Organisation des ordinateurs¶
Pour bien comprendre la façon dont les programmes s'exécutent sur un ordinateur, il est nécessaire de connaitre quelques principes de base sur l'architecture des ordinateurs et sur leur organisation.
Comme nous l'avons déjà abordé dans l'introduction, un principe fondateur est le modèle d'architecture de von Neumann. Ce modèle d'architecture a été introduit durant le développement des premiers ordinateurs pendant la seconde guerre mondiale mais reste tout à fait valide aujourd'hui [Krakowiak2011]. La partie la plus intéressante de ce modèle concerne les fonctions de calcul d'un ordinateur. Il postule qu'un ordinateur est organisé autour de deux types de dispositifs :
- L'unité centrale ou processeur. Cette unité centrale peut être décomposée en deux parties : l'unité de commande d'une part, et l'unité arithmétique et logique d'autre part. L'unité arithmétique et logique regroupe les circuits électroniques qui permettent d'effectuer les opérations arithmétiques (addition, soustraction, division, ...) et logiques (comparaisons, opérations binaires, ...). C'est cette unité qui réalise les calculs proprement dits. L'unité de commande permet quant à elle de charger, décoder et exécuter les instructions du programme qui sont stockées en mémoire (mise en œuvre du cycle fetch/decode/execute).
- La mémoire. Celle-ci joue un double rôle. Elle stocke à la fois les données qui sont traitées par le programme mais aussi les instructions qui composent celui-ci. Cette utilisation de la mémoire pour stocker les données et une représentation binaire du programme à exécuter est un des principes fondamentaux du fonctionnement des ordinateurs actuels.
Dans cette section du cours, nous allons étudier plus en détails le fonctionnement d'un système informatique moderne et introduire des considérations de technologie et de performance. Ensuite, nous verrons un exemple de jeu d'instruction illustrant le fonctionnement au plus bas niveau du couple processeur et mémoire.
Les technologies utilisées pour construire les processeurs et la mémoire ont fortement évolué depuis l'époque des premiers ordinateurs, mais les même principes fondamentaux restent d'application. En première approximation, on peut considérer la mémoire comme étant un dispositif qui permet de stocker des données binaires. La mémoire est découpée en blocs d'un octet. Chacun de ces blocs est identifié par une adresse, qui est elle aussi représentée sous la forme d'un nombre représenté en binaire. Une mémoire qui permet de stocker \(2^k\) bytes de données utilisera au minimum k bits pour représenter l'adresse d'une zone mémoire (i.e., l'adresse du premier octet de cette zone). Ainsi, une mémoire pouvant stocker 64 millions d'octets doit utiliser au moins 26 bits d'adresse. En pratique, les processeurs des ordinateurs de bureau utilisent 32 ou 64 bits pour représenter les adresses en mémoire. D'anciens processeurs utilisaient 16 ou 20 bits d'adresse. Le nombre de bits utilisés pour représenter une adresse en mémoire limite la capacité totale de mémoire adressable par un processeur. Ainsi, un processeur qui utilise des adresses sur 32 bits n'est pas capable physiquement d'adresser plus de 4 Go de mémoire.
En pratique, l'organisation physique d'un ordinateur est plus complexe que le modèle de von Neumann. Schématiquement, on peut considérer l'organisation présentée dans la figure ci-dessous, qui correspond à celle d'un ordinateur personnel classique au début des années 2010. Nous verrons dans la suite de ce cours que les ordinateurs plus récents utilisent une architecture plus complexe, mais il est utile d'étudier en détail ce modèle classique.
Le processeur est directement connecté à la mémoire via un bus de communication rapide. Ce bus permet des échanges de données et d'instructions entre la mémoire et le processeur. Le bus est aussi utilisé pour gérer les échanges dans les systèmes équipés de plusieurs processeurs. Outre le processeur et la mémoire, un troisième dispositif, souvent baptisé adaptateur de bus est connecté au bus reliant le processeur et la mémoire. Cet adaptateur permet au processeur d'accéder aux gestionnaire de périphériques afin d'interagir avec les dispositifs de stockage et avec les dispositifs d'entrées-sorties tels que le clavier, la souris ou les cartes réseau. En pratique, cela se réalise en connectant les différents dispositifs à un autre bus de communication (PCI, SCSI, ...) et en utilisant un adaptateur de bus qui est capable de traduire les commandes venant du processeur.
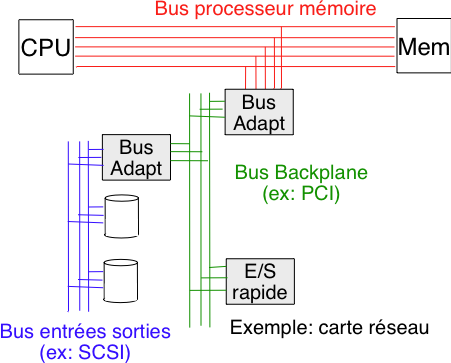
Architecture d'un ordinateur
Technologies de mise en œuvre des mémoires¶
Différentes technologies ont été employées pour construire les mémoires utilisées dans les ordinateurs. Aujourd'hui, les technologies les plus courantes sont les mémoires de type SRAM et les mémoires de type DRAM. Dans une SRAM, chaque bit d'information est stocké par un circuit composé de 4 à 6 transistors, et de quelques autres composants électroniques (résistances), mettant en oeuvre le principe de bascule. Une ligne d'information permet d'évaluer la valeur du bit stocké en observant le passage (ou non) d'un courant électrique dans ce circuit bascule, ce qui n'est possible que lorsque le bit stocké est 1. Une ligne de commande permet, par ailleurs, de mettre la valeur stockée à 0 ou 1. Avec une SRAM, les données restent stockées de manière statique tant que le circuit de mémoire est sous tension (d'où leur nom de static memory--SRAM). Malheureusement, les deux inconvénients majeurs de la SRAM est sa grande consommation électrique et le nombre important de composants électronique nécessaire pour chaque bit stocké, qui empêche de développer des mémoires de grande capacité à un prix raisonnable. Aujourd'hui, les SRAM les plus grandes ont une capacité de seulement quelques douzaines de Mo [HennessyPatterson].
Les DRAM sont totalement différentes des SRAM d'un point de vue de leur conception électronique.
Dans une mémoire de type DRAM, c'est la présence ou l'absence d'une charge (de quelques électrons à quelques dizaines d'électrons) dans un condensateur qui représente la valeur 0 ou 1.
Comme la charge du condensateur est perdue au cours du temps à cause des courants de fuite, il est nécessaire de la rétablir à son maximum de façon périodique.
C'est la raison pour laquelle on parle de mémoire dynamique : il est nécessaire de parcourir, à un certaine fréquence, l'ensemble des bits pour recharger les condensateurs représentant des 1.
Comme pour la mémoire SRAM les données sont perdues lorsque l'alimentation en électricité est coupée.
