Utilisation de plusieurs threads¶
Les performances des microprocesseurs se sont continuellement améliorées depuis les années 1960s. Cette amélioration a été possible grâce aux progrès constants de la micro-électronique qui a permis d'assembler des microprocesseurs contenant de plus en plus de transistors sur une surface de plus en plus réduite. La figure [1] ci-dessous illustre bien cette évolution puisqu'elle représente le nombre de transistors par microprocesseur en fonction du temps.
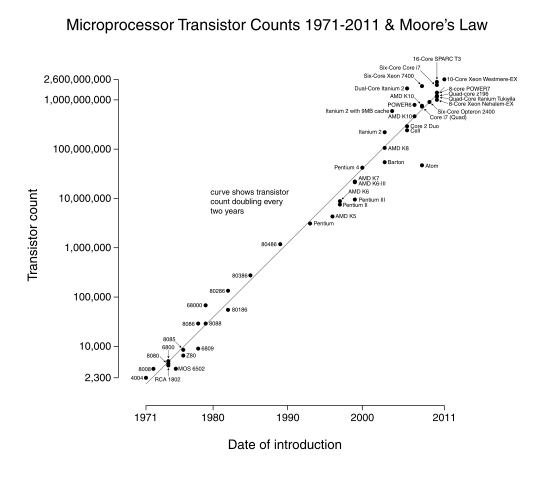
Evolution du nombre de transistors par microprocesseur
Cette évolution avait été prédite par Gordon Moore dans les années 1960s [Stokes2008]. Il a formulé en 1965 une hypothèse qui prédisait que le nombre de composants par puce continuerait à doubler tous les douze mois pour la prochaine décennie. Cette prédiction s'est avérée tout à fait réaliste. Elle est maintenant connue sous le nom de Loi de Moore et est fréquemment utilisée pour expliquer les améliorations de performance des ordinateurs.
Le fonctionnement d'un microprocesseur est régulé par une horloge. Celle-ci rythme la plupart des opérations du processeur et notamment le chargement des instructions depuis la mémoire. Pendant de nombreuses années, les performances des microprocesseurs ont fortement dépendu de leur vitesse d'horloge. Les premiers microprocesseurs avaient des fréquences d'horloge de quelques centaines de kHz. A titre d'exemple, le processeur intel 4004 avait une horloge à 740 kHz en 1971. Aujourd'hui, les processeurs rapides dépassent la fréquence de 3 GHz. La figure ci-dessous présente l'évolution de la fréquence d'horloge des microprocesseurs depuis les années 1970s [2]. On remarque une évolution rapide jusqu'aux environs du milieu de la dernière décennie. La barrière des 10 MHz a été franchie à la fin des années 1970s. Les 100 MHz ont étés atteints en 1994 et le GHz aux environs de l'an 2000.
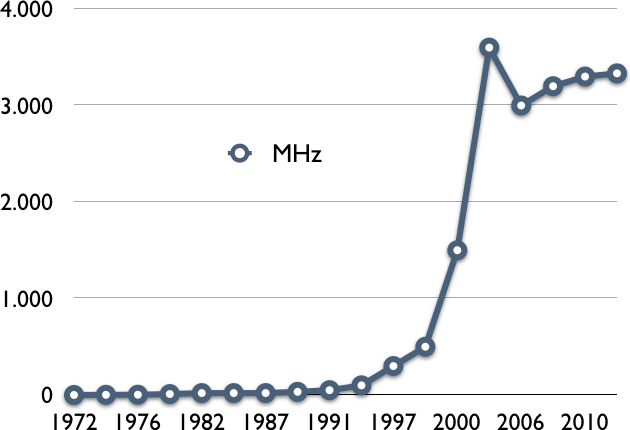
Evolution de la vitesse d'horloge des microprocesseurs
Pendant près de quarante ans, l'évolution technologique a permis une amélioration continue des performances des microprocesseurs. Cette amélioration a directement profité aux applications informatiques car elles ont pu s'exécuter plus rapidement au fur et à mesure que la vitesse d'horloge des microprocesseurs augmentait.
