The datalink layer and the Local Area Networks¶
The datalink layer is the lowest layer of the reference model that we discuss in detail. As mentioned previously, there are two types of datalink layers. The first datalink layers that appeared are the ones that are used on point-to-point links between devices that are directly connected by a physical link. We will briefly discuss one of these datalink layers in this chapter. The second type of datalink layers are the ones used in Local Area Networks (LANs). The main difference between the point-to-point and the LAN datalink layers is that the latter need to regulate the access to the Local Area Network which is usually a shared medium.
This chapter is organised as follows. We first discuss the principles of the datalink layer as well as the services that it uses from the physical layer. We then describe in more detail several Medium Access Control algorithms that are used in Local Area Networks to regulate the access to the shared medium. Finally we discuss in detail important datalink layer technologies with an emphasis on Ethernet and WiFi networks.
Principles¶
The datalink layer uses the service provided by the physical layer. Although there are many different implementations of the physical layer from a technological perspective, they all provide a service that enables the datalink layer to send and receive bits between directly connected devices. The datalink layer receives packets from the network layer. Two datalink layer entities exchange frames. As explained in the previous chapter, most datalink layer technologies impose limitations on the size of the frames. Some technologies only impose a maximum frame size, others enforce both minimum and maximum frames sizes and finally some technologies only support a single frame size. In the latter case, the datalink layer will usually include an adaptation sublayer to allow the network layer to send and receive variable-length packets. This adaptation layer may include fragmentation and reassembly mechanisms.

The datalink layer and the reference model
The physical layer service facilitates the sending and receiving of bits. Furthermore, it is usually far from perfect as explained in the introduction :
- the Physical layer may change, e.g. due to electromagnetic interferences, the value of a bit being transmitted
- the Physical layer may deliver more bits to the receiver than the bits sent by the sender
- the Physical layer may deliver fewer bits to the receiver than the bits sent by the sender
The datalink layer must allow endsystems to exchange frames containing packets despite all of these limitations. On point-to-point links and Local Area Networks, the first problem to be solved is how to encode a frame as a sequence of bits, so that the receiver can easily recover the received frame despite the limitations of the physical layer.
If the physical layer were perfect, the problem would be very simple. The datalink layer would simply need to define how to encode each frame as a sequence of consecutive bits. The receiver would then easily be able to extract the frames from the received bits. Unfortunately, the imperfections of the physical layer make this framing problem slightly more complex. Several solutions have been proposed and are used in practice in different datalink layer technologies.
Framing¶
This is the framing problem. It can be defined as : “How does a sender encode frames so that the receiver can efficiently extract them from the stream of bits that it receives from the physical layer”.
A first solution to solve the framing problem is to require the physical layer to remain idle for some time after the transmission of each frame. These idle periods can be detected by the receiver and serve as a marker to delineate frame boundaries. Unfortunately, this solution is not sufficient for two reasons. First, some physical layers cannot remain idle and always need to transmit bits. Second, inserting an idle period between frames decreases the maximum bandwidth that can be achieved by the datalink layer.
Some physical layers provide an alternative to this idle period. All physical layers are able to send and receive physical symbols that represent values 0 and 1. However, for various reasons that are outside the scope of this chapter, several physical layers are able to exchange other physical symbols as well. For example, the Manchester encoding used in several physical layers can send four different symbols. The Manchester encoding is a differential encoding scheme in which time is divided into fixed-length periods. Each period is divided in two halves and two different voltage levels can be applied. To send a symbol, the sender must set one of these two voltage levels during each half period. To send a 1 (resp. 0), the sender must set a high (resp. low) voltage during the first half of the period and a low (resp. high) voltage during the second half. This encoding ensures that there will be a transition at the middle of each period and allows the receiver to synchronise its clock to the sender’s clock. Apart from the encodings for 0 and 1, the Manchester encoding also supports two additional symbols : InvH and InvB where the same voltage level is used for the two half periods. By definition, these two symbols cannot appear inside a frame which is only composed of 0 and 1. Some technologies use these special symbols as markers for the beginning or end of frames.

Manchester encoding
Unfortunately, multi-symbol encodings cannot be used by all physical layers and a generic solution which can be used with any physical layer that is able to transmit and receive only 0 and 1 is required. This generic solution is called stuffing and two variants exist : bit stuffing and character stuffing. To enable a receiver to easily delineate the frame boundaries, these two techniques reserve special bit strings as frame boundary markers and encode the frames so that these special bit strings do not appear inside the frames.
Bit stuffing reserves the 01111110 bit string as the frame boundary marker and ensures that there will never be six consecutive 1 symbols transmitted by the physical layer inside a frame. With bit stuffing, a frame is sent as follows. First, the sender transmits the marker, i.e. 01111110. Then, it sends all the bits of the frame and inserts an additional bit set to 0 after each sequence of five consecutive 1 bits. This ensures that the sent frame never contains a sequence of six consecutive bits set to 1. As a consequence, the marker pattern cannot appear inside the frame sent. The marker is also sent to mark the end of the frame. The receiver performs the opposite to decode a received frame. It first detects the beginning of the frame thanks to the 01111110 marker. Then, it processes the received bits and counts the number of consecutive bits set to 1. If a 0 follows five consecutive bits set to 1, this bit is removed since it was inserted by the sender. If a 1 follows five consecutive bits sets to 1, it indicates a marker if it is followed by a bit set to 0. The table below illustrates the application of bit stuffing to some frames.
Original frame Transmitted frame 0001001001001001001000011 01111110000100100100100100100001101111110 0110111111111111111110010 01111110011011111011111011111011001001111110 01111110 0111111001111101001111110
For example, consider the transmission of 0110111111111111111110010. The sender will first send the 01111110 marker followed by 011011111. After these five consecutive bits set to 1, it inserts a bit set to 0 followed by 11111. A new 0 is inserted, followed by 11111. A new 0 is inserted followed by the end of the frame 110010 and the 01111110 marker.
Bit stuffing increases the number of bits required to transmit each frame. The worst case for bit stuffing is of course a long sequence of bits set to 1 inside the frame. If transmission errors occur, stuffed bits or markers can be in error. In these cases, the frame affected by the error and possibly the next frame will not be correctly decoded by the receiver, but it will be able to resynchronise itself at the next valid marker.
Bit stuffing can be easily implemented in hardware. However, implementing it in software is difficult given the higher overhead of bit manipulations in software. Software implementations prefer to process characters than bits, software-based datalink layers usually use character stuffing. This technique operates on frames that contain an integer number of 8-bit characters. Some characters are used as markers to delineate the frame boundaries. Many character stuffing techniques use the DLE, STX and ETX characters of the ASCII character set. DLE STX (resp. DLE ETX) is used to mark the beginning (end) of a frame. When transmitting a frame, the sender adds a DLE character after each transmitted DLE character. This ensures that none of the markers can appear inside the transmitted frame. The receiver detects the frame boundaries and removes the second DLE when it receives two consecutive DLE characters. For example, to transmit frame 1 2 3 DLE STX 4, a sender will first send DLE STX as a marker, followed by 1 2 3 DLE. Then, the sender transmits an additional DLE character followed by STX 4 and the DLE ETX marker.
Original frame Transmitted frame 1 2 3 4 DLE STX 1 2 3 4 DLE ETX 1 2 3 DLE STX 4 DLE STX 1 2 3 DLE DLE STX 4 DLE ETX DLE STX DLE ETX DLE STX DLE DLE STX DLE DLE ETX DLE ETX
Character stuffing , like bit stuffing, increases the length of the transmitted frames. For character stuffing, the worst frame is a frame containing many DLE characters. When transmission errors occur, the receiver may incorrectly decode one or two frames (e.g. if the errors occur in the markers). However, it will be able to resynchronise itself with the next correctly received markers.
Error detection¶
Besides framing, datalink layers also include mechanisms to detect and sometimes even recover from transmission error. To allow a receiver to detect transmission errors, a sender must add some redundant information as an error detection code to the frame sent. This error detection code is computed by the sender on the frame that it transmits. When the receiver receives a frame with an error detection code, it recomputes it and verifies whether the received error detection code matches the computer error detection code. If they match, the frame is considered to be valid. Many error detection schemes exist and entire books have been written on the subject. A detailed discussion of these techniques is outside the scope of this book, and we will only discuss some examples to illustrate the key principles.
To understand error detection codes, let us consider two devices that exchange bit strings containing N bits. To allow the receiver to detect a transmission error, the sender converts each string of N bits into a string of N+r bits. Usually, the r redundant bits are added at the beginning or the end of the transmitted bit string, but some techniques interleave redundant bits with the original bits. An error detection code can be defined as a function that computes the r redundant bits corresponding to each string of N bits. The simplest error detection code is the parity bit. There are two types of parity schemes : even and odd parity. With the even (resp. odd) parity scheme, the redundant bit is chosen so that an even (resp. odd) number of bits are set to 1 in the transmitted bit string of N+r bits. The receiver can easily recompute the parity of each received bit string and discard the strings with an invalid parity. The parity scheme is often used when 7-bit characters are exchanged. In this case, the eighth bit is often a parity bit. The table below shows the parity bits that are computed for bit strings containing three bits.
3 bits string Odd parity Even parity 000 1 0 001 0 1 010 0 1 100 0 1 111 0 1 110 1 0 101 1 0 011 1 0
The parity bit allows a receiver to detect transmission errors that have affected a single bit among the transmitted N+r bits. If there are two or more bits in error, the receiver may not necessarily be able to detect the transmission error. More powerful error detection schemes have been defined. The Cyclical Redundancy Checks (CRC) are widely used in datalink layer protocols. An N-bits CRC can detect all transmission errors affecting a burst of less than N bits in the transmitted frame and all transmission errors that affect an odd number of bits. Additional details about CRCs may be found in [Williams1993].
It is also possible to design a code that allows the receiver to correct transmission errors. The simplest error correction code is the triple modular redundancy (TMR). To transmit a bit set to 1 (resp. 0), the sender transmits 111 (resp. 000). When there are no transmission errors, the receiver can decode 111 as 1. If transmission errors have affected a single bit, the receiver performs majority voting as shown in the table below. This scheme allows the receiver to correct all transmission errors that affect a single bit.
Received bits Decoded bit 000 0 001 0 010 0 100 0 111 1 110 1 101 1 011 1
Other more powerful error correction codes have been proposed and are used in some applications. The Hamming Code is a clever combination of parity bits that provides error detection and correction capabilities.
In practice, datalink layer protocols combine bit stuffing or character stuffing with a length indication in the frame header and a checksum or CRC. The checksum/CRC is computed by the sender and placed in the frame before applying bit/character stuffing.
Medium Access Control¶
Point-to-point datalink layers need to select one of the framing techniques described above and optionally add retransmission algorithms such as those explained for the transport layer to provide a reliable service. Datalink layers for Local Area Networks face two additional problems. A LAN is composed of several hosts that are attached to the same shared physical medium. From a physical layer perspective, a LAN can be organised in four different ways :
- a bus-shaped network where all hosts are attached to the same physical cable
- a ring-shaped where all hosts are attached to an upstream and a downstream node so that the entire network forms a ring
- a star-shaped network where all hosts are attached to the same device
- a wireless network where all hosts can send and receive frames using radio signals
These four basic physical organisations of Local Area Networks are shown graphically in the figure below. We will first focus on one physical organisation at a time.