Il est possible de construire des DRAM de très grande taille, jusqu'à 8 voire même 32 Go par chip [HennessyPatterson]. C'est la raison pour laquelle on retrouve très largement des mémoires de type DRAM dans les ordinateurs. Malheureusement, leurs performances sont nettement moins bonnes que celles des mémoires de type SRAM. En pratique, une mémoire DRAM actuelle peut être vue comme étant équivalente à une grille [Drepper2007]. Les adresses peuvent être vues comme étant composées d'un numéro de colonne et d'un numéro de ligne. Pour lire ou écrire une donnée en mémoire DRAM, le contrôleur mémoire (intégré à la barrette mémoire, elle-même composée de plusieurs chips) doit d'abord sélectionner la ligne qu'elle souhaite lire et ensuite la colonne. Ces deux opérations sont successives. Lorsque la mémoire a reçu la ligne et la colonne demandées, elle peut commencer le transfert de la donnée. En pratique, les mémoires DRAM sont optimisées pour fournir un débit de transfert important, mais elles ont une latence élevée. Cela implique que dans une mémoire DRAM, il est plus rapide de lire ou d'écrire un bloc de 128 bits successifs que quatre blocs de 32 bits à des endroits différents en mémoire. À titre d'exemple, le tableau ci-dessous, extrait de [HP] fournit le taux de transfert maximum de différentes technologies de DRAM.
Technologie Fréquence [MHz] Débit [MB/sec] SDRAM 200 1064 RDRAM 400 1600 DDR-1 266 2656 DDR-2 333 5328 DDR-2 400 6400 DDR-3 400-667 6400-10600 DDR-4 800-1600 12800-25600
Le processeur interagit en permanence avec la mémoire, que ce soit pour charger des données à traiter ou pour charger les instructions à exécuter. Tant les données que les instructions sont représentées sous la forme de nombres en notation binaire. Certains processeurs utilisent des instructions de taille fixe. Par exemple, chaque instruction peut être encodée sous la forme d'un mot de 32 bits (4 octets). D'autres processeurs, comme ceux qui implémentent le jeu d'instructions [IA32], utilisent des instructions qui sont encodées sous la forme d'un nombre variable d'octets. Ces choix d'encodage des instructions influencent la façon dont les processeurs sont conçus d'un point de vue microélectronique, mais ont assez peu d'impact sur le développeur de programmes. L'élément qu'il est important de bien comprendre est que le processeur doit en permanence charger des données et des instructions depuis la mémoire lors de l'exécution d'un programme.
Outre des unités de calcul, un processeur contient plusieurs registres. Un registre est une zone de mémoire très rapide se trouvant au sein même du processeur. Sur les processeurs actuels, chacune de ces zones de mémoire permet de stocker un mot de 32 bits ou un long mot de 64 bits. Les tout premiers processeurs disposaient d'un registre unique baptisé l'accumulateur. Les processeurs actuels en contiennent généralement d'une à quelques dizaine(s). Chaque registre est identifié par un nom ou un numéro. Les instructions du processeur permettent d'accéder directement aux données se trouvant dans un registre particulier. Les registres sont les mémoires les plus rapides disponibles sur un ordinateur. Malheureusement, ils sont en nombre très limité. Il est donc impossible de faire fonctionner un programme non trivial en utilisant uniquement des registres.
Du point de vue des performances, il serait préférable de pouvoir construire un ordinateur équipé uniquement de SRAM. Malheureusement, au niveau de la capacité et du prix, c'est impossible sauf pour de rares applications bien spécifiques qui nécessitent de hautes performances et se contentent d'une capacité limitée. Les ordinateurs actuels utilisent donc conjointement de la mémoire SRAM et de la mémoire DRAM. Avec les registres, les SRAM et les DRAM composent les trois premiers niveaux de la hiérarchie de mémoire.
Le tableau ci-dessous compare les temps d'accès entre les mémoires SRAM et les mémoires DRAM à différentes périodes.
| Année | Accès SRAM | Accès DRAM |
|---|---|---|
| 1980 | 300 ns | 375 ns |
| 1985 | 150 ns | 200 ns |
| 1990 | 35 ns | 100 ns |
| 1995 | 15 ns | 70 ns |
| 2000 | 3 ns | 60 ns |
| 2005 | 2 ns | 50 ns |
| 2010 | 1.5 ns | 40 ns |
Cette évolution des temps d'accès doit être mise en parallèle avec l'évolution de la performance des processeurs. En 1980, le processeur Intel 8080 fonctionnait avec une horloge de 1 MHz et accédait à la mémoire jusqu'à une fois toutes les 1000 ns. A cette époque, la mémoire était donc nettement plus rapide que le processeur. En 1990, en revanche, un processeur Intel 80386 accédait à la mémoire en moyenne toutes les 50 ns. Couplé à une mémoire uniquement de type DRAM avec une latence de 100 ns, un processeur Intel 80386 était ralenti par cette mémoire. En 2000, le Pentium-III avait un cycle de 1.6 ns, plus rapide que les meilleures mémoires disponibles à l'époque, qu'elles soient de type SRAM ou DRAM. Il en resté de même depuis lors : les temps de cycle des processeurs sont désormais bien inférieurs au temps d'accès des mémoires. Cette différence de performance croissante entre la mémoire et le processeur est un des facteurs qui limitent les améliorations des performances de nombreux programmes.
Principe et intérêt de la mémoire cache¶
Une première solution pour combiner la SRAM et la DRAM serait de réserver par exemple les adresses basses à la SRAM qui est plus performante et d'utiliser la DRAM pour les adresses hautes. Avec cette solution, le programme stocké dans la SRAM pourrait s'exécuter plus rapidement que le programme stocké en DRAM. Afin de permettre à tous les programmes de pouvoir utiliser la SRAM, on pourrait imaginer que le système d'exploitation fournisse des fonctions qui permettent aux applications de demander la taille de la mémoire SRAM disponible et de déplacer des parties d'un programme et des données en SRAM. Ce genre de solution obligerait chaque application à pouvoir déterminer quelles sont les instructions à exécuter et quelles données doivent être placées en mémoire SRAM pour obtenir les meilleures performances. Même si en théorie, ce genre de solution est envisageable, en pratique, elle a très peu de chances de pouvoir fonctionner.
La deuxième solution est d'utiliser le principe de la mémoire cache. Une mémoire cache est une mémoire de faible capacité mais rapide. La mémoire cache peut stocker des données provenant de mémoires de plus grande capacité mais plus lentes. Cette mémoire cache sert d'interface entre le processeur et la mémoire principale. Toutes les demandes d'accès à la mémoire principale passent par la mémoire cache comme illustré dans la figure ci-dessous.
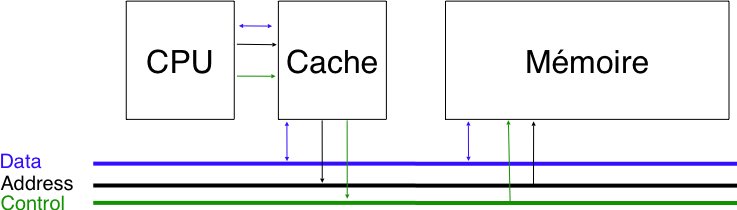
Le processeur, la mémoire cache et la mémoire principale
On utilise des mémoires cache dans de nombreux systèmes informatiques de façon à améliorer leurs performances. Ces mémoires cache profitent du principe de localité. En pratique, deux types de localité doivent être considérés. Tout d'abord, il y a la localité temporelle. Si un processeur a accédé à la mémoire à l'adresse A à l'instant t, il est fort probable qu'il accédera encore à cette adresse dans les instants qui suivent. La localité temporelle apparaît notamment lors de l'exécution de longues boucles qui exécutent à de nombreuses reprises les mêmes instructions. Le second type de localité est la localité spatiale. Celle-ci implique que si un programme a accédé à l'adresse A à l'instant t, il est fort probable qu'il accédera aux adresses proches de A comme A+4 ou A-4 dans les instants qui suivent. Cette localité apparaît par exemple lorsqu'un programme traite un vecteur stocké en mémoire.
