVISORY READ 30677 00:17:25756372 1073741826 1073742335
10: POSIX ADVISORY WRITE 30677 00:17:25757269 1073741824 1073742335
11: POSIX ADVISORY WRITE 30677 00:17:25756354 0 EOF
12: FLOCK ADVISORY WRITE 22677 00:18:49578023 0 EOF
13: POSIX ADVISORY WRITE 3023 08:01:652873 0 EOF
14: POSIX ADVISORY WRITE 3014 08:01:652855 0 EOF
15: POSIX ADVISORY WRITE 2994 08:01:652854 0 EOF
16: FLOCK ADVISORY WRITE 2967 08:01:798437 0 EOF
17: FLOCK ADVISORY WRITE 2967 08:01:797391 0 EOF
18: FLOCK ADVISORY WRITE 1278 08:01:652815 0 EOF
Dans ce fichier, la première colonne indique le type de lock (POSIX pour un lock placé avec fcntl(2) ou lockf(3) et FLOCK pour un lock placé avec flock(2)). La deuxième indique si le lock est un advisory lock ou un mandatory lock. La troisième spécifie si le lock protège l'écriture et/ou la lecture. La quatrième colonne est l'identifiant du processus qui possède le lock. La cinquième précise le dispositif de stockage et le fichier concerné par ce lock (le dernier nombre est l'inode du fichier). Enfin, les deux dernières colonnes spécifient la section qui est couverte par le lock avec EOF qui indique la fin du fichier.
Footnotes
| [1] | Chaque processus appartient à groupe de processus. Ce groupe de processus peut être récupéré via l'appel système getpgrp(2). Par défaut, lorsqu'un processus est créé, il appartient au même groupe de processus que son processus père, mais il est possible de changer de groupe de
processus en utilisant l'appel système setpgid(2). En pratique, les groupes de processus sont surtout utilisés par le shell. Lorsqu'un utilisateur exécute une commande combinée telle que cat /tmp/t | ./a.out, il souhaite pouvoir l'arrêter en tapant sur Ctrl-C si nécessaire. Pour cela, il faut pouvoir délivrer le signal SIGINT aux processus cat et a.out. |
| [2] | Les autres appels systèmes lents sont open(2), write(2), sendto(2), recvfrom(2), sendmsg(2), recvmsg(2), wait(2) ioctl(2). |
| [3] | L'appel système sigaction(2) permet notamment de spécifier pour chaque signal si un appel système interrompu par ce signal doit être automatiquement redémarré lorsque le signal survient ou non. |
| [4] | Nous verrons dans le prochain chapitre comment plusieurs processus peuvent partager une même zone mémoire. |
| [5] | Même si il n'a pas été mentionné lors de l'utilisation de threads, ce problème se pose également lorsque plusieurs threads accèdent directement aux données dans un même fichier. |