Bus, ring and star-shaped Local Area Network
The common problem among all of these network organisations is how to efficiently share the access to the Local Area Network. If two devices send a frame at the same time, the two electrical, optical or radio signals that correspond to these frames will appear at the same time on the transmission medium and a receiver will not be able to decode either frame. Such simultaneous transmissions are called collisions. A collision may involve frames transmitted by two or more devices attached to the Local Area Network. Collisions are the main cause of errors in wired Local Area Networks.
All Local Area Network technologies rely on a Medium Access Control algorithm to regulate the transmissions to either minimise or avoid collisions. There are two broad families of Medium Access Control algorithms :
- Deterministic or pessimistic MAC algorithms. These algorithms assume that collisions are a very severe problem and that they must be completely avoided. These algorithms ensure that at any time, at most one device is allowed to send a frame on the LAN. This is usually achieved by using a distributed protocol which elects one device that is allowed to transmit at each time. A deterministic MAC algorithm ensures that no collision will happen, but there is some overhead in regulating the transmission of all the devices attached to the LAN.
- Stochastic or optimistic MAC algorithms. These algorithms assume that collisions are part of the normal operation of a Local Area Network. They aim to minimise the number of collisions, but they do not try to avoid all collisions. Stochastic algorithms are usually easier to implement than deterministic ones.
We first discuss a simple deterministic MAC algorithm and then we describe several important optimistic algorithms, before coming back to a distributed and deterministic MAC algorithm.
Static allocation methods¶
A first solution to share the available resources among all the devices attached to one Local Area Network is to define, a priori, the distribution of the transmission resources among the different devices. If N devices need to share the transmission capacities of a LAN operating at b Mbps, each device could be allocated a bandwidth of 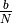 Mbps.
Mbps.
Limited resources need to be shared in other environments than Local Area Networks. Since the first radio transmissions by Marconi more than one century ago, many applications that exchange information through radio signals have been developed. Each radio signal is an electromagnetic wave whose power is centered around a given frequency. The radio spectrum corresponds to frequencies ranging between roughly 3 KHz and 300 GHz. Frequency allocation plans negotiated among governments reserve most frequency ranges for specific applications such as broadcast radio, broadcast television, mobile communications, aeronautical radio navigation, amateur radio, satellite, etc. Each frequency range is then subdivided into channels and each channel can be reserved for a given application, e.g. a radio broadcaster in a given region.
Frequency Division Multiplexing (FDM) is a static allocation scheme in which a frequency is allocated to each device attached to the shared medium. As each device uses a different transmission frequency, collisions cannot occur. In optical networks, a variant of FDM called Wavelength Division Multiplexing (WDM) can be used. An optical fiber can transport light at different wavelengths without interference. With WDM, a different wavelength is allocated to each of the devices that share the same optical fiber.
Time Division Multiplexing (TDM) is a static bandwidth allocation method that was initially defined for the telephone network. In the fixed telephone network, a voice conversation is usually transmitted as a 64 Kbps signal. Thus, a telephone conservation generates 8 KBytes per second or one byte every 125 microseconds. Telephone conversations often need to be multiplexed together on a single line. For example, in Europe, thirty 64 Kbps voice signals are multiplexed over a single 2 Mbps (E1) line. This is done by using Time Division Multiplexing (TDM). TDM divides the transmission opportunities into slots. In the telephone network, a slot corresponds to 125 microseconds. A position inside each slot is reserved for each voice signal. The figure below illustrates TDM on a link that is used to carry four voice conversations. The vertical lines represent the slot boundaries and the letters the different voice conversations. One byte from each voice conversation is sent during each 125 microseconds slot. The byte corresponding to a given conversation is always sent at the same position in each slot.