Malheureusement, vers 2005 cette croissance continue s'est arrêtée. La barrière des 3 GHz s'est avérée être une barrière très difficile à franchir d'un point de vue technologique. Aujourd'hui, les fabricants de microprocesseurs n'envisagent plus de chercher à continuer à augmenter les fréquences d'horloge des microprocesseurs.
Si pendant longtemps la fréquence d'horloge d'un microprocesseur a été une bonne heuristique pour prédire les performances du microprocesseur, ce n'est pas un indicateur parfait de performance. Certains processeurs exécutent une instruction durant chaque cycle d'horloge. D'autres processeurs prennent quelques cycles d'horloge pour exécuter chaque instruction et enfin certains processeurs sont capables d'exécuter plusieurs instructions durant chaque cycle d'horloge.
Une autre façon de mesurer les performances d'un microprocesseur est de comptabiliser le nombre d'instructions qu'il exécute par seconde. On parle en général de Millions d'Instructions par Seconde (ou MIPS). Si les premiers microprocesseurs effectuaient moins de 100.000 instructions par seconde, la barrière du MIPS a été franchie en 1979. Mesurées en MIPS, les performances des microprocesseurs ont continué à augmenter durant les dernières années malgré la barrière des 3 GHz comme le montre la figure ci-dessous.
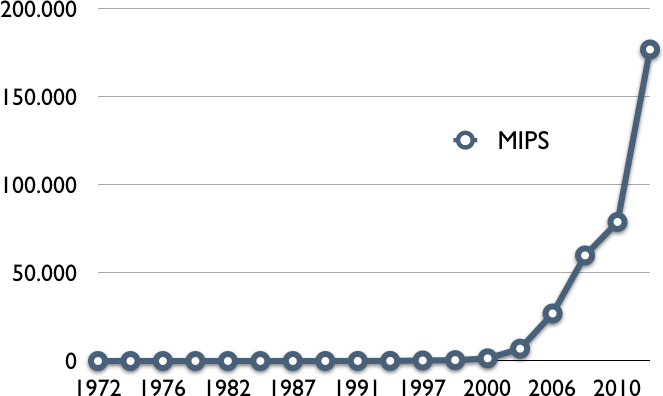
Evolution des performances des microprocesseurs en MIPS
Note
Evaluation des performances de systèmes informatiques
La fréquence d'horloge d'un processeur et le nombre d'instructions qu'il est capable d'exécuter chaque seconde ne sont que quelques uns des paramètres qui influencent les performances d'un système informatique qui intègre ce processeur. Les performances globales d'un système informatique dépendent de nombreux autres facteurs comme la capacité de mémoire et ses performances, la vitesse des bus entre les différents composants, les performances des dispositifs de stockage ou des cartes réseaux. Les performances d'un système dépendront aussi fortement du type d'application utilisé. Un serveur web, un serveur de calcul scientifique et un serveur de bases de données n'auront pas les mêmes contraintes en termes de performance. L'évaluation complète des performances d'un système informatique se fait généralement en utilisant des benchmarks. Un benchmark est un ensemble de logiciels qui reproduisent le comportement de certaines classes d'applications de façon à pouvoir tester les performances de systèmes informatiques de façon reproductible. Différents organismes publient de tels benchmarks. Le plus connu est probablement Standard Performance Evaluation Corporation qui publie des benchmarks et des résultats de benchmarks pour différents types de systèmes informatiques et d'applications.
Cette progression continue des performances en MIPS a été possible grâce à l'introduction de processeurs qui sont capables d'exécuter plusieurs threads d'exécution simultanément. On parle alors de processeur multi-coeurs ou multi-threadé.
La notion de thread d'exécution est très importante dans un système informatique. Elle permet non seulement de comprendre comme un ordinateur équipé d'un seul microprocesseur peut exécuter plusieurs programmes simultanément, mais aussi comment des programmes peuvent profiter des nouveaux processeurs capables d'exécuter plusieurs threads simultanément.
.. Pour comprendre cette notion, il est intéressant de revenir à nouveau sur l'exécution d'une fonction en langage assembleur.