Les mémoires caches exploitent ces principes de localité en stockant de façon transparente les instructions et les données les plus récemment utilisées. D'un point de vue physique, on peut voir le processeur comme étant connecté à la (ou parfois les) mémoire cache qui est elle-même connectée à la mémoire RAM. Les opérations de lecture en mémoire se déroulent généralement comme suit. Chaque fois que le processeur a besoin de lire une donnée se trouvant à une adresse, il fournit l'adresse demandée à la mémoire cache. Si la donnée correspondant à cette adresse est présente en mémoire cache, celle-ci répond directement au processeur. Sinon, la mémoire cache interroge la mémoire RAM, se met à jour et ensuite fournit la donnée demandée au processeur. Ce mode de fonctionnement permet à la mémoire cache de se mettre à jour au fur et à mesure des demandes faites par le processeur afin de profiter de la localité temporelle. Pour profiter de la localité spatiale, la plupart des caches se mettent à jour en chargeant directement une ligne de cache qui peut compter jusqu'à quelques dizaines d'adresses consécutives en mémoire (par exemple, 64 octets sur la plupart des processeurs modernes). Ce chargement d'une ligne complète de cache permet également de profiter des mémoires DRAM récentes qui sont souvent optimisées pour fournir des débits de transfert élevés pour de longs blocs consécutifs en mémoire. La figure ci-dessous illustre graphiquement la hiérarchie de mémoires dans un ordinateur.
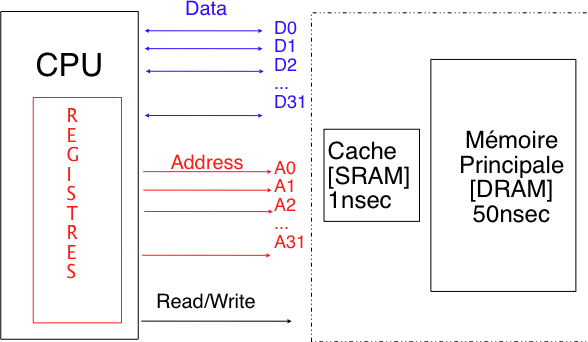
La hiérarchie de mémoires
Pour les opérations d'écriture, la situation est plus compliquée. Si le processeur écrit l'information x à l'adresse A en mémoire, il faudrait idéalement que cette valeur soit écrite simultanément en mémoire cache et en mémoire RAM de façon à s'assurer que la mémoire RAM contienne toujours des données à jour. La stratégie d'écriture la plus simple est baptisée write through. Avec cette stratégie, toute demande d'écriture venant du processeur donne lieu à une écriture en mémoire cache et une écriture en mémoire RAM. Cette stratégie garantit qu'à tout moment la mémoire cache et la mémoire RAM contiennent la même information. Malheureusement, d'un point de vue des performances, cette technique rabaisse les performances de la mémoire cache à celles de la mémoire RAM. Vu les différences de performance et de prix entre les deux types de mémoires, cette stratégie n'est plus acceptable aujourd'hui. L'alternative est d'utiliser la technique du write back. Avec cette technique, toute écriture est faite en mémoire cache directement. Cela permet d'obtenir de très bonnes performances pour les écritures. Une donnée modifiée n'est réécrite en mémoire RAM que lorsqu'elle doit être retirée de la mémoire cache. Cette écriture est faite automatiquement par le gestionnaire matériel de mémoire cache, désormais toujours intégré au processeur. Pour la plupart des programmes, la gestion des opérations d'écriture est transparente. Il faut cependant être attentif à la technique d'écriture utilisée lorsque plusieurs dispositifs peuvent accéder directement à la mémoire RAM sans passer par le processeur. C'est le cas par exemple pour certaines cartes réseaux ou certains contrôleurs de disque dur. Pour des raisons de performances, ces dispositifs peuvent copier des données directement de la mémoire RAM vers le réseau ou un disque dur, en utilisant le principe de Direct Memory Access (DMA) présenté dans l'introduction de ce cours. Si une écriture de type write-back est utilisée, le système d'exploitation doit veiller à ce que les données écrites par le processeur en cache aient bien été écrites également en mémoire RAM avant d'autoriser la carte réseau ou le contrôleur de disque à effectuer un transfert en utilisant DMA.
Etude de cas : Architecture IA32¶
Pour comprendre le fonctionnement d'un microprocesseur, la solution la plus efficace est de considérer une architecture en particulier et de voir comment fonctionnent les processeurs qui la mettent en œuvre. Dans cette section, nous analysons brièvement le fonctionnement des processeurs [1] de la famille [IA32].
Cette architecture recouvre un grand nombre de variantes qui ont leur spécificités propre. Une descriptions détaillée de cette architecture est disponible dans [IA32]. Nous nous limiterons à un très petit sous-ensemble de cette architecture dans le cadre de ce cours. Une analyse complète de l'architecture [IA32] occupe plusieurs centaines de pages dans des livres de référence [BryantOHallaron2011] [Hyde2010].
L'architecture [IA32] est supportée par différents types de processeurs. Certains utilisent des registres et des bus de données de 32 bits. D'autres, plus récents utilisent des registres de 64 bits. Il y a des différences importantes entre ces deux architectures. Comme les processeurs récents supportent à la fois les modes 32 bits et 64 bits, nous nous limiterons à l'architecture 32 bits.
Un des éléments importants d'un processeur tel que ceux de l'architecture [IA32] sont ses registres. Un processeur [IA32] dispose de huit registres génériques. Ceux-ci ont été baptisés EAX, EBX, ECX, EDX, EBP, ESI, EDI et ESP. Ces registres peuvent stocker des données sous forme binaire. Dans l'architecture [IA32], ils ont une taille de 32 bits. Cela implique que chaque registre peut contenir un nombre ou une adresse puisque les entiers (int en C) et les adresses (pointeurs * en C sur [IA32]) sont tous les deux encodés sur 32 bits dans l'architecture [IA32]. Cette capacité à stocker des données ou des adresses à l'intérieur d'un même registre est un des points clés de la flexibilité des microprocesseurs.
Deux de ces registres, EBP et ESP sont utilisés dans la gestion de la pile comme nous le verrons plus tard. Les autres registres peuvent être utilisés directement par le programmeur. En outre, tout processeur contient un registre spécial qui stocke à tout moment l'adresse de l'instruction courante en mémoire. Ce registre est souvent dénommé le compteur de programme ou program counter (PC) en anglais. Dans l'architecture [IA32], c'est le registre EIP qui stocke l'Instruction Pointer qui joue ce rôle. Ce registre ne peut pas être utilisé pour effectuer des opérations arithmétiques. Il peut cependant être modifié par les instructions de saut comme nous le verrons plus tard et joue un rôle essentiel dans l'implémentation des instructions de contrôle.
Outre ces registres génériques, les processeurs de la famille [IA32] contiennent aussi des registres spécialisés pour manipuler les nombres en virgule flottante (float et double). Nous ne les analyserons pas dans le cadre de ce cours. Par contre, les processeurs [IA32] contiennent également des drapeaux regroupés dans le registre eflags. Ceux-ci sont utilisés pour implémenter différents tests et comparaisons.
Les processeurs qui implémentent les spécifications [IA32] supportent les types de données repris dans le tableau ci-dessous.
Type Taille (bytes) Suffixe assembleur char1 b short2 w int4 l long int4 l void *4 l
Dans les sections qui suivent, nous analysons quelques instructions de l'architecture [IA32] qui permettent de manipuler des nombres entiers en commençant par les instructions de transfert entre la mémoire et les registres.