Time-division multiplexing
TDM as shown above can be completely static, i.e. the same conversations always share the link, or dynamic. In the latter case, the two endpoints of the link must exchange messages specifying which conversation uses which byte inside each slot. Thanks to these signalling messages, it is possible to dynamically add and remove voice conversations from a given link.
TDM and FDM are widely used in telephone networks to support fixed bandwidth conversations. Using them in Local Area Networks that support computers would probably be inefficient. Computers usually do not send information at a fixed rate. Instead, they often have an on-off behaviour. During the on period, the computer tries to send at the highest possible rate, e.g. to transfer a file. During the off period, which is often much longer than the on period, the computer does not transmit any packet. Using a static allocation scheme for computers attached to a LAN would lead to huge inefficiencies, as they would only be able to transmit at 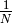 of the total bandwidth during their on period, despite the fact that the other computers are in their off period and thus do not need to transmit any information. The dynamic MAC algorithms discussed in the remainder of this chapter aim solve this problem.
of the total bandwidth during their on period, despite the fact that the other computers are in their off period and thus do not need to transmit any information. The dynamic MAC algorithms discussed in the remainder of this chapter aim solve this problem.
ALOHA¶
In the 1960s, computers were mainly mainframes with a few dozen terminals attached to them. These terminals were usually in the same building as the mainframe and were directly connected to it. In some cases, the terminals were installed in remote locations and connected through a modem attached to a dial-up line. The university of Hawaii chose a different organisation. Instead of using telephone lines to connect the distant terminals, they developed the first packet radio technology [Abramson1970]. Until then, computer networks were built on top of either the telephone network or physical cables. ALOHANet showed that it was possible to use radio signals to interconnect computers.
The first version of ALOHANet, described in [Abramson1970], operated as follows: First, the terminals and the mainframe exchanged fixed-length frames composed of 704 bits. Each frame contained 80 8-bit characters, some control bits and parity information to detect transmission errors. Two channels in the 400 MHz range were reserved for the operation of ALOHANet. The first channel was used by the mainframe to send frames to all terminals. The second channel was shared among all terminals to send frames to the mainframe. As all terminals share the same transmission channel, there is a risk of collision. To deal with this problem as well as transmission errors, the mainframe verified the parity bits of the received frame and sent an acknowledgement on its channel for each correctly received frame. The terminals on the other hand had to retransmit the unacknowledged frames. As for TCP, retransmitting these frames immediately upon expiration of a fixed timeout is not a good approach as several terminals may retransmit their frames at the same time leading to a network collapse. A better approach, but still far from perfect, is for each terminal to wait a random amount of time after the expiration of its retransmission timeout. This avoids synchronisation among multiple retransmitting terminals.
The pseudo-code below shows the operation of an ALOHANet terminal. We use this python syntax for all Medium Access Control algorithms described in this chapter. The algorithm is applied to each new frame that needs to be transmitted. It attempts to transmit a frame at most max times (while loop). Each transmission attempt is performed as follows: First, the frame is sent. Each frame is protected by a timeout. Then, the terminal waits for either a valid acknowledgement frame or the expiration of its timeout. If the terminal receives an acknowledgement, the frame has been delivered correctly and the algorithm terminates. Otherwise, the terminal waits for a random time and attempts to retransmit the frame.
# ALOHA
N=1
while N<= max :
send(frame)
wait(ack_on_return_channel or timeout)
if (ack_on_return_channel):
break # transmission was successful
else:
# timeout
wait(random_time)
N=N+1
else:
# Too many transmission attempts
[Abramson1970] analysed the performance of ALOHANet under particular assumptions and found that ALOHANet worked well when the channel was lightly loaded. In this case, the frames are rarely retransmitted and the channel traffic, i.e. the total number of (correct and retransmitted) frames transmitted per unit of time is close to the channel utilization, i.e. the number of correctly transmitted frames per unit of time. Unfortunately, the analysis also reveals that the channel utilization reaches its maximum at 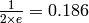 times the channel bandwidth. At higher utilization, ALOHANet becomes unstable and the network collapses due to collided retransmissions.
times the channel bandwidth. At higher utilization, ALOHANet becomes unstable and the network collapses due to collided retransmissions.
Note
Amateur packet radio
Packet radio technologies have evolved in various directions since the first experiments performed at the University of Hawaii. The Amateur packet radio service developed by amateur radio operators is one of the descendants ALOHANet. Many amateur radio operators are very interested in new technologies and they often spend countless hours developing new antennas or transceivers. When the first personal computers appeared, several amateur radio operators designed radio modems and their own datalink layer protocols [KPD1985] [BNT1997]. This network grew and it was possible to connect to servers in several European countries by only using packet radio relays. Some amateur radio operators also developed TCP/IP protocol stacks that were used over the packet radio service. Some parts of the amateur packet radio network are connected to the global Internet and use the 44.0.0.0/8 prefix.
Many improvements to ALOHANet have been proposed since the publication of [Abramson1970], and this technique, or some of its variants, are still found in wireless networks today. The slotted technique proposed in [Roberts1975] is important because it shows that a simple modification can significantly improve channel utilization. Instead of allowing all terminals to transmit at any time, [Roberts1975] proposed to divide time into slots and allow terminals to transmit only at the beginning of each slot. Each slot corresponds to the time required to transmit one fixed size frame. In practice, these slots can be imposed by a single clock that is received by all terminals. In ALOHANet, it could have been located on the central mainframe. The analysis in [Roberts1975] reveals that this simple modification improves the channel utilization by a factor of two.
Carrier Sense Multiple Access¶
ALOHA and slotted ALOHA can easily be implemented, but unfortunately, they can only be used in networks that are very lightly loaded. Designing a network for a very low utilisation is possible, but it clearly increases the cost of the network. To overcome the problems of ALOHA, many Medium Access Control mechanisms have been proposed which improve channel utilization. Carrier Sense Multiple Access (CSMA) is a significant improvement compared to ALOHA. CSMA requires all nodes to listen to the transmission channel to verify that it is free before transmitting a frame [KT1975]. When a node senses the channel to be busy, it defers its transmission until the channel becomes free again. The pseudo-code below provides a more detailed description of the operation of CSMA.
# persistent CSMA
N=1
while N<= max :
wait(channel_becomes_free)
send(frame)
wait(ack or timeout)
if ack :
break # transmission was successful
else :
# timeout
N=N+1
# end of while loop
# Too many transmission attempts
The above pseudo-code is often called persistent CSMA [KT1975] as the terminal will continuously listen to the channel and transmit its frame as soon as the channel becomes free. Another important variant of CSMA is the non-persistent CSMA [KT1975]. The main difference between persistent and non-persistent CSMA described in the pseudo-code below is that a non-persistent CSMA node does not continuously listen to the channel to determine when it becomes free. When a non-persistent CSMA terminal senses the transmission channel to be busy, it waits for a random time before sensing the channel again. This improves channel utilization compared to persistent CSMA. With persistent CSMA, when two terminals sense the channel to be busy, they will both transmit (and thus cause a collision) as soon as the channel becomes free. With non-persistent CSMA, this synchronisation does not occur, as the terminals wait a random time after having sensed the transmission channel. However, the higher channel utilization achieved by non-persistent CSMA comes at the expense of a slightly higher waiting time in the terminals when the network is lightly loaded.
# Non persistent CSMA
N=1
while N<= max :
listen(channel)
if free(channel):
send(frame)
wait(ack or timeout)
if received(ack) :
break # transmission was successful
else :
# timeout
N=N+1
else:
wait(random_time)
# end of while loop
# Too many transmission attempts
[KT1975] analyzes in detail the performance of several CSMA variants. Under some assumptions about the transmission channel and the traffic, the analysis compares ALOHA, slotted ALOHA, persistent and non-persistent CSMA. Under these assumptions, ALOHA achieves a channel utilization of only 18.4% of the channel capacity. Slotted ALOHA is able to use 36.6% of this capacity. Persistent CSMA improves the utilization by reaching 52.9% of the capacity while non-persistent CSMA achieves 81.5% of the channel capacity.
Carrier Sense Multiple Access with Collision Detection¶
CSMA improves channel utilization compared to ALOHA. However, the performance can still be improved, especially in wired networks. Consider the situation of two terminals that are connected to the same cable. This cable could, for example, be a coaxial cable as in the early days of Ethernet [Metcalfe1976]. It could also be built with twisted pairs. Before extending CSMA, it is useful to understand more intuitively, how frames are transmitted in such a network and how collisions can occur. The figure below illustrates the physical transmission of a frame on such a cable. To transmit its frame, host A must send an electrical signal on the shared medium. The first step is thus to begin the transmission of the electrical signal. This is point (1) in the figure below. This electrical signal will travel along the cable. Although electrical signals travel fast, we know that information cannot travel faster than the speed of light (i.e. 300.000 kilometers/second). On a coaxial cable, an electrical signal is slightly slower than the speed of light and 200.000 kilometers per second is a reasonable estimation. This implies that if the cable has a length of one kilometer, the electrical signal will need 5 microseconds to travel from one end of the cable to the other. The ends of coaxial cables are equipped with termination points that ensure that the electrical signal is not reflected back to its source. This is illustrated at point (3) in the figure, where the electrical signal has reached the left endpoint and host B. At this point, B starts to receive the frame being transmitted by A. Notice that there is a delay between the transmission of a bit on host A and its reception by host B. If there were other hosts attached to the cable, they would receive the first bit of the frame at slightly different times. As we will see later, this timing difference is a key problem for MAC algorithms. At point (4), the electrical signal has reached both ends of the cable and occupies it completely. Host A continues to transmit the electrical signal until the end of the frame. As shown at point (5), when the sending host stops its transmission, the electrical signal corresponding to the end of the frame leaves the coaxial cable. The channel becomes empty again once the entire electrical signal has been removed from the cable.
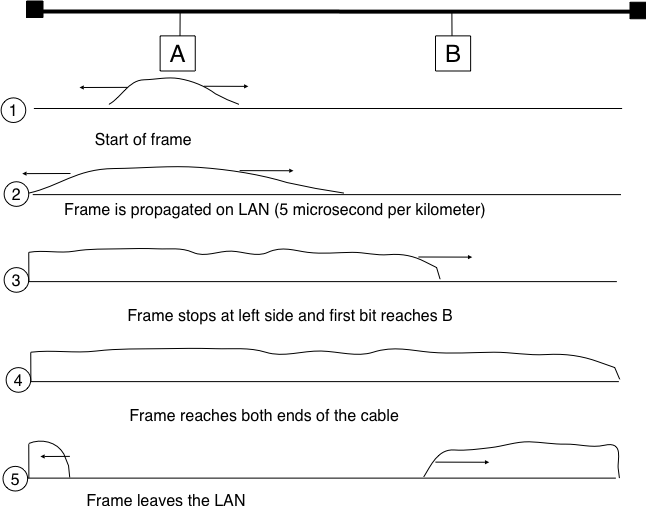
Frame transmission on a shared bus
Now that we have looked at how a frame is actually transmitted as an electrical signal on a shared bus, it is interesting to look in more detail at what happens when two hosts transmit a frame at almost the same time. This is illustrated in the figure below, where hosts A and B start their transmission at the same time (point (1)). At this time, if host C senses the channel, it will consider it to be free. This will not last a long time and at point (2) the electrical signals from both host A and host B reach host C. The combined electrical signal (shown graphically as the superposition of the two curves in the figure) cannot be decoded by host C. Host C detects a collision, as it receives a signal that it cannot decode. Since host C cannot decode the frames, it cannot determine which hosts are sending the colliding frames. Note that host A (and host B) will detect the collision after host C (point (3) in the figure below).
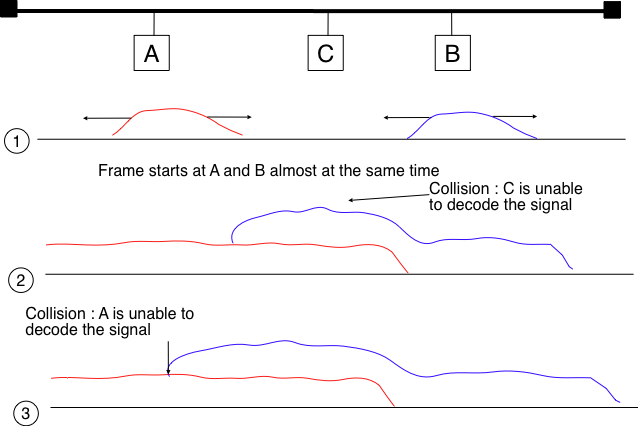
Frame collision on a shared bus
As shown above, hosts detect collisions when they receive an electrical signal that they cannot decode. In a wired network, a host is able to detect such a collision both while it is listening (e.g. like host C in the figure above) and also while it is sending its own frame. When a host transmits a frame, it can compare the electrical signal that it transmits with the electrical signal that it senses on the wire. At points (1) and (2) in the figure above, host A senses only its own signal. At point (3), it senses an electrical signal that differs from its own signal and can thus detects the collision. At this point, its frame is corrupted and it can stop its transmission. The ability to detect collisions while transmitting is the starting point for the Carrier Sense Multiple Access with Collision Detection (CSMA/CD) Medium Access Control algorithm, which is used in Ethernet networks [Metcalfe1976] [802.3] . When an Ethernet host detects a collision while it is transmitting, it immediately stops its transmission. Compared with pure CSMA, CSMA/CD is an important improvement since when collisions occur, they only last until colliding hosts have detected it and stopped their transmission. In practice, when a host detects a collision, it sends a special jamming signal on the cable to ensure that all hosts have detected the collision.
To better understand these collisions, it is useful to analyse what would be the worst collision on a shared bus network. Let us consider a wire with two hosts attached at both ends, as shown in the figure below. Host A starts to transmit its frame and its electrical signal is propagated on the cable. Its propagation time depends on the physical length of the cable and the speed of the electrical signal. Let us use 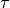 to represent this propagation delay in seconds. Slightly less than seconds after the beginning of the transmission of A’s frame, B decides to start transmitting its own frame. After
to represent this propagation delay in seconds. Slightly less than seconds after the beginning of the transmission of A’s frame, B decides to start transmitting its own frame. After  seconds, B senses A’s frame, detects the collision and stops transmitting. The beginning of B’s frame travels on the cable until it reaches host A. Host A can thus detect the collision at time
seconds, B senses A’s frame, detects the collision and stops transmitting. The beginning of B’s frame travels on the cable until it reaches host A. Host A can thus detect the collision at time 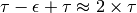 . An important point to note is that a collision can only occur during the first
. An important point to note is that a collision can only occur during the first 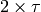 seconds of its transmission. If a collision did not occur during this period, it cannot occur afterwards since the transmission channel is busy after seconds and CSMA/CD hosts sense the transmission channel before transmitting their frame.
seconds of its transmission. If a collision did not occur during this period, it cannot occur afterwards since the transmission channel is busy after seconds and CSMA/CD hosts sense the transmission channel before transmitting their frame.