Considérons la fonction f :
int f(int a, int b ) { int m=0; int c=0; while(c<b) { m+=a; c=c+1; } return m; }
Pour qu'un processeur puisse exécuter cette séquence d'instructions, il faut qu'il puisse accéder :
à la mémoire contenant les instructions à exécuter
à la mémoire contenant les données manipulées par cette séquence d'instruction. Pour rappel, cette mémoire est divisée en plusieurs parties :
- la zone contenant les variables globales
- le tas
- la pile
aux registres, des zones de mémoire très rapide (mais peu nombreuses) se trouvant sur le processeur qui permettent de stocker entre autres : l'adresse de l'instruction à exécuter, des résultats intermédiaires obtenus durant l'exécution d'un instruction ou encore des informations sur la pile.
Un processeur multithreadé a la capacité d'exécuter plusieurs programmes simultanément. En pratique, ce processeur disposera de plusieurs copies des registres. Chacun de ces blocs de registres pourra être utilisé pour exécuter ces programmes simultanément à raison d'un thread d'exécution par bloc de registres. Chaque thread d'exécution va correspondre à une séquence différente d'instructions qui va modifier son propre bloc de registres. C'est grâce à cette capacité d'exécuter plusieurs threads d'exécution simultanément que les performances en MIPS des microprocesseurs ont pu continuer à croître alors que leur fréquence d'horloge stagnait.
Cette capacité d'exécuter plusieurs threads d'exécution simultanément n'est pas limitée à un thread d'exécution par programme. Sachant qu'un thread d'exécution n'est finalement qu'une séquence d'instructions qui utilisent un bloc de registres, il est tout à fait possible à plusieurs séquences d'exécution appartenant à un même programme de s'exécuter simultanément. Si on revient à la fonction assembleur ci-dessus, il est tout à fait possible que deux invocations de cette fonction s'exécutent simultanément sur un microprocesseur. Pour démarrer une telle instance, il suffit de pouvoir initialiser le bloc de registres nécessaire à la nouvelle instance et ensuite de démarrer l'exécution à la première instruction de la fonction. En pratique, cela nécessite la coopération du système d'exploitation. Différents mécanismes ont été proposés pour permettre à un programme de lancer différents threads d'exécution. Aujourd'hui, le plus courant est connu sous le nom de threads POSIX. C'est celui que nous allons étudier en détail, mais il en existe d'autres.
Note
D'autres types de threads
A côté des threads POSIX, il existe d'autres types de threads. [Gove2011] présente comment implémenter des threads sur différents systèmes d'exploitation. Sous Linux, NTPL [DrepperMolnar2005] et LinuxThreads [Leroy] sont deux anciennes implémentations des threads POSIX. GNU PTH [GNUPTH] est une librairie qui implémente les threads sans interaction directe avec le système d'exploitation. Cela permet à la librairie d'être portable sur de nombreux systèmes d'exploitation. Malheureusement, tous les threads GNU PTH d'un programme doivent s'exécuter sur le même processeur.
Les threads POSIX¶
Les threads POSIX sont supportés par la plupart des variantes de Unix. Ils sont souvent implémentés à l'intérieur d'une librairie. Sous Linux, il s'agit de la librairie pthreads(7) qui doit être explicitement compilée avec le paramètre -lpthread lorsque l'on utilise gcc(1).
La librairie threads POSIX contient de nombreuses fonctions qui permettent de décomposer un programme en plusieurs threads d'exécution et de les gérer. Toutes ces fonctions nécessitent l'inclusion du fichier pthread.h. La première fonction importante est pthread_create(3) qui permet de créer un nouveau thread d'exécution. Cette fonction prend quatre arguments et retourne une valeur entière.
#include <pthread.h>
int
pthread_create(pthread_t *restrict thread,
const pthread_attr_t *restrict attr,
void *(*start_routine)(void *),
void *restrict arg);
Le premier argument est un pointeur vers une structure de type pthread_t. Cette structure est définie dans pthread.h et contient toutes les informations nécessaires à l'exécution d'un thread. Chaque thread doit disposer de sa structure de données de type pthread_t qui lui est propre.