Les instructions mov¶
Les instructions de la famille mov [2] permettent de déplacer des données entre registres ou depuis la mémoire vers un registre ou enfin d'un registre vers une zone mémoire. Ces instructions sont essentielles car elles permettent au processeur de récupérer les données qui sont stockées en mémoire mais aussi de sauvegarder en mémoire le résultat d'un calcul effectué par le processeur. Une instruction mov contient toujours deux arguments. Le premier spécifie la donnée à déplacer ou son adresse et la seconde l'endroit où il faut sauvegarder cette donnée ou la valeur stockée à cette adresse.
mov src, dest ; déplacement de src vers dest
Il existe une instruction de la famille mov qui correspond à chaque type de donnée pouvant être déplacé. L'instruction movb est ainsi utilisée pour déplacer un byte (octet), movw pour déplacer un mot de 16 bits et movl lorsqu'il faut déplacer un mot de 32 bits.
En pratique, il y a plusieurs façons de spécifier chaque argument d'une instruction mov. Certains auteurs utilisent le terme mode d'adressage pour représenter ces différents types d'arguments même si il ne s'agit pas toujours d'adresses.
Le premier mode est le mode registre. La source et la destination d'une opération mov peuvent être un nom de registre. Ceux-ci sont en général préfixés avec le caractère %. Ainsi, %eax correspond au registre EAX. La première instruction ci-dessous copie le mot de 32 bits stocké dans le registre %eax vers le registre %ebx. La seconde instruction elle n'a aucun effet puisqu'elle déplace le contenu du registre %ecx vers ce même registre.
movl %eax, %ebx ; déplacement de %eax vers %ebx
movl %ecx, %ecx ; aucun effet
Le deuxième mode d'adressage est le mode immédiat. Celui-ci ne peut être utilisé que pour l'argument source. Il permet de placer une constante dans un registre, par exemple pour initialiser sa valeur comme dans les exemples ci-dessous. Il se reconnaît à l'utilisation du symbole $ comme préfixe de la constante.
movl $0, %eax ; initialisation de %eax à 0
movl $1252, %ecx ; initialisation de %ecx à 1252
Le troisième mode d'adressage est le mode absolu. Dans ce mode, l'un des arguments de l'instruction mov est une adresse en mémoire. Si la source est une adresse, alors l'instruction movl transfère le mot de 32 bits stocké à l'adresse spécifiée comme source vers le registre spécifié comme destination. Si la destination est une adresse, alors l'instruction movl sauvegarde la donnée source à cette adresse en mémoire. Pour illustrer cette utilisation de l'instruction mov, considérons la mémoire illustrée ci-dessous.
Adresse Valeur 0x10 0x04 0x0C 0x10 0x08 0xFF 0x04 0x00 0x00 0x04
Les instructions ci-dessous sont un exemple de déplacement de données entre la mémoire et un registre et d'un registre vers la mémoire.
movl 0x04, %eax ; place la valeur 0x00 (qui se trouve à l'adresse 0x04) dans %eax
movl $1252, %ecx ; initialisation de %ecx à 1252
movl %ecx, 0x08 ; remplace 0xFF par le contenu de %ecx (1252) à l'adresse 0x08
Le quatrième mode d'adressage est le mode indirect. Plutôt que de spécifier directement une adresse, avec le mode indirect, on spécifie un registre dont la valeur est une adresse en mémoire. Ce mode indirect est équivalent à l'utilisation des pointeurs en langage C. Il se reconnait à l'utilisation de parenthèses autour du nom du registre source ou destination. L'exemple ci-dessous illustre l'utilisation de l'adressage indirect en considérant la mémoire présentée plus haut.
movl $0x08, %eax ; place la valeur 0x08 dans %eax
movl (%eax), %ecx ; place la valeur se trouvant à l'adresse qui est
; dans %eax dans le registre %ecx : %ecx=0xFF
movl 0x10, %eax ; place la valeur se trouvant à l'adresse 0x10 dans %eax
movl %ecx, (%eax) ; place le contenu de %ecx, c'est-à-dire 0xFF à l'adresse qui est contenue dans %eax (0x10)
Le cinquième mode d'adressage est le mode avec une base et un déplacement. Ce mode peut être vu comme une extension du mode indirect. Il permet de lire en mémoire à une adresse qui est obtenue en additionnant un entier, positif ou négatif, à une adresse stockée dans un registre. Ce mode d'adressage joue un rôle important dans le fonctionnement de la pile comme nous le verrons d'ici peu.
movl $0x08, %eax ; place la valeur 0x08 dans %eax
movl 0(%eax), %ecx ; place la valeur (0xFF) se trouvant à l'adresse
; 0x08= (0x08+0) dans le registre %ecx
movl 4(%eax), %ecx ; place la valeur (0x10) se trouvant à l'adresse
; 0x0C (0x08+4) dans le registre %ecx
movl -8(%eax), %ecx ; place la valeur (0x04) se trouvant à l'adresse
; 0x00 (0x08-8) dans le registre %ecx
L'architecture [IA32] supporte encore d'autres modes d'adressage. Ceux sont décrits dans [IA32] ou [BryantOHallaron2011]. Une autre instruction permettant de déplacer de l'information est l'instruction leal (load effective address). Cette instruction est parfois utilisée par les compilateurs. Elle place dans le registre destination l'adresse de son argument source plutôt que sa valeur. Ainsi leal 4(%esp) %edx placera dans le registre %edx l'adresse de son argument source, c'est-à-dire l'adresse contenue dans %esp additionnée de la valeur 4.
Pas de déplacement entre deux adresses
On pourrait vouloir écrire l'instruction movl 0x04, 0x02 pour copier le contenu de la mémoire à l'adresse 0x04 à l'adresse 0x02, ou bien écrire movl (%eax), (%ebx) pour copier le contenu de la mémoire à l'adresse pointée par le contenu du registre EAX vers l'adresse pointée par le contenu du registre EBX.
Ces deux opérations ne sont pas permises dans le jeu d'instruction [IA32], et il est donc nécessaire de passer par un registre intermédiaire.
D'autres architectures peuvent supporter l'utilisation de deux adresses mémoires dans une instruction, ici il s'agit d'un choix des concepteurs du jeu d'instruction qui permet de limiter la complexité de mise en oeuvre des processeurs le supportant.
Instructions arithmétiques et logiques¶
La deuxième famille d'instructions importante sur un processeur sont les instructions qui permettent d'effectuer les opérations arithmétiques et logiques. Voici quelques exemples d'instructions arithmétiques et logiques supportées par l'architecture [IA32].
Les instructions les plus simples sont celles qui prennent un seul argument. Il s'agit de :
incqui incrémente d'une unité la valeur stockée dans le registre/l'adresse fournie en argument et sauvegarde le résultat de l'incrémentation au même endroit. Cette instruction peut être utilisée pour implémenter des compteurs de boucles.decest équivalente àincmais décrémente son argument.notqui applique l'opération logiqueNOTà son argument et stocke le résultat à cet endroit
Il existe une variante de chacune de ces instructions pour chaque type de données à manipuler. Cette variante se reconnait grâce au dernier caractère de l'instruction (b pour byte, w pour un mot de 16 bits et l pour un mot de 32 bits). Nous nous limiterons aux instructions qui manipulent des mots de 32 bits.
movl $0x12345678, %ecx ; initialisation
notl %ecx ; calcul de NOT
movl $0, %eax ; %eax=0
incl %eax ; %eax++
L'architecture [IA32] supporte également des instructions arithmétiques et logiques prenant chacune deux arguments.
addpermet d'additionner deux nombres entiers.addprend comme arguments une source et une destination et place dans la destination la somme de ses deux arguments;subpermet de soustraire le premier argument du second et stocke le résultat dans le second;mulpermet de multiplier des nombres entiers non-signés (imulest le pendant demulpour la multiplication de nombres signés);divpermet la division de nombres entiers non-signés;shl(resp.shr) permet de réaliser un décalage logique vers la gauche (resp. droite);xorcalcule un ou exclusif entre ses deux arguments et sauvegarde le résultat dans le second;andcalcule la conjonction logique entre ses deux arguments et sauvegarde le résultat dans le second.