The worst collision on a shared bus
Furthermore, on the wired networks where CSMA/CD is used, collisions are almost the only cause of transmission errors that affect frames. Transmission errors that only affect a few bits inside a frame seldom occur in these wired networks. For this reason, the designers of CSMA/CD chose to completely remove the acknowledgement frames in the datalink layer. When a host transmits a frame, it verifies whether its transmission has been affected by a collision. If not, given the negligible Bit Error Ratio of the underlying network, it assumes that the frame was received correctly by its destination. Otherwise the frame is retransmitted after some delay.
Removing acknowledgements is an interesting optimisation as it reduces the number of frames that are exchanged on the network and the number of frames that need to be processed by the hosts. However, to use this optimisation, we must ensure that all hosts will be able to detect all the collisions that affect their frames. The problem is important for short frames. Let us consider two hosts, A and B, that are sending a small frame to host C as illustrated in the figure below. If the frames sent by A and B are very short, the situation illustrated below may occur. Hosts A and B send their frame and stop transmitting (point (1)). When the two short frames arrive at the location of host C, they collide and host C cannot decode them (point (2)). The two frames are absorbed by the ends of the wire. Neither host A nor host B have detected the collision. They both consider their frame to have been received correctly by its destination.
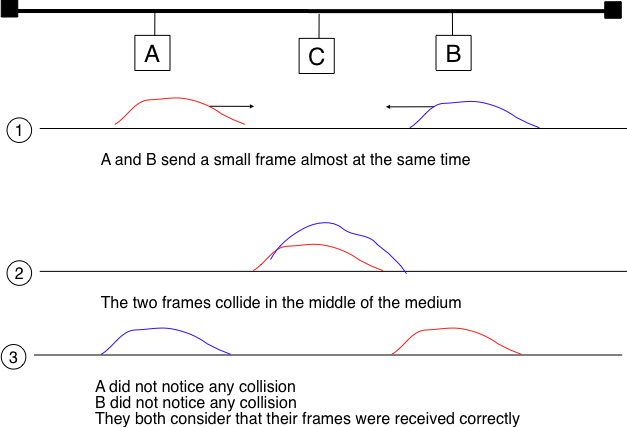
The short-frame collision problem
To solve this problem, networks using CSMA/CD require hosts to transmit for at least seconds. Since the network transmission speed is fixed for a given network technology, this implies that a technology that uses CSMA/CD enforces a minimum frame size. In the most popular CSMA/CD technology, Ethernet, is called the slot time [1].
The last innovation introduced by CSMA/CD is the computation of the retransmission timeout. As for ALOHA, this timeout cannot be fixed, otherwise hosts could become synchronised and always retransmit at the same time. Setting such a timeout is always a compromise between the network access delay and the amount of collisions. A short timeout would lead to a low network access delay but with a higher risk of collisions. On the other hand, a long timeout would cause a long network access delay but a lower risk of collisions. The binary exponential back-off algorithm was introduced in CSMA/CD networks to solve this problem.
To understand binary exponential back-off, let us consider a collision caused by exactly two hosts. Once it has detected the collision, a host can either retransmit its frame immediately or defer its transmission for some time. If each colliding host flips a coin to decide whether to retransmit immediately or to defer its retransmission, four cases are possible :
- Both hosts retransmit immediately and a new collision occurs
- The first host retransmits immediately and the second defers its retransmission
- The second host retransmits immediately and the first defers its retransmission
- Both hosts defer their retransmission and a new collision occurs
In the second and third cases, both hosts have flipped different coins. The delay chosen by the host that defers its retransmission should be long enough to ensure that its retransmission will not collide with the immediate retransmission of the other host. However the delay should not be longer than the time necessary to avoid the collision, because if both hosts decide to defer their transmission, the network will be idle during this delay. The slot time is the optimal delay since it is the shortest delay that ensures that the first host will be able to retransmit its frame completely without any collision.
If two hosts are competing, the algorithm above will avoid a second collision 50% of the time. However, if the network is heavily loaded, several hosts may be competing at the same time. In this case, the hosts should be able to automatically adapt their retransmission delay. The binary exponential back-off performs this adaptation based on the number of collisions that have affected a frame. After the first collision, the host flips a coin and waits 0 or 1 slot time. After the second collision, it generates a random number and waits 0, 1, 2 or 3 slot times, etc. The duration of the waiting time is doubled after each collision. The complete pseudo-code for the CSMA/CD algorithm is shown in the figure below.
# CSMA/CD pseudo-code
N=1
while N<= max :
wait(channel_becomes_free)
send(frame)
wait_until (end_of_frame) or (collision)
if collision detected:
stop transmitting
send(jamming)
k = min (10, N)
r = random(0, 2k - 1) * slotTime
wait(r*slotTime)
N=N+1
else :
wait(inter-frame_delay)
break
# end of while loop
# Too many transmission attempts
The inter-frame delay used in this pseudo-code is a short delay corresponding to the time required by a network adapter to switch from transmit to receive mode. It is also used to prevent a host from sending a continuous stream of frames without leaving any transmission opportunities for other hosts on the network. This contributes to the fairness of CSMA/CD. Despite this delay, there are still conditions where CSMA/CD is not completely fair [RY1994]. Consider for example a network with two hosts : a server sending long frames and a client sending acknowledgments. Measurements reported in [RY1994] have shown that there are situations where the client could suffer from repeated collisions that lead it to wait for long periods of time due to the exponential back-off algorithm.
| [1] | This name should not be confused with the duration of a transmission slot in slotted ALOHA. In CSMA/CD networks, the slot time is the time during which a collision can occur at the beginning of the transmission of a frame. In slotted ALOHA, the duration of a slot is the transmission time of an entire fixed-size frame. |
Carrier Sense Multiple Access with Collision Avoidance¶
The Carrier Sense Multiple Access with Collision Avoidance (CSMA/CA) Medium Access Control algorithm was designed for the popular WiFi wireless network technology [802.11]. CSMA/CA also senses the transmission channel before transmitting a frame. Furthermore, CSMA/CA tries to avoid collisions by carefully tuning the timers used by CSMA/CA devices.
CSMA/CA uses acknowledgements like CSMA. Each frame contains a sequence number and a CRC. The CRC is used to detect transmission errors while the sequence number is used to avoid frame duplication. When a device receives a correct frame, it returns a special acknowledgement frame to the sender. CSMA/CA introduces a small delay, named Short Inter Frame Spacing (SIFS), between the reception of a frame and the transmission of the acknowledgement frame. This delay corresponds to the time that is required to switch the radio of a device between the reception and transmission modes.
Compared to CSMA, CSMA/CA defines more precisely when a device is allowed to send a frame. First, CSMA/CA defines two delays : DIFS and EIFS. To send a frame, a device must first wait until the channel has been idle for at least the Distributed Coordination Function Inter Frame Space (DIFS) if the previous frame was received correctly. However, if the previously received frame was corrupted, this indicates that there are collisions and the device must sense the channel idle for at least the Extended Inter Frame Space (EIFS), with 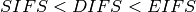 . The exact values for SIFS, DIFS and EIFS depend on the underlying physical layer [802.11].
. The exact values for SIFS, DIFS and EIFS depend on the underlying physical layer [802.11].
The figure below shows the basic operation of CSMA/CA devices. Before transmitting, host A verifies that the channel is empty for a long enough period. Then, its sends its data frame. After checking the validity of the received frame, the recipient sends an acknowledgement frame after a short SIFS delay. Host C, which does not participate in the frame exchange, senses the channel to be busy at the beginning of the data frame. Host C can use this information to determine how long the channel will be busy for. Note that as , even a device that would start to sense the channel immediately after the last bit of the data frame could not decide to transmit its own frame during the transmission of the acknowledgement frame.

Operation of a CSMA/CA device
The main difficulty with CSMA/CA is when two or more devices transmit at the same time and cause collisions. This is illustrated in the figure below, assuming a fixed timeout after the transmission of a data frame. With CSMA/CA, the timeout after the transmission of a data frame is very small, since it corresponds to the SIFS plus the time required to transmit the acknowledgement frame.

Collisions with CSMA/CA
To deal with this problem, CSMA/CA relies on a backoff timer. This backoff timer is a random delay that is chosen by each device in a range that depends on the number of retransmissions for the current frame. The range grows exponentially with the retransmissions as in CSMA/CD. The minimum range for the backoff timer is ![[0,7*slotTime]](../_images/math/96ac5e58c9ba6a48771158319e2434e4f1b44bbc.png) where the slotTime is a parameter that depends on the underlying physical layer. Compared to CSMA/CD’s exponential backoff, there are two important differences to notice. First, the initial range for the backoff timer is seven times larger. This is because it is impossible in CSMA/CA to detect collisions as they happen. With CSMA/CA, a collision may affect the entire frame while with CSMA/CD it can only affect the beginning of the frame. Second, a CSMA/CA device must regularly sense the transmission channel during its back off timer. If the channel becomes busy (i.e. because another device is transmitting), then the back off timer must be frozen until the channel becomes free again. Once the channel becomes free, the back off timer is restarted. This is in contrast with CSMA/CD where the back off is recomputed after each collision. This is illustrated in the figure below. Host A chooses a smaller backoff than host C. When C senses the channel to be busy, it freezes its backoff timer and only restarts it once the channel is free again.
where the slotTime is a parameter that depends on the underlying physical layer. Compared to CSMA/CD’s exponential backoff, there are two important differences to notice. First, the initial range for the backoff timer is seven times larger. This is because it is impossible in CSMA/CA to detect collisions as they happen. With CSMA/CA, a collision may affect the entire frame while with CSMA/CD it can only affect the beginning of the frame. Second, a CSMA/CA device must regularly sense the transmission channel during its back off timer. If the channel becomes busy (i.e. because another device is transmitting), then the back off timer must be frozen until the channel becomes free again. Once the channel becomes free, the back off timer is restarted. This is in contrast with CSMA/CD where the back off is recomputed after each collision. This is illustrated in the figure below. Host A chooses a smaller backoff than host C. When C senses the channel to be busy, it freezes its backoff timer and only restarts it once the channel is free again.