Le second argument permet de spécifier des attributs spécifiques au thread qui est créé. Ces attributs permettent de configurer différents paramètres associés à un thread. Nous y reviendrons ultérieurement. Si cet argument est mis à NULL, la librairie pthreads utilisera les attributs par défaut qui sont en général largement suffisants.
Le troisième argument contient l'adresse de la fonction par laquelle le nouveau thread va démarrer son exécution. Cette adresse est le point de départ de l'exécution du thread et peut être comparée à la fonction main qui est lancée par le système d'exploitation lorsqu'un programme est exécuté. Un thread doit toujours débuter son exécution par une fonction dont la signature est void * function(void *), c'est-à-dire une fonction qui prend comme argument un pointeur générique (de type void *) et retourne un résultat du même type.
Le quatrième argument est l'argument qui est passé à la fonction qui débute le thread qui vient d'être créé. Cet argument est un pointeur générique de type void *, mais la fonction peut bien entendu le convertir dans un autre type.
La fonction pthread_create(3) retourne un résultat entier. Une valeur de retour non-nulle indique une erreur et errno est mise à jour.
Un thread s'exécute en général pendant une certaine période de temps puis il peut retourner un résultat au thread d'exécution principal. Un thread peut retourner son résultat (de type void *) de deux façons au thread qui l'a lancé. Tout d'abord, un thread qui a démarré par la fonction f se termine lorsque cette fonction exécute return(...). L'autre façon de terminer un thread d'exécution est d'appeler explicitement la fonction pthread_exit(3). Celle-ci prend un argument de type void * et le retourne au thread qui l'avait lancé.
Pour récupérer le résultat d'un thread d'exécution, le thread principal doit utiliser la fonction pthread_join(3). Celle-ci prend deux arguments et retourne un entier.
#include <pthread.h>
int
pthread_join(pthread_t thread, void **value_ptr);
Le premier argument de pthread_join(3) est la structure pthread_t correspondant au thread dont le résultat est attendu. Le second argument est un pointeur vers un pointeur générique (void **) qui après la terminaison du thread passé comme premier argument pointera vers la valeur de retour de ce thread.
L'exemple ci-dessous illustre une utilisation simple des fonctions pthread_create(3), pthread_join(3) et pthread_exit(3).
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
int global=0;
void error(int err, char *msg) {
fprintf(stderr,"%s a retourné %d, message d'erreur : %s\n",msg,err,strerror(errno));
exit(EXIT_FAILURE);
}
void *thread_first(void * param) {
global++;
return(NULL);
}
void *thread_second(void * param) {
global++;
pthread_exit(NULL);
}
int main (int argc, char *argv[]) {
pthread_t first;
pthread_t second;
int err;
err=pthread_create(&first,NULL,&thread_first,NULL);
if(err!=0)
error(err,"pthread_create");
err=pthread_create(&second,NULL,&thread_second,NULL);
if(err!=0)
error(err,"pthread_create");
for(int i=0; i<1000000000;i++) { /*...*/ }
err=pthread_join(second,NULL);
if(err!=0)
error(err,"pthread_join");
err=pthread_join(first,NULL);
if(err!=0)
error(err,"pthread_join");
printf("global: %d\n",global);
return(EXIT_SUCCESS);
}
Dans ce programme, la fonction main lance deux threads. Le premier exécute la fonction thread_first et le second la fonction thread_second. Ces deux fonctions incrémentent une variable globale et n'utilisent pas leur argument. thread_first se termine par return tandis que thread_second se termine par un appel à pthread_exit(3). Après avoir créé ses deux threads, la fonction main démarre une longue boucle puis appelle pthread_join pour attendre la fin des deux threads qu'elle avait lancé.
Afin d'illustrer la possibilité de passer des arguments à un thread et d'en récupérer la valeur de retour, considérons l'exemple ci-dessous.