Pour illustrer le fonctionnement de ces instructions, considérons une mémoire hypothétique contenant les données suivantes. Supposons que la variable entière a est stockée à l'adresse 0x04, b à l'adresse 0x08 et c à l'adresse 0x0C.
Adresse Variable Valeur 0x0C c 0x00 0x08 b 0xFF 0x04 a 0x02 0x00
0x01
Les trois premières instructions ci-dessous sont équivalentes à l'expression C a=a+1;.
Pour implémenter une telle opération en langage d'assemblage, il faut d'abord charger la valeur de la variable dans un registre.
Ensuite, le processeur effectue l'opération arithmétique.
Enfin, le résultat est sauvegardé en mémoire.
Après ces trois instructions, la valeur 0x03 est stockée à l'adresse 0x04 qui correspond à la variable a.
Les trois dernières instructions calculent a=b-c;.
On remarquera que le programmeur a choisi de d'abord charger la valeur de la variable b dans le registre %eax.
Ensuite, il utilise l'instruction subl en mode d'adressage immédiat pour placer dans %eax le résultat de la soustraction entre %eax et la donnée se trouvant à l'adresse 0x0C.
Enfin, le contenu de %eax est sauvé à l'adresse correspondant à la variable a.
movl 0x04, %eax ; %eax=a
addl $1, %eax ; %eax++
movl %eax, 0x04 ; a=%eax
movl 0x08, %eax ; %eax=b
subl 0x0c, %eax ; %eax=b-c
movl %eax, 0x04 ; a=%eax
L'exemple ci-dessous présente la traduction directe [3] d'un fragment de programme C utilisant des variables globales en langage assembleur.
int j,k,g,l;
// ...
l=g^j;
j=j|k;
g=l<<6;
Dans le code assembleur, les noms de variables tels que g ou j correspondent à l'adresse mémoire à laquelle la variable est stockée.
movl g, %eax ; %eax=g
xorl j, %eax ; %eax=g^j
movl %eax, l ; l=%eax
movl j, %eax ; %eax=j
orl k, %eax ; %eax=j|k
movl %eax, j ; j=%eax
movl l, %eax ; %eax=l
shll $6, %eax ; %eax=%eax << 6
movl %eax, g ; g=%eax
Les opérations arithmétiques telles que la multiplication ou la division sont plus complexes que les opérations qui ont été présentées ci-dessus. En toute généralité, la multiplication entre deux nombres de 32 bits peut donner un résultat sur 64 bits qui ne pourra donc pas être stocké entièrement dans un registre. De la même manière, une division entière retourne un quotient et un reste qui sont tous les deux sur 32 bits. L'utilisation des instructions de division et de multiplication nécessite de prendre ces problèmes en compte. Nous ne les aborderons pas dans ce cours. Des détails complémentaires sont disponibles dans [IA32] et [BryantOHallaron2011] notamment.
Les instructions de comparaison¶
Outre les opérations arithmétiques, un processeur doit être capable de réaliser des comparaisons. Ces comparaisons sont nécessaires pour implémenter des tests tels que if (condition) { ... } else { ... }. Sur les processeurs [IA32], les comparaisons utilisent des drapeaux qui sont mis à jour par le processeur après l'exécution de certaines instructions. Ceux-ci sont regroupés dans le registre eflags. Les principaux drapeaux sont :
- ZF (Zero Flag) : ce drapeau indique si le résultat de la dernière opération était zéro
- SF (Sign Flag) : indique si le résultat de la dernière instruction était négatif
- CF (Carry Flag) : indique si le résultat de la dernière instruction arithmétique non signée nécessitait plus de 32 bits pour être stocké
- OF (Overflow Flag) : indique si le résultat de la dernière instruction arithmétique signée a provoqué un dépassement de capacité
Nous utiliserons principalement les drapeaux ZF et SF dans ce chapitre. Ces drapeaux peuvent être fixés par les instructions arithmétiques standard, mais aussi par des instructions dédiées comme cmp et test. L'instruction cmp effectue l'équivalent d'une soustraction et met à jour les drapeaux CF et SF mais sans sauvegarder son résultat dans un registre. L'instruction test effectue elle une conjonction logique sans sauvegarder son résultat mais en mettant à jour les drapeaux.
Ces instructions de comparaison peuvent être utilisées avec les instructions set qui permettent de fixer la valeur d'un registre en fonction des valeurs de certains drapeaux du registre eflags. Chaque instruction set prend comme argument un registre. Pour des raisons historiques, ces instructions modifient uniquement les 8 bits de poids faible du registre indiqué et non le registre complet. C'est un détail qui est lié à l'histoire de l'architecture [IA32].
setemet le registre argument à la valeur du drapeau ZF. Permet d'implémenter une égalité.setsmet le registre argument à la valeur du drapeau SFsetgplace dans le registre argument la valeur~SF & ~ZF(tout en prenant en compte les dépassements éventuels avec OF). Permet d'implémenter la condition>.setlplace dans le registre argument la valeur deSF(tout en prenant en compte les dépassements éventuels avec OF). Permet d'implémenter notamment la condition<=.
A titre d'illustration, voici quelques expressions logiques en C et leur implémentation en assembleur lorsque les variables utilisées sont toutes des variables globales.
r=(h>1);
r=(j==0);
r=g<=h;
r=(j==h);
Le programme assembleur utilise une instruction cmpl pour effectuer la comparaison. Ensuite, une instruction set permet de fixer la valeur du byte de poids faible de %eax et une instruction (movzbl) permettant de transformer ce byte en un mot de 32 bits afin de pouvoir le stocker en mémoire. Cette traduction a été obtenue avec llvm, d'autres compilateurs peuvent générer du code un peu différent.