Detailed example with CSMA/CA
The pseudo-code below summarises the operation of a CSMA/CA device. The values of the SIFS, DIFS, EIFS and slotTime depend on the underlying physical layer technology [802.11]
# CSMA/CA simplified pseudo-code
N=1
while N<= max :
waitUntil(free(channel))
if correct(last_frame) :
wait(channel_free_during_t >=DIFS)
else:
wait(channel_free_during_t >=EIFS)
back-off_time = int(random[0,min(255,7*(2^(N-1)))])*slotTime
wait(channel free during backoff_time)
# backoff timer is frozen while channel is sensed to be busy
send(frame)
wait(ack or timeout)
if received(ack)
# frame received correctly
break
else:
# retransmission required
N=N+1
Another problem faced by wireless networks is often called the hidden station problem. In a wireless network, radio signals are not always propagated same way in all directions. For example, two devices separated by a wall may not be able to receive each other’s signal while they could both be receiving the signal produced by a third host. This is illustrated in the figure below, but it can happen in other environments. For example, two devices that are on different sides of a hill may not be able to receive each other’s signal while they are both able to receive the signal sent by a station at the top of the hill. Furthermore, the radio propagation conditions may change with time. For example, a truck may temporarily block the communication between two nearby devices.

The hidden station problem
To avoid collisions in these situations, CSMA/CA allows devices to reserve the transmission channel for some time. This is done by using two control frames : Request To Send (RTS) and Clear To Send (CTS). Both are very short frames to minimize the risk of collisions. To reserve the transmission channel, a device sends a RTS frame to the intended recipient of the data frame. The RTS frame contains the duration of the requested reservation. The recipient replies, after a SIFS delay, with a CTS frame which also contains the duration of the reservation. As the duration of the reservation has been sent in both RTS and CTS, all hosts that could collide with either the sender or the reception of the data frame are informed of the reservation. They can compute the total duration of the transmission and defer their access to the transmission channel until then. This is illustrated in the figure below where host A reserves the transmission channel to send a data frame to host B. Host C notices the reservation and defers its transmission.

Reservations with CSMA/CA
The utilization of the reservations with CSMA/CA is an optimisation that is useful when collisions are frequent. If there are few collisions, the time required to transmit the RTS and CTS frames can become significant and in particular when short frames are exchanged. Some devices only turn on RTS/CTS after transmission errors.
Deterministic Medium Access Control algorithms¶
During the 1970s and 1980s, there were huge debates in the networking community about the best suited Medium Access Control algorithms for Local Area Networks. The optimistic algorithms that we have described until now were relatively easy to implement when they were designed. From a performance perspective, mathematical models and simulations showed the ability of these optimistic techniques to sustain load. However, none of the optimistic techniques are able to guarantee that a frame will be delivered within a given delay bound and some applications require predictable transmission delays. The deterministic MAC algorithms were considered by a fraction of the networking community as the best solution to fulfill the needs of Local Area Networks.
Both the proponents of the deterministic and the opportunistic techniques lobbied to develop standards for Local Area networks that would incorporate their solution. Instead of trying to find an impossible compromise between these diverging views, the IEEE 802 committee that was chartered to develop Local Area Network standards chose to work in parallel on three different LAN technologies and created three working groups. The IEEE 802.3 working group became responsible for CSMA/CD. The proponents of deterministic MAC algorithms agreed on the basic principle of exchanging special frames called tokens between devices to regulate the access to the transmission medium. However, they did not agree on the most suitable physical layout for the network. IBM argued in favor of Ring-shaped networks while the manufacturing industry, led by General Motors, argued in favor of a bus-shaped network. This led to the creation of the IEEE 802.4 working group to standardise Token Bus networks and the IEEE 802.5 working group to standardise Token Ring networks. Although these techniques are not widely used anymore today, the principles behind a token-based protocol are still important.
The IEEE 802.5 Token Ring technology is defined in [802.5]. We use Token Ring as an example to explain the principles of the token-based MAC algorithms in ring-shaped networks. Other ring-shaped networks include the almost defunct FDDI [Ross1989] or the more recent Resilient Pack Ring [DYGU2004] . A good survey of the token ring networks may be found in [Bux1989] .
A Token Ring network is composed of a set of stations that are attached to a unidirectional ring. The basic principle of the Token Ring MAC algorithm is that two types of frames travel on the ring : tokens and data frames. When the Token Ring starts, one of the stations sends the token. The token is a small frame that represents the authorization to transmit data frames on the ring. To transmit a data frame on the ring, a station must first capture the token by removing it from the ring. As only one station can capture the token at a time, the station that owns the token can safely transmit a data frame on the ring without risking collisions. After having transmitted its frame, the station must remove it from the ring and resend the token so that other stations can transmit their own frames.
A Token Ring network
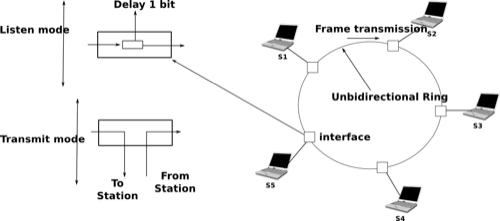
While the basic principles of the Token Ring are simple, there are several subtle implementation details that add complexity to Token Ring networks. To understand these details let us analyse the operation of a Token Ring interface on a station. A Token Ring interface serves three different purposes. Like other LAN interfaces, it must be able to send and receive frames. In addition, a Token Ring interface is part of the ring, and as such, it must be able to forward the electrical signal that passes on the ring even when its station is powered off.
When powered-on, Token Ring interfaces operate in two different modes : listen and transmit. When operating in listen mode, a Token Ring interface receives an electrical signal from its upstream neighbour on the ring, introduces a delay equal to the transmission time of one bit on the ring and regenerates the signal before sending it to its downstream neighbour on the ring.
The first problem faced by a Token Ring network is that as the token represents the authorization to transmit, it must continuously travel on the ring when no data frame is being transmitted. Let us assume that a token has been produced and sent on the ring by one station. In Token Ring networks, the token is a 24 bits frame whose structure is shown below.

802.5 token format
The token is composed of three fields. First, the Starting Delimiter is the marker that indicates the beginning of a frame. The first Token Ring networks used Manchester coding and the Starting Delimiter contained both symbols representing 0 and symbols that do not represent bits. The last field is the Ending Delimiter which marks the end of the token. The Access Control field is present in all frames, and contains several flags. The most important is the Token bit that is set in token frames and reset in other frames.
Let us consider the five station network depicted in figure A Token Ring network above and assume that station S1 sends a token. If we neglect the propagation delay on the inter-station links, as each station introduces a one bit delay, the first bit of the frame would return to S1 while it sends the fifth bit of the token. If station S1 is powered off at that time, only the first five bits of the token will travel on the ring. To avoid this problem, there is a special station called the Monitor on each Token Ring. To ensure that the token can travel forever on the ring, this Monitor inserts a delay that is equal to at least 24 bit transmission times. If station S3 was the Monitor in figure A Token Ring network, S1 would have been able to transmit the entire token before receiving the first bit of the token from its upstream neighbour.
Now that we have explained how the token can be forwarded on the ring, let us analyse how a station can capture a token to transmit a data frame. For this, we need some information about the format of the data frames. An 802.5 data frame begins with the Starting Delimiter followed by the Access Control field whose Token bit is reset, a Frame Control field that allows for the definition of several types of frames, destination and source address, a payload, a CRC, the Ending Delimiter and a Frame Status field. The format of the Token Ring data frames is illustrated below.