#define NTHREADS 4
void *neg (void * param) {
int *l;
l=(int *) param;
int *r=(int *)malloc(sizeof(int));
*r=-*l;
return ((void *) r);
}
int main (int argc, char *argv[]) {
pthread_t threads[NTHREADS];
int arg[NTHREADS];
int err;
for(long i=0;i<NTHREADS;i++) {
arg[i]=i;
err=pthread_create(&(threads[i]),NULL,&neg,(void *) &(arg[i]));
if(err!=0)
error(err,"pthread_create");
}
for(int i=0;i<NTHREADS;i++) {
int *r;
err=pthread_join(threads[i],(void **)&r);
printf("Resultat[%d]=%d\n",i,*r);
free(r);
if(err!=0)
error(err,"pthread_join");
}
return(EXIT_SUCCESS);
}
Ce programme lance 4 threads d'exécution en plus du thread principal. Chaque thread d'exécution exécute la fonction neg qui récupère un entier comme argument et retourne l'opposé de cet entier comme résultat.
Lors d'un appel à pthread_create(3), il est important de se rappeler que cette fonction crée le thread d'exécution, mais que ce thread ne s'exécute pas nécessairement immédiatement. En effet, il est très possible que le système d'exploitation ne puisse pas activer directement le nouveau thread d'exécution, par exemple parce que l'ensemble des processeurs de la machine sont actuellement utilisés. Dans ce cas, le thread d'exécution est mis en veille par le système d'exploitation et il sera démarré plus tard. Sachant que le thread peut devoir démarrer plus tard, il est important de s'assurer que la fonction lancée par pthread_create(3) aura bien accès à son argument au moment où finalement elle démarrera. Dans l'exemple ci-dessous, cela se fait en passant comme quatrième argument l'adresse d'un entier casté en void *. Cette valeur est copiée sur la pile de la fonction neg. Celle-ci pourra accéder à cet entier via ce pointeur sans problème lorsqu'elle démarrera.
Note
Un thread doit pouvoir accéder à son argument
Lorsque l'on démarre un thread via la fonction pthread_create(3), il faut s'assurer que la fonction lancée pourra bien accéder à ses arguments. Ce n'est pas toujours le cas comme le montre l'exemple ci-dessous. Dans cet exemple, c'est l'adresse de la variable locale i qui est passée comme quatrième argument à la fonction pthread_create(3). Cette adresse sera copiée sur la pile de la fonction neg pour chacun des threads créés. Malheureusement, lorsque la fonction neg sera exécutée, elle trouvera sur sa pile l'adresse d'une variable qui risque fort d'avoir été modifiée après l'appel à pthread_create(3) ou pire risque d'avoir disparu car la boucle for s'est terminée. Il est très important de bien veiller à ce que le quatrième argument passé à pthread_create(3) existe toujours au moment de l'exécution effective de la fonction qui démarre le thread lancé.
/// erroné ! for(long i=0;i<NTHREADS;i++) { err=pthread_create(&(threads[i]),NULL,&neg,(void *)&i); if(err!=0) error(err,"pthread_create"); }
Concernant pthread_join(3), le code ci-dessus illustre la récupération du résultat via un pointeur vers un entier. Comme la fonction neg retourne un résultat de type void * elle doit nécessairement retourner un pointeur qui peut être casté vers un pointeur de type void *. C'est ce que la fonction neg dans l'exemple réalise. Elle alloue une zone mémoire permettant de stocker un entier et place dans cette zone mémoire la valeur de retour de la fonction. Ce pointeur est ensuite casté en un pointeur de type void * avant d'appeler return. Il faut noter que l'appel à pthread_join(3) ne se termine que lorsque le thread spécifié comme premier argument se termine. Si ce thread ne se termine pas pour n'importe quelle raison, l'appel à pthread_join(3) ne se terminera pas non plus.
Footnotes
| [1] | Source : https://en.wikipedia.org/wiki/File:Transistor_Count_and_Moore%27s_Law_-_2011.svg |
{kind=link}
| [2] | Plusieurs sites web recensent cette information, notamment https://www.intel.com/pressroom/kits/quickreffam.htm, https://en.wikipedia.org/wiki/List_of_Intel_microprocessors et https://en.wikipedia.org/wiki/Instructions_per_second |