cmpl $1, h ; comparaison
setg %al ; %al est le byte de poids faible de %eax
movzbl %al, %ecx ; copie le byte dans %ecx
movl %ecx, r ; sauvegarde du résultat dans r
cmpl $0, j ; comparaison
sete %al ; fixe le byte de poids faible de %eax
movzbl %al, %ecx
movl %ecx, r ; sauvegarde du résultat dans r
movl g, %ecx
cmpl h, %ecx ; comparaison entre g et h
setl %al ; fixe le byte de poids faible de %eax
movzbl %al, %ecx
movl %ecx, r
movl j, %ecx
cmpl h, %ecx ; comparaison entre j et h
sete %al
movzbl %al, %ecx
movl %ecx, r
Les instructions de saut¶
Les instructions de saut sont des instructions de base pour tous les processeurs. Elles permettent de modifier la valeur du compteur de programme %eip de façon à modifier l'ordre d'exécution des instructions. Elles sont nécessaires pour implémenter les tests, les boucles et les appels de fonction. Les premiers langages de programmation et des langages tels que BASIC ou FORTRAN disposent d'une construction similaire avec l'instruction goto. Cependant, l'utilisation de l'instruction goto dans des programmes de haut niveau rend souvent le code difficile à lire et de nombreux langages de programmation n'ont plus de goto [Dijkstra1968]. Contrairement à Java, le C contient une instruction goto, mais son utilisation est fortement découragée. En C, l'instruction goto prend comme argument une étiquette (label en anglais). Lors de l'exécution d'un goto, le programme saute directement à l'exécution de l'instruction qui suit le label indiqué. Ceci est illustré dans l'exemple ci-dessous :
int v=0;
for(int i=0;i<SIZE;i++)
for(int j=0;j<SIZE;j++) {
if(m[i][j]>MVAL) {
v=m[i][j];
goto suite;
}
}
printf("aucune valeur supérieure à %d\n",MVAL,v);
goto fin;
suite:
printf("première valeur supérieure à %d : %d\n",MVAL,v);
fin:
return(EXIT_SUCCESS);
Si l'utilisation goto est en pratique prohibée dans la plupart des langages de programmation, en assembleur, les instructions de saut sont inévitables. L'instruction de saut la plus simple est jmp. Elle prend généralement comme argument une étiquette. Dans ce cas, l'exécution du programme après l'instruction jmp se poursuivra par l'exécution de l'instruction qui se trouve à l'adresse correspondant à l'étiquette fournie en argument. Il est également possible d'utiliser l'instruction jmp avec un registre comme argument. Ainsi, l'instruction jmp %eax indique que l'exécution du programme doit se poursuivre par l'exécution de l'instruction se trouvant à l'adresse qui est contenue dans le registre %eax.
Il existe plusieurs variantes conditionnelles de l'instruction jmp. Ces variantes sont exécutées uniquement si la condition correspondante est vérifiée. Les variantes les plus fréquentes sont :
je: saut si égal (teste le drapeau ZF) (inverse :jne)js: saut si négatif (teste le drapeau SF) (inverse :jns)jg: saut si strictement supérieur (teste les drapeaux SF et ZF et prend en compte un overflow éventuel) (inverse :jl)jge: saut si supérieur ou égal (teste le drapeaux SF et prend en compte un overflow éventuel) (inverse :jle)
Ces instructions de saut conditionnel sont utilisées pour implémenter notamment des expressions if (condition) { ... } else { ... } en C. Voici quelques traductions réalisées par un compilateur C en guise d'exemple.
if(j==0)
r=1;
if(j>g)
r=2;
else
r=3;
if (j>=g)
r=4;
Avant d'analyser la traduction de ce programme en assembleur, il est utile de le réécrire en utilisant l'instruction goto afin de s'approcher du fonctionnement de l'assembleur.
if(j!=0) { goto diff; }
r=1;
diff:
// suite
if(j<=g) { goto else; }
r=2;
goto fin;
else:
r=3;
fin:
// suite
if (j<g) { goto suivant; }
r=4;
suivant:
Ce code C correspond assez bien au code assembleur produit par le compilateur.
cmpl $0, j ; j==0 ?
jne .LBB2_2 ; jump si j!=0
movl $1, r ; r=1
.LBB2_2:
movl j, %eax ; %eax=j
cmpl g, %eax ; j<=g ?
jle .LBB2_4 ; jump si j<=g
movl $2, r ; r=2
jmp .LBB2_5 ; jump fin expression
.LBB2_4:
movl $3, r ; r=3
.LBB2_5:
movl j, %eax ; %eax=j
cmpl g, %eax ; j<g ?
jl .LBB2_7 ; jump si j<g
movl $4, r ; r=4
.LBB2_7:
Les instructions de saut conditionnel interviennent également dans l'implémentation des boucles. Plusieurs types de boucles existent en langage C. Considérons tout d'abord une boucle while.
while(j>0)
{
j=j-3;
}
Cette boucle peut se réécrire en utilisant des goto comme suit.
debut:
if(j<=0) { goto fin; }
j=j-3;
goto debut;
fin:
On retrouve cette utilisation des instructions de saut dans la traduction en assembleur de cette boucle.
.LBB3_1:
cmpl $0, j ; j<=0
jle .LBB3_3 ; jump si j<=0
movl j, %eax
subl $3, %eax
movl %eax, j ; j=j-3
jmp .LBB3_1
.LBB3_3:
Les boucles for s'implémentent également en utilisant des instructions de saut.
for(j=0;j<10;j++)
{ g=g+h; }
for(j=9;j>0;j=j-1)
{ g=g-h; }
La première boucle démarre par l'initialisation de la variable j à 0. Ensuite, la valeur de cette variable est comparée avec 10. L'instruction jge fait un saut à l'adresse mémoire correspondant à l'étiquette .LBB4_4 si la comparaison indique que j>=10. Sinon, les instructions suivantes calculent g=g+h et j++ puis l'instruction jmp relance l'exécution à l'instruction de comparaison qui est stockée à l'adresse de l'étiquette .LBB4_1.
movl $0, j ; j=0
.LBB4_1:
cmpl $10, j
jge .LBB4_4 ; jump si j>=10
movl g, %eax ; %eax=g
addl h, %eax ; %eax+=h
movl %eax, g ; g=%eax
movl j, %eax ; %eax=j
addl $1, %eax ; %eax++
movl %eax, j ; j=%eax
jmp .LBB4_1
.LBB4_4:
movl $9, j ; j=9
.LBB4_5:
cmpl $0, j
jle .LBB4_8 ; jump si j<=0
movl g, %eax
subl h, %eax
movl %eax, g
movl j, %eax ; %eax=j
subl $1, %eax ; %eax--
movl %eax, j ; j=%eax
jmp .LBB4_5
.LBB4_8:
La seconde boucle est organisée de façon similaire.
Manipulation de la pile¶
Les instructions mov permettent de déplacer de l'information à n'importe quel endroit de la mémoire. A côté de ces instructions de déplacement, il y a des instructions qui sont spécialisées dans la manipulation de la pile. La pile, qui dans l'espace mémoire d'un processus Unix est stockée dans les adresses hautes est essentielle au bon fonctionnement des programmes. Par convention dans l'architecture [IA32], l'adresse du sommet de la pile est toujours stockée dans le registre %esp. Deux instructions spéciales permettent de rajouter et de retirer une information au sommet de la pile.
pushl %reg: place le contenu du registre%regau sommet de la pile et décrémente dans le registre%espl'adresse du sommet de la pile de 4 unités.popl %reg: retire le mot de 32 bits se trouvant au sommet de la pile, le sauvegarde dans le registre%reget incrémente dans le registre%espl'adresse du sommet de la pile de 4 unités.
En pratique, ces deux instructions peuvent également s'écrire en utilisant des instructions de déplacement et des instructions arithmétiques. Ainsi, pushl %ebx est équivalent à :
subl $4, %esp ; ajoute un bloc de 32 bits au sommet de la pile
movl %ebx, (%esp) ; sauvegarde le contenu de %ebx au sommet
Tandis que popl %ecx est équivalent à :
movl (%esp), %ecx ; sauve dans %ecx la donnée au sommet de la pile
addl $4, %esp ; déplace le sommet de la pile de 4 unites vers le haut
Pour bien comprendre le fonctionnement de la pile, il est utile de considérer un exemple simple. Imaginons la mémoire ci-dessous et supposons qu'initialement le registre %esp contient la valeur 0x0C et que les registres %eax et %ebx contiennent les valeurs 0x02 et 0xFF.
Adresse Valeur 0x10 0x04 0x0C 0x00 0x08 0x00 0x04 0x00 0x00 0x00
push %eax ; %esp contient 0x08 et M[0x08]=0x02
push %ebx ; %esp contient 0x04 et M[0x04]=0xFF
pop %eax ; %esp contient 0x08 et %eax 0xFF
pop %ebx ; %esp contient 0x0C et %ebx 0x02
pop %eax ; %esp contient 0x10 et %eax 0x00
Les fonctions et procédures¶
Les fonctions et les procédures sont essentielles dans tout langage de programmation. Une procédure est une fonction qui ne retourne pas de résultat. Nous commençons par expliquer comment les procédures peuvent être implémentées en assembleur et nous verrons ensuite comment implémenter les fonctions.
Une procédure est un ensemble d'instructions qui peuvent être appelées depuis n'importe quel endroit du programme. Généralement, une procédure est appelée depuis plusieurs endroits différents d'un programme. Pour comprendre l'implémentation des procédures, nous allons considérer des procédures de complexité croissante. Nos premières procédures ne prennent aucun argument. En C, elles peuvent s'écrire sous la forme de fonctions void comme suit.
int g=0;
int h=2;
void increase() {
g=g+h;
}
void init_g() {
g=1252;
}
int main(int argc, char *argv[]) {
init_g();
increase();
return(EXIT_SUCCESS);
}
Ces deux procédures utilisent et modifient des variables globales. Nous verrons plus tard comment supporter les variables locales. Lorsque la fonction main appelle la procédure init_g() ou la procédure increase, il y a plusieurs opérations qui doivent être effectuées. Tout d'abord, le processeur doit transférer l'exécution du code à la première instruction de la procédure appelée. Cela se fait en associant une étiquette à chaque procédure qui correspond à l'adresse de la première instruction de cette procédure en mémoire. Une instruction de saut telle que jmp pourrait permettre de démarrer l'exécution de la procédure. Malheureusement, ce n'est pas suffisant car après son exécution la procédure doit pouvoir poursuivre son exécution à l'adresse de l'instruction qui suit celle d'où elle a été appelée. Pour cela, il est nécessaire que la procédure qui a été appelée puisse connaître l'adresse de l'instruction qui doit être exécutée à la fin de son exécution. Dans l'architecture [IA32], cela se fait en utilisant la pile. Vu l'importance des appels de procédure et de fonctions, l'architecture [IA32] contient deux instructions dédiés pour implémenter ces appels. L'instruction call est une instruction de saut qui (1) sauvegarde sur la pile l'adresse de l'instruction qui suit l'instruction call puis (2) transfère l'exécution à l'adresse de l'étiquette passée en argument. L'adresse sauvée sur la pile est est l'adresse à laquelle la procédure doit revenir après son exécution. L'instruction call est donc équivalente à une instruction push suivie d'une instruction jmp. L'instruction ret est également une instruction de saut. Elle suppose que l'adresse de retour se trouve au sommet de la pile, retire cette adresse de la pile et effectue un saut à cette adresse. Elle est donc équivalente à une instruction pop suivie d'une instruction jmp. Dans l'architecture [IA32], le registre %esp contient en permanence le sommet de la pile. Les instructions call et ret modifient donc la valeur de ce registre lorsqu'elles sont exécutées. En assembleur, le programme ci-dessus se traduit comme suit :
increase: ; étiquette de la première instruction
movl g, %eax
addl h, %eax
movl %eax, g
ret ; retour à l'endroit qui suit l'appel
init_g: ; étiquette de la première instruction
movl $1252, g
ret ; retour à l'endroit qui suit l'appel
main:
subl $12, %esp
movl 20(%esp), %eax
movl 16(%esp), %ecx
movl $0, 8(%esp)
movl %ecx, 4(%esp)
movl %eax, (%esp)
calll init_g ; appel à la procédure init_g
A_init_g: calll increase ; appel à la procédure increase
A_increase: movl $0, %eax
addl $12, %esp
ret ; fin de la fonction main
g: ; étiquette, variable globale g
.long 0 ; initialisée à 0
h: ; étiquette, variable globale g
.long 2 ; initialisée à 2
Dans ce code assembleur, on retrouve dans le bas du code la déclaration des deux variables globales, g et h et leurs valeurs initiales. Chaque procédure a son étiquette qui correspond à l'adresse de sa première instruction. La fonction main débute par une manipulation de la pile qui ne nous intéresse pas pour le moment. L'appel à la procédure init_g() se fait via l'instruction calll init_g qui place sur la pile l'adresse de l'étiquette A_init_g. La procédure init_g() est très simple puisqu'elle comporte une instruction movl qui permet d'initialiser la variable g suivie d'une instruction ret. Celle-ci retire de la pile l'adresse A_init_g qui y avait été placée par l'instruction call et poursuit l'exécution du programme à cette adresse. L'appel à la procédure increase se déroule de façon similaire.
Considérons une petite variante de notre programme C dans lequel une procédure p appelle une procédure q.
int g=0;
int h=2;
void q() {
g=1252;
}
void p() {
q();
g=g+h;
}
int main(int argc, char *argv[]) {
p();
return(EXIT_SUCCESS);
}
La compilation de ce programme produit le code assembleur suivant pour les procédures p et q.
q:
movl $1252, g
ret ; retour à l'appelant
p:
subl $12, %esp ; réservation d'espace sur pile
calll q ; appel à la procédure q
movl g, %eax
addl h, %eax
movl %eax, g
addl $12, %esp ; libération espace réservé sur pile
ret ; retour à l'appelant
La seule différence par rapport au programme précédent est que la procédure p descend le sommet de la pile de 12 unités au début de son exécution et l'augmente de 12 unités à la fin. Ces manipulations sont nécessaires pour respecter une convention de l'architecture [IA32] qui veut que les adresses de retour des procédures soient alignées sur des blocs de 16 bytes.
Considérons maintenant une procédure qui prend un argument. Pour qu'une telle procédure puisse utiliser un argument, il faut que la procédure appelante puisse placer sa valeur à un endroit où la procédure appelée peut facilement y accéder. Dans l'architecture [IA32], c'est la pile qui joue ce rôle et permet le passage des arguments. En C, les arguments sont passés par valeur et ce sera donc les valeurs des arguments qui seront placées sur la pile. A titre d'exemple, considérons une procédure simple qui prend deux arguments entiers.
int g=0;
int h=2;
void init(int i, int j) {
g=i;
h=j;
}
int main(int argc, char *argv[]) {
init(1252,1);
return(EXIT_SUCCESS);
}
Le passage des arguments de la fonction init depuis la fonction main se fait en les plaçant sur la pile avec les instructions movl $1252, (%esp) et movl $1, 4(%esp) qui précèdent l'instruction call init. Le premier argument est placé au sommet de la pile et le second juste au-dessus. La fonction main sauvegarde d'autres registres sur la pile avant l'appel à init. Ces sauvegardes sont nécessaires car la fonction main ne sait pas quels registres seront modifiés par la fonction qu'elle appelle. En pratique l'architecture [IA32] définit des conventions d'utilisation des registres. Les registres %eax, %edx et %ecx sont des registres qui sont sous la responsabilité de la procédure appellante (dans ce cas main). Une procédure appelée (dans ce cas-ci init) peut modifier sans restrictions les valeurs de ces registres. Si la fonction appellante souhaite pouvoir utiliser les valeurs stockées dans ces registres après l'appel à la procédure, elle doit les sauvegarder elle-même sur la pile. C'est ce que fait la fonction main pour %eax, %edx et %ecx. Inversement, les registres %ebx, %edi et %esi sont des registres qui doivent être sauvés par la procédure appelée si celle-ci les modifie. La procédure init n'utilisant pas ces registres, elle ne les sauvegarde pas. Par contre, la fonction main débute en sauvegardant le registre %esi sur la pile.
init:
subl $8, %esp ; réservation d'espace sur la pile
movl 16(%esp), %eax ; récupération du second argument
movl 12(%esp), %ecx ; récupération du premier argument
movl %ecx, 4(%esp) ; sauvegarde sur la pile
movl %eax, (%esp) ; sauvegarde sur la pile
movl 4(%esp), %eax ; chargement de i
movl %eax, g ; g=i
movl (%esp), %eax ; chargement de j
movl %eax, h ; h=j
addl $8, %esp ; libération de l'espace réservé
ret
main:
pushl %esi
subl $40, %esp
movl 52(%esp), %eax
movl 48(%esp), %ecx
movl $1252, %edx
movl $1, %esi
movl $0, 36(%esp)
movl %ecx, 32(%esp)
movl %eax, 24(%esp)
movl $1252, (%esp) ; premier argument sur la pile
movl $1, 4(%esp) ; deuxième argument sur la pile
movl %esi, 20(%esp)
movl %edx, 16(%esp)
calll init ; appel à init
movl $0, %eax
addl $40, %esp
popl %esi
ret
La différence entre une procédure et une fonction est qu'une fonction retourne un résultat. Considérons le programme suivant et les fonctions triviales int init() et int sum(int, int). Pour que de telles fonctions puissent s'exécuter et retourner un résultat, il faut que la procédure appelante puisse savoir où aller chercher le résultat après exécution de l'instruction ret.
int g=0;
int h=2;
int init() {
return 1252;
}
int sum(int a, int b) {
return a+b;
}
int main(int argc, char *argv[]) {
g=init();
h=sum(1,2);
return(EXIT_SUCCESS);
}
La compilation du programme C ci-dessus en assembleur produit le code suivant. Dans l'architecture [IA32], la valeur de retour d'une fonction est stockée par convention dans le registre %eax. Cette convention est particulièrement visible lorsque l'on regarde les instructions générées pour la fonction int init(). La fonction sum retourne également son résultat dans le registre %eax.
init:
movl $1252, %eax
ret
sum:
subl $8, %esp ; réservation d'espace sur la pile
movl 16(%esp), %eax ; récupération du second argument
movl 12(%esp), %ecx ; récupération du premier argument
movl %ecx, 4(%esp)
movl %eax, (%esp)
movl 4(%esp), %eax ; %eax=a
addl (%esp), %eax ; %eax=a+b
addl $8, %esp ; libération de l'espace réservé
ret
main:
subl $28, %esp
movl 36(%esp), %eax
movl 32(%esp), %ecx
movl $0, 24(%esp)
movl %ecx, 20(%esp) ; sauvegarde sur la pile
movl %eax, 16(%esp) ; sauvegarde sur la pile
calll init
movl $1, %ecx
movl $2, %edx
movl %eax, g
movl $1, (%esp) ; premier argument
movl $2, 4(%esp) ; second argument
movl %ecx, 12(%esp) ; sauvegarde sur la pile
movl %edx, 8(%esp) ; sauvegarde sur la pile
calll sum
movl $0, %ecx
movl %eax, h
movl %ecx, %eax
addl $28, %esp
ret
Pour terminer notre exploration de la compilation de fonctions C en assembleur, considérons une fonction récursive. Par simplicité, nous utilisons la fonction sumn qui calcule de façon récursive la somme des n premiers entiers.
int sumn(int n) {
if(n<=1)
return n;
else
return n+sumn(n-1);
}
Lorsque cette fonction récursive est compilée, on obtient le code ci-dessous. Celui-ci démarre par réserver une zone de 28 bytes sur la pile et récupère ensuite l'argument qui est placé dans le registre %eax. Cet argument est utilisé comme variable locale, il est donc sauvegardé sur la pile de la fonction sumn dans la zone qui vient d'être réservée. Ensuite, on compare la valeur de l'argument avec 1. Si l'argument est inférieur ou égal à 1, on récupère la variable locale sur la pile et on la sauve à un autre endroit en préparation à la fin du code (étiquette .LBB1_3) ou elle sera placée dans le registre %eax avant l'exécution de l'instruction ret. Sinon, l'appel récursif est effectué. Pour cela, il faut d'abord calculer n-1. Cette valeur est stockée dans le registre %ecx puis placée sur la pile avant l'appel récursif. Comme un appel de fonction ne préserve pas %eax et que cette valeur est nécessaire après l'appel récursif, elle est sauvegardée sur la pile. La première instruction qui suit l'exécution de l'appel récursif récupère la valeur de la variable n sur la pile et la place dans le registre %ecx. Le résultat de l'appel récursif étant placé dans %eax, l'instruction addl %ecx, %eax calcule bien n+sum(n-1). Ce résultat est placé sur la pile puis récupéré et placé dans %eax avant l'exécution de ret. Il faut noter que les 28 bytes qui avaient étés ajoutés à la pile au début de la fonction sont retirées par l'instruction addl $28, %esp. C'est nécessaire pour que la pile soit bien préservée lors de l'appel à une fonction.
sumn:
subl $28, %esp ; réservation d'espace sur la pile
movl 32(%esp), %eax ; récupération argument
movl %eax, 20(%esp) ; sauvegarde sur pile
cmpl $1, 20(%esp)
jg .LBB1_2 ; jump si n>1
movl 20(%esp), %eax ; récupération n
movl %eax, 24(%esp)
jmp .LBB1_3
.LBB1_2:
movl 20(%esp), %eax
movl 20(%esp), %ecx
subl $1, %ecx ; %ecx=n-1
movl %ecx, (%esp) ; argument sur pile
movl %eax, 16(%esp)
recursion:
calll sumn
movl 16(%esp), %ecx ; récupération de n
addl %ecx, %eax ; %eax=%eax+n
movl %eax, 24(%esp)
.LBB1_3:
movl 24(%esp), %eax
addl $28, %esp ; libération de l'espace réservé sur la pile
ret
Ce code illustre la complexité de supporter des appels récursifs en C et le coût au niveau de la gestion de la pile notamment. Ces appels récursifs doivent être réservés à des fonctions où l'appel récursif apporte une plus value claire.
Footnotes
| [1] | Pour une liste détaillée des processeurs de cette famille produits par intel, voir notamment http://www.intel.com/pressroom/kits/quickreffam.htm D'autres fabricants produisent également des processeurs compatibles avec l'architecture [IA32]. |
| [2] | On parle de famille d'instructions car il existe de nombreuses instructions de déplacement en mémoire. Les plus simples sont suffixées par un caractère qui indique le type de données transféré. Ainsi, movb permet le transfert d'un byte tandis que movl permet le transfert d'un mot de 32 bits. Des détails sur ces instructions peuvent être obtenus dans [IA32] |
| [3] | Cette traduction et la plupart des traductions utilisées dans ce chapitre ont été obtenues en utilisant l'interface web de démo du compilateur llvm qui a été configuré pour générer du code 32 bits sans optimisation. Quelques détails ont été supprimés du code assembleur pour le rendre plus compact. |