802.5 data frame format
To capture a token, a station must operate in Listen mode. In this mode, the station receives bits from its upstream neighbour. If the bits correspond to a data frame, they must be forwarded to the downstream neighbour. If they correspond to a token, the station can capture it and transmit its data frame. Both the data frame and the token are encoded as a bit string beginning with the Starting Delimiter followed by the Access Control field. When the station receives the first bit of a Starting Delimiter, it cannot know whether this is a data frame or a token and must forward the entire delimiter to its downstream neighbour. It is only when it receives the fourth bit of the Access Control field (i.e. the Token bit) that the station knows whether the frame is a data frame or a token. If the Token bit is reset, it indicates a data frame and the remaining bits of the data frame must be forwarded to the downstream station. Otherwise (Token bit is set), this is a token and the station can capture it by resetting the bit that is currently in its buffer. Thanks to this modification, the beginning of the token is now the beginning of a data frame and the station can switch to Transmit mode and send its data frame starting at the fifth bit of the Access Control field. Thus, the one-bit delay introduced by each Token Ring station plays a key role in enabling the stations to efficiently capture the token.
After having transmitted its data frame, the station must remain in Transmit mode until it has received the last bit of its own data frame. This ensures that the bits sent by a station do not remain in the network forever. A data frame sent by a station in a Token Ring network passes in front of all stations attached to the network. Each station can detect the data frame and analyse the destination address to possibly capture the frame.
The Frame Status field that appears after the Ending Delimiter is used to provide acknowledgements without requiring special frames. The Frame Status contains two flags : A and C. Both flags are reset when a station sends a data frame. These flags can be modified by their recipients. When a station senses its address as the destination address of a frame, it can capture the frame, check its CRC and place it in its own buffers. The destination of a frame must set the A bit (resp. C bit) of the Frame Status field once it has seen (resp. copied) a data frame. By inspecting the Frame Status of the returning frame, the sender can verify whether its frame has been received correctly by its destination.
The text above describes the basic operation of a Token Ring network when all stations work correctly. Unfortunately, a real Token Ring network must be able to handle various types of anomalies and this increases the complexity of Token Ring stations. We briefly list the problems and outline their solutions below. A detailed description of the operation of Token Ring stations may be found in [802.5]. The first problem is when all the stations attached to the network start. One of them must bootstrap the network by sending the first token. For this, all stations implement a distributed election mechanism that is used to select the Monitor. Any station can become a Monitor. The Monitor manages the Token Ring network and ensures that it operates correctly. Its first role is to introduce a delay of 24 bit transmission times to ensure that the token can travel smoothly on the ring. Second, the Monitor sends the first token on the ring. It must also verify that the token passes regularly. According to the Token Ring standard [802.5], a station cannot retain the token to transmit data frames for a duration longer than the Token Holding Time (THT) (slightly less than 10 milliseconds). On a network containing N stations, the Monitor must receive the token at least every 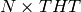 seconds. If the Monitor does not receive a token during such a period, it cuts the ring for some time and then reinitialises the ring and sends a token.
seconds. If the Monitor does not receive a token during such a period, it cuts the ring for some time and then reinitialises the ring and sends a token.
Several other anomalies may occur in a Token Ring network. For example, a station could capture a token and be powered off before having resent the token. Another station could have captured the token, sent its data frame and be powered off before receiving all of its data frame. In this case, the bit string corresponding to the end of a frame would remain in the ring without being removed by its sender. Several techniques are defined in [802.5] to allow the Monitor to handle all these problems. If unfortunately, the Monitor fails, another station will be elected to become the new Monitor.
Datalink layer technologies¶
In this section, we review the key characteristics of several datalink layer technologies. We discuss in more detail the technologies that are widely used today. A detailed survey of all datalink layer technologies would be outside the scope of this book.
The Point-to-Point Protocol¶
Many point-to-point datalink layers [2] have been developed, starting in the 1960s [McFadyen1976]. In this section, we focus on the protocols that are often used to transport IP packets between hosts or routers that are directly connected by a point-to-point link. This link can be a dedicated physical cable, a leased line through the telephone network or a dial-up connection with modems on the two communicating hosts.
The first solution to transport IP packets over a serial line was proposed in RFC 1055 and is known as Serial Line IP (SLIP). SLIP is a simple character stuffing technique applied to IP packets. SLIP defines two special characters : END (decimal 192) and ESC (decimal 219). END appears at the beginning and at the end of each transmitted IP packet and the sender adds ESC before each END character inside each transmitted IP packet. SLIP only supports the transmission of IP packets and it assumes that the two communicating hosts/routers have been manually configured with each other’s IP address. SLIP was mainly used over links offering bandwidth of often less than 20 Kbps. On such a low bandwidth link, sending 20 bytes of IP header followed by 20 bytes of TCP header for each TCP segment takes a lot of time. This initiated the development of a family of compression techniques to efficiently compress the TCP/IP headers. The first header compression technique proposed in RFC 1144 was designed to exploit the redundancy between several consecutive segments that belong to the same TCP connection. In all these segments, the IP addresses and port numbers are always the same. Furthermore, fields such as the sequence and acknowledgement numbers do not change in a random way. RFC 1144 defined simple techniques to reduce the redundancy found in successive segments. The development of header compression techniques continued and there are still improvements being developed now RFC 5795.
While SLIP was implemented and used in some environments, it had several limitations discussed in RFC 1055. The Point-to-Point Protocol (PPP) was designed shortly after and is specified in RFC 1548. PPP aims to support IP and other network layer protocols over various types of serial lines. PPP is in fact a family of three protocols that are used together :
- The Point-to-Point Protocol defines the framing technique to transport network layer packets.
- The Link Control Protocol that is used to negotiate options and authenticate the session by using username and password or other types of credentials
- The Network Control Protocol that is specific for each network layer protocol. It is used to negotiate options that are specific for each protocol. For example, IPv4’s NCP RFC 1548 can negotiate the IPv4 address to be used, the IPv4 address of the DNS resolver. IPv6’s NCP is defined in RFC 5072.
The PPP framing RFC 1662 was inspired by the datalink layer protocols standardised by ITU-T and ISO. A typical PPP frame is composed of the fields shown in the figure below. A PPP frame starts with a one byte flag containing 01111110. PPP can use bit stuffing or character stuffing depending on the environment where the protocol is used. The address and control fields are present for backward compatibility reasons. The 16 bit Protocol field contains the identifier [3] of the network layer protocol that is carried in the PPP frame. 0x002d is used for an IPv4 packet compressed with RFC 1144 while 0x002f is used for an uncompressed IPv4 packet. 0xc021 is used by the Link Control Protocol, 0xc023 is used by the Password Authentication Protocol (PAP). 0x0057 is used for IPv6 packets. PPP supports variable length packets, but LCP can negotiate a maximum packet length. The PPP frame ends with a Frame Check Sequence. The default is a 16 bits CRC, but some implementations can negotiate a 32 bits CRC. The frame ends with the 01111110 flag.

PPP frame format
PPP played a key role in allowing Internet Service Providers to provide dial-up access over modems in the late 1990s and early 2000s. ISPs operated modem banks connected to the telephone network. For these ISPs, a key issue was to authenticate each user connected through the telephone network. This authentication was performed by using the Extensible Authentication Protocol (EAP) defined in RFC 3748. EAP is a simple, but extensible protocol that was initially used by access routers to authenticate the users connected through dialup lines. Several authentication methods, starting from the simple username/password pairs to more complex schemes have been defined and implemented. When ISPs started to upgrade their physical infrastructure to provide Internet access over Asymmetric Digital Subscriber Lines (ADSL), they tried to reuse their existing authentication (and billing) systems. To meet these requirements, the IETF developed specifications to allow PPP frames to be transported over other networks than the point-to-point links for which PPP was designed. Nowadays, most ADSL deployments use PPP over either ATM RFC 2364 or Ethernet RFC 2516.
| [2] | LAPB and HDLC were widely used datalink layer protocols. |
| [3] | The IANA maintains the registry of all assigned PPP protocol fields at : http://www.iana.org/assignments/ppp-numbers |
Ethernet¶
Ethernet was designed in the 1970s at the Palo Alto Research Center [Metcalfe1976]. The first prototype [5] used a coaxial cable as the shared medium and 3 Mbps of bandwidth. Ethernet was improved during the late 1970s and in the 1980s, Digital Equipment, Intel and Xerox published the first official Ethernet specification [DIX]. This specification defines several important parameters for Ethernet networks. The first decision was to standardise the commercial Ethernet at 10 Mbps. The second decision was the duration of the slot time. In Ethernet, a long slot time enables networks to span a long distance but forces the host to use a larger minimum frame size. The compromise was a slot time of 51.2 microseconds, which corresponds to a minimum frame size of 64 bytes.
The third decision was the frame format. The experimental 3 Mbps Ethernet network built at Xerox used short frames containing 8 bit source and destination addresses fields, a 16 bit type indication, up to 554 bytes of payload and a 16 bit CRC. Using 8 bit addresses was suitable for an experimental network, but it was clearly too small for commercial deployments. Although the initial Ethernet specification [DIX] only allowed up to 1024 hosts on an Ethernet network, it also recommended three important changes compared to the networking technologies that were available at that time. The first change was to require each host attached to an Ethernet network to have a globally unique datalink layer address. Until then, datalink layer addresses were manually configured on each host. [DP1981] went against that state of the art and noted “Suitable installation-specific administrative procedures are also needed for assigning numbers to hosts on a network. If a host is moved from one network to another it may be necessary to change its host number if its former number is in use on the new network. This is easier said than done, as each network must have an administrator who must record the continuously changing state of the system (often on a piece of paper tacked to the wall !). It is anticipated that in future office environments, hosts locations will change as often as telephones are changed in present-day offices.” The second change introduced by Ethernet was to encode each address as a 48 bits field [DP1981]. 48 bit addresses were huge compared to the networking technologies available in the 1980s, but the huge address space had several advantages [DP1981] including the ability to allocate large blocks of addresses to manufacturers. Eventually, other LAN technologies opted for 48 bits addresses as well [802]_ . The third change introduced by Ethernet was the definition of broadcast and multicast addresses. The need for multicast Ethernet was foreseen in [DP1981] and thanks to the size of the addressing space it was possible to reserve a large block of multicast addresses for each manufacturer.
The datalink layer addresses used in Ethernet networks are often called MAC addresses. They are structured as shown in the figure below. The first bit of the address indicates whether the address identifies a network adapter or a multicast group. The upper 24 bits are used to encode an Organisation Unique Identifier (OUI). This OUI identifies a block of addresses that has been allocated by the secretariat [6] who is responsible for the uniqueness of Ethernet addresses to a manufacturer. Once a manufacturer has received an OUI, it can build and sell products with one of the 16 million addresses in this block.

48 bits Ethernet address format
The original 10 Mbps Ethernet specification [DIX] defined a simple frame format where each frame is composed of five fields. The Ethernet frame starts with a preamble (not shown in the figure below) that is used by the physical layer of the receiver to synchronise its clock with the sender’s clock. The first field of the frame is the destination address. As this address is placed at the beginning of the frame, an Ethernet interface can quickly verify whether it is the frame recipient and if not, cancel the processing of the arriving frame. The second field is the source address. While the destination address can be either a unicast or a multicast/broadcast address, the source address must always be a unicast address. The third field is a 16 bits integer that indicates which type of network layer packet is carried inside the frame. This field is often called the EtherType. Frequently used EtherType values [7] include 0x0800 for IPv4, 0x86DD for IPv6 [8] and 0x806 for the Address Resolution Protocol (ARP).
The fourth part of the Ethernet frame is the payload. The minimum length of the payload is 46 bytes to ensure a minimum frame size, including the header of 512 bits. The Ethernet payload cannot be longer than 1500 bytes. This size was found reasonable when the first Ethernet specification was written. At that time, Xerox had been using its experimental 3 Mbps Ethernet that offered 554 bytes of payload and RFC 1122 required a minimum MTU of 572 bytes for IPv4. 1500 bytes was large enough to support these needs without forcing the network adapters to contain overly large memories. Furthermore, simulations and measurement studies performed in Ethernet networks revealed that CSMA/CD was able to achieve a very high utilization. This is illustrated in the figure below based on [SH1980], which shows the channel utilization achieved in Ethernet networks containing different numbers of hosts that are sending frames of different sizes.
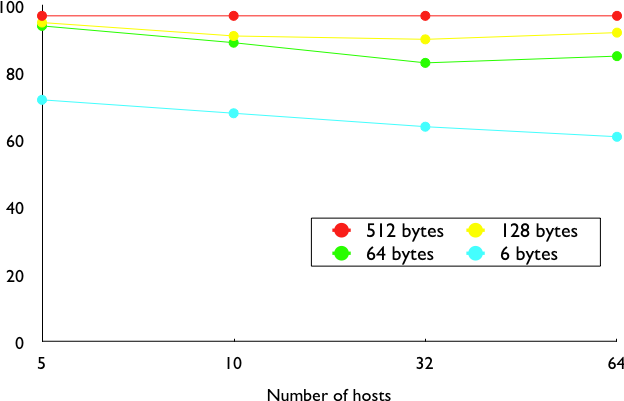
Impact of the frame length on the maximum channel utilisation [SH1980]
The last field of the Ethernet frame is a 32 bit Cyclical Redundancy Check (CRC). This CRC is able to catch a much larger number of transmission errors than the Internet checksum used by IP, UDP and TCP [SGP98]. The format of the Ethernet frame is shown below.

Ethernet DIX frame format
Note
Where should the CRC be located in a frame ?
The transport and datalink layers usually chose different strategies to place their CRCs or checksums. Transport layer protocols usually place their CRCs or checksums in the segment header. Datalink layer protocols sometimes place their CRC in the frame header, but often in a trailer at the end of the frame. This choice reflects implementation assumptions, but also influences performance RFC 893. When the CRC is placed in the trailer, as in Ethernet, the datalink layer can compute it while transmitting the frame and insert it at the end of the transmission. All Ethernet interfaces use this optimisation today. When the checksum is placed in the header, as in a TCP segment, it is impossible for the network interface to compute it while transmitting the segment. Some network interfaces provide hardware assistance to compute the TCP checksum, but this is more complex than if the TCP checksum were placed in the trailer [4].
The Ethernet frame format shown above is specified in [DIX]. This is the format used to send both IPv4 RFC 894 and IPv6 packets RFC 2464. After the publication of [DIX], the Institute of Electrical and Electronic Engineers (IEEE) began to standardise several Local Area Network technologies. IEEE worked on several LAN technologies, starting with Ethernet, Token Ring and Token Bus. These three technologies were completely different, but they all agreed to use the 48 bits MAC addresses specified initially for Ethernet [802]_ . While developing its Ethernet standard [802.3], the IEEE 802.3 working group was confronted with a problem. Ethernet mandated a minimum payload size of 46 bytes, while some companies were looking for a LAN technology that could transparently transport short frames containing only a few bytes of payload. Such a frame can be sent by an Ethernet host by padding it to ensure that the payload is at least 46 bytes long. However since the Ethernet header [DIX] does not contain a length field, it is impossible for the receiver to determine how many useful bytes were placed inside the payload field. To solve this problem, the IEEE decided to replace the Type field of the Ethernet [DIX] header with a length field [9]. This Length field contains the number of useful bytes in the frame payload. The payload must still contain at least 46 bytes, but padding bytes are added by the sender and removed by the receiver. In order to add the Length field without significantly changing the frame format, IEEE had to remove the Type field. Without this field, it is impossible for a receiving host to identify the type of network layer packet inside a received frame. To solve this new problem, IEEE developed a completely new sublayer called the Logical Link Control [802.2]. Several protocols were defined in this sublayer. One of them provided a slightly different version of the Type field of the original Ethernet frame format. Another contained acknowledgements and retransmissions to provide a reliable service... In practice, [802.2] is never used to support IP in Ethernet networks. The figure below shows the official [802.3] frame format.

Ethernet 802.3 frame format
Note
What is the Ethernet service ?
- An Ethernet network provides an unreliable connectionless service. It supports three different transmission modes : unicast, multicast and broadcast. While the Ethernet service is unreliable in theory, a good Ethernet network should, in practice, provide a service that :
- delivers frames to their destination with a very high probability of successful delivery
- does not reorder the transmitted frames
The first property is a consequence of the utilisation of CSMA/CD. The second property is a consequence of the physical organisation of the Ethernet network as a shared bus. These two properties are important and all evolutions of the Ethernet technology have preserved them.
Several physical layers have been defined for Ethernet networks. The first physical layer, usually called 10Base5, provided 10 Mbps over a thick coaxial cable. The characteristics of the cable and the transceivers that were used then enabled the utilisation of 500 meter long segments. A 10Base5 network can also include repeaters between segments.
The second physical layer was 10Base2. This physical layer used a thin coaxial cable that was easier to install than the 10Base5 cable, but could not be longer than 185 meters. A 10BaseF physical layer was also defined to transport Ethernet over point-to-point optical links. The major change to the physical layer was the support of twisted pairs in the 10BaseT specification. Twisted pair cables are traditionally used to support the telephone service in office buildings. Most office buildings today are equipped with structured cabling. Several twisted pair cables are installed between any room and a central telecom closet per building or per floor in large buildings. These telecom closets act as concentration points for the telephone service but also for LANs.
The introduction of the twisted pairs led to two major changes to Ethernet. The first change concerns the physical topology of the network. 10Base2 and 10Base5 networks are shared buses, the coaxial cable typically passes through each room that contains a connected computer. A 10BaseT network is a star-shaped network. All the devices connected to the network are attached to a twisted pair cable that ends in the telecom closet. From a maintenance perspective, this is a major improvement. The cable is a weak point in 10Base2 and 10Base5 networks. Any physical damage on the cable broke the entire network and when such a failure occurred, the network administrator had to manually check the entire cable to detect where it was damaged. With 10BaseT, when one twisted pair is damaged, only the device connected to this twisted pair is affected and this does not affect the other devices. The second major change introduced by 10BaseT was that is was impossible to build a 10BaseT network by simply connecting all the twisted pairs together. All the twisted pairs must be connected to a relay that operates in the physical layer. This relay is called an Ethernet hub. A hub is thus a physical layer relay that receives an electrical signal on one of its interfaces, regenerates the signal and transmits it over all its other interfaces. Some hubs are also able to convert the electrical signal from one physical layer to another (e.g. 10BaseT to 10Base2 conversion).

Ethernet hubs in the reference model
Computers can directly be attached to Ethernet hubs. Ethernet hubs themselves can be attached to other Ethernet hubs to build a larger network. However, some important guidelines must be followed when building a complex network with hubs. First, the network topology must be a tree. As hubs are relays in the physical layer, adding a link between Hub2 and Hub3 in the network below would create an electrical shortcut that would completely disrupt the network. This implies that there cannot be any redundancy in a hub-based network. A failure of a hub or of a link between two hubs would partition the network into two isolated networks. Second, as hubs are relays in the physical layer, collisions can happen and must be handled by CSMA/CD as in a 10Base5 network. This implies that the maximum delay between any pair of devices in the network cannot be longer than the 51.2 microseconds slot time. If the delay is longer, collisions between short frames may not be correctly detected. This constraint limits the geographical spread of 10BaseT networks containing hubs.

A hierarchical Ethernet network composed of hubs
In the late 1980s, 10 Mbps became too slow for some applications and network manufacturers developed several LAN technologies that offered higher bandwidth, such as the 100 Mbps FDDI LAN that used optical fibers. As the development of 10Base5, 10Base2 and 10BaseT had shown that Ethernet could be adapted to different physical layers, several manufacturers started to work on 100 Mbps Ethernet and convinced IEEE to standardise this new technology that was initially called Fast Ethernet. Fast Ethernet was designed under two constraints. First, Fast Ethernet had to support twisted pairs. Although it was easier from a physical layer perspective to support higher bandwidth on coaxial cables than on twisted pairs, coaxial cables were a nightmare from deployment and maintenance perspectives. Second, Fast Ethernet had to be perfectly compatible with the existing 10 Mbps Ethernets to allow Fast Ethernet technology to be used initially as a backbone technology to interconnect 10 Mbps Ethernet networks. This forced Fast Ethernet to use exactly the same frame format as 10 Mbps Ethernet. This implied that the minimum Fast Ethernet frame size remained at 512 bits. To preserve CSMA/CD with this minimum frame size and 100 Mbps instead of 10 Mbps, the duration of the slot time was decreased to 5.12 microseconds.
The evolution of Ethernet did not stop. In 1998, the IEEE published a first standard to provide Gigabit Ethernet over optical fibers. Several other types of physical layers were added afterwards. The 10 Gigabit Ethernet standard appeared in 2002. Work is ongoing to develop standards for 40 Gigabit and 100 Gigabit Ethernet and some are thinking about Terabit Ethernet. The table below lists the main Ethernet standards. A more detailed list may be found at http://en.wikipedia.org/wiki/Ethernet_physical_layer
| Standard | Comments |
|---|---|
| 10Base5 | Thick coaxial cable, 500m |
| 10Base2 | Thin coaxial cable, 185m |
| 10BaseT | Two pairs of category 3+ UTP |
| 10Base-F | 10 Mb/s over optical fiber |
| 100Base-Tx | Category 5 UTP or STP, 100 m maximum |
| 100Base-FX | Two multimode optical fiber, 2 km maximum |
| 1000Base-CX | Two pairs shielded twisted pair, 25m maximum |
| 1000Base-SX | Two multimode or single mode optical fibers with lasers |
| 10 Gbps | Optical fiber but also Category 6 UTP |
| 40-100 Gbps | Optical fiber (experiences are performed with copper) |
Footnotes
| [4] | These network interfaces compute the TCP checksum while a segment is transferred from the host memory to the network interface [SH2004]. |
| [5] | Additional information about the history of the Ethernet technology may be found at http://ethernethistory.typepad.com/ |
| [6] | Initially, the OUIs were allocated by Xerox [DP1981]. However, once Ethernet became an IEEE and later an ISO standard, the allocation of the OUIs moved to IEEE. The list of all OUI allocations may be found at http://standards.ieee.org/regauth/oui/index.shtml |
| [7] | The official list of all assigned Ethernet type values is available from http://standards.ieee.org/regauth/ethertype/eth.txt |
| [8] | The attentive reader may question the need for different EtherTypes for IPv4 and IPv6 while the IP header already contains a version field that can be used to distinguish between IPv4 and IPv6 packets. Theoretically, IPv4 and IPv6 could have used the same EtherType. Unfortunately, developers of the early IPv6 implementations found that some devices did not check the version field of the IPv4 packets that they received and parsed frames whose EtherType was set to 0x0800 as IPv4 packets. Sending IPv6 packets to such devices would have caused disruptions. To avoid this problem, the IETF decided to apply for a distinct EtherType value for IPv6. Such a choice is now mandated by RFC 6274 (section 3.1), although we can find a funny counter-example in RFC 6214. |
| [9] | Fortunately, IEEE was able to define the [802.3] frame format while maintaining backward compatibility with the Ethernet [DIX] frame format. The trick was to only assign values above 1500 as EtherType values. When a host receives a frame, it can determine whether the frame’s format by checking its EtherType/Length field. A value lower smaller than 1501 is clearly a length indicator and thus an [802.3] frame. A value larger than 1501 can only be type and thus a [DIX] frame. |
Ethernet Switches¶
Increasing the physical layer bandwidth as in Fast Ethernet was only one of the solutions to improve the performance of Ethernet LANs. A second solution was to replace the hubs with more intelligent devices. As Ethernet hubs operate in the physical layer, they can only regenerate the electrical signal to extend the geographical reach of the network. From a performance perspective, it would be more interesting to have devices that operate in the datalink layer and can analyse the destination address of each frame and forward the frames selectively on the link that leads to the destination. Such devices are usually called Ethernet switches [10]. An Ethernet switch is a relay that operates in the datalink layer as is illustrated in the figure below.
Ethernet switches and the reference model
An Ethernet switch understands the format of the Ethernet frames and can selectively forward frames over each interface. For this, each Ethernet switch maintains a MAC address table. This table contains, for each MAC address known by the switch, the identifier of the switch’s port over which a frame sent towards this address must be forwarded to reach its destination. This is illustrated below with the MAC address table of the bottom switch. When the switch receives a frame destined to address B, it forwards the frame on its South port. If it receives a frame destined to address D, it forwards it only on its North port.

Operation of Ethernet switches
One of the selling points of Ethernet networks is that, thanks to the utilisation of 48 bits MAC addresses, an Ethernet LAN is plug and play at the datalink layer. When two hosts are attached to the same Ethernet segment or hub, they can immediately exchange Ethernet frames without requiring any configuration. It is important to retain this plug and play capability for Ethernet switches as well. This implies that Ethernet switches must be able to build their MAC address table automatically without requiring any manual configuration. This automatic configuration is performed by the MAC address learning algorithm that runs on each Ethernet switch. This algorithm extracts the source address of the received frames and remembers the port over which a frame from each source Ethernet address has been received. This information is inserted into the MAC address table that the switch uses to forward frames. This allows the switch to automatically learn the ports that it can use to reach each destination address, provided that this host has previously sent at least one frame. This is not a problem since most upper layer protocols use acknowledgements at some layer and thus even an Ethernet printer sends Ethernet frames as well.
The pseudo-code below details how an Ethernet switch forwards Ethernet frames. It first updates its MAC address table with the source address of the frame. The MAC address table used by some switches also contains a timestamp that is updated each time a frame is received from each known source address. This timestamp is used to remove from the MAC address table entries that have not been active during the last n minutes. This limits the growth of the MAC address table, but also allows hosts to move from one port to another. The switch uses its MAC address table to forward the received unicast frame. If there is an entry for the frame’s destination address in the MAC address table, the frame is forwarded selectively on the port listed in this entry. Otherwise, the switch does not know how to reach the destination address and it must forward the frame on all its ports except the port from which the frame has been received. This ensures that the frame will reach its destination, at the expense of some unnecessary transmissions. These unnecessary transmissions will only last until the destination has sent its first frame. Multicast and Broadcast frames are also forwarded in a similar way.
# Arrival of frame F on port P
# Table : MAC address table dictionary : addr->port
# Ports : list of all ports on the switch
src=F.SourceAddress
dst=F.DestinationAddress
Table[src]=P #src heard on port P
if isUnicast(dst) :
if dst in Table:
ForwardFrame(F,Table[dst])
else:
for o in Ports :
if o!= P : ForwardFrame(F,o)
else:
# multicast or broadcast destination
for o in Ports :
if o!= P : ForwardFrame(F,o)
Note
Security issues with Ethernet hubs and switches
From a security perspective, Ethernet hubs have the same drawbacks as the older coaxial cable. A host attached to a hub will be able to capture all the frames exchanged between any pair of hosts attached to the same hub. Ethernet switches are much better from this perspective thanks to the selective forwarding, a host will usually only receive the frames destined to itself as well as the multicast, broadcast and unknown frames. However, this does not imply that switches are completely secure. There are, unfortunately, attacks against Ethernet switches. From a security perspective, the MAC address table is one of the fragile elements of an Ethernet switch. This table has a fixed size. Some low-end switches can store a few tens or a few hundreds of addresses while higher-end switches can store tens of thousands of addresses or more. From a security point of view, a limited resource can be the target of Denial of Service attacks. Unfortunately, such attacks are also possible on Ethernet switches. A malicious host could overflow the MAC address table of the switch by generating thousands of frames with random source addresses. Once the MAC address table is full, the switch needs to broadcast all the frames that it receives. At this point, an attacker will receive unicast frames that are not destined to its address. The ARP attack discussed in the previous chapter could also occur with Ethernet switches [Vyncke2007]. Recent switches implement several types of defences against these attacks, but they need to be carefully configured by the network administrator. See [Vyncke2007] for a detailed discussion on security issues with Ethernet switches.
The MAC address learning algorithm combined with the forwarding algorithm work well in a tree-shaped network such as the one shown above. However, to deal with link and switch failures, network administrators often add redundant links to ensure that their network remains connected even after a failure. Let us consider what happens in the Ethernet network shown in the figure below.
Ethernet switches in a loop
When all switches boot, their MAC address table is empty. Assume that host A sends a frame towards host C. Upon reception of this frame, switch1 updates its MAC address table to remember that address A is reachable via its West port. As there is no entry for address C in switch1’s MAC address table, the frame is forwarded to both switch2 and switch3. When switch2 receives the frame, its updates its MAC address table for address A and forwards the frame to host C as well as to switch3. switch3 has thus received two copies of the same frame. As switch3 does not know how to reach the destination address, it forwards the frame received from switch1 to switch2 and the frame received from switch2 to switch1... The single frame sent by host A will be continuously duplicated by the switches until their MAC address table contains an entry for address C. Quickly, all the available link bandwidth will be used to forward all the copies of this frame. As Ethernet does not contain any TTL or HopLimit, this loop will never stop.
The MAC address learning algorithm allows switches to be plug-and-play. Unfortunately, the loops that arise when the network topology is not a tree are a severe problem. Forcing the switches to only be used in tree-shaped networks as hubs would be a severe limitation. To solve this problem, the inventors of Ethernet switches have developed the Spanning Tree Protocol. This protocol allows switches to automatically disable ports on Ethernet switches to ensure that the network does not contain any cycle that could cause frames to loop forever.
Footnotes
| [10] | The first Ethernet relays that operated in the datalink layers were called bridges. In practice, the main difference between switches and bridges is that bridges were usually implemented in software while switches are hardware-based devices. Throughout this text, we always use switch when referring to a relay in the datalink layer, but you might still see the word bridge. |
The Spanning Tree Protocol (802.1d)¶
The Spanning Tree Protocol (STP), proposed in [Perlman1985], is a distributed protocol that is used by switches to reduce the network topology to a spanning tree, so that there are no cycles in the topology. For example, consider the network shown in the figure below. In this figure, each bold line corresponds to an Ethernet to which two Ethernet switches are attached. This network contains several cycles that must be broken to allow Ethernet switches that are using the MAC address learning algorithm to exchange frames.
Spanning tree computed in a switched Ethernet network
In this network, the STP will compute the following spanning tree. Switch1 will be the root of the tree. All the interfaces of Switch1, Switch2 and Switch7 are part of the spanning tree. Only the interface connected to LANB will be active on Switch9. LANH will only be served by Switch7 and the port of Switch44 on LANG will be disabled. A frame originating on LANB and destined for LANA will be forwarded by Switch7 on LANC, then by Switch1 on LANE, then by Switch44 on LANF and eventually by Switch2 on LANA.
Switches running the Spanning Tree Protocol exchange BPDUs. These BPDUs are always sent as frames with destination MAC address as the ALL_BRIDGES reserved multicast MAC address. Each switch has a unique 64 bit identifier. To ensure uniqueness, the lower 48 bits of the identifier are set to the unique MAC address allocated to the switch by its manufacturer. The high order 16 bits of the switch identifier can be configured by the network administrator to influence the topology of the spanning tree. The default value for these high order bits is 32768.
The switches exchange BPDUs to build the spanning tree. Intuitively, the spanning tree is built by first selecting the switch with the smallest identifier as the root of the tree. The branches of the spanning tree are then composed of the shortest paths that allow all of the switches that compose the network to be reached. The BPDUs exchanged by the switches contain the following information :
- the identifier of the root switch (R)
- the cost of the shortest path between the switch that sent the BPDU and the root switch (c)
- the identifier of the switch that sent the BPDU (T)
- the number of the switch port over which the BPDU was sent (p)
We will use the notation <R,c,T,p> to represent a BPDU whose root identifier is R, cost is c and that was sent on the port p of switch T. The construction of the spanning tree depends on an ordering relationship among the BPDUs. This ordering relationship could be implemented by the python function below.
# returns True if bpdu b1 is better than bpdu b2
def better( b1, b2) :
return ( (b1.R < b2.R) or
( (b1.R==b2.R) and (b1.c<b2.c) ) or
( (b1.R==b2.R) and (b1.c==b2.c) and (b1.T<b2.T) ) or
( (b1.R==b2.R) and (b1.c==b2.c) and (b1.T==b2.T) and (b1.p<b2.p) ) )
In addition to the identifier discussed above, the network administrator can also configure a cost to be associated to each switch port. Usually, the cost of a port depends on its bandwidth and the [802.1d] standard recommends the values below. Of course, the network administrator may choose other values. We will use the notation cost[p] to indicate the cost associated to port p in this section.
| Bandwidth | Cost |
|---|---|
| 10 Mbps | 2000000 |
| 100 Mbps | 200000 |
| 1 Gbps | 20000 |
| 10 Gbps | 2000 |
| 100 Gbps | 200 |
The Spanning Tree Protocol uses its own terminology that we illustrate in the figure above. A switch port can be in three different states : Root, Designated and Blocked. All the ports of the root switch are in the Designated state. The state of the ports on the other switches is determined based on the BPDU received on each port.
The Spanning Tree Protocol uses the ordering relationship to build the spanning tree. Each switch listens to BPDUs on its ports. When BPDU=<R,c,T,p> is received on port q, the switch computes the port’s priority vector: V[q]=<R,c+cost[q],T,p,q> , where cost[q] is the cost associated to the port over which the BPDU was received. The switch stores in a table the last priority vector received on each port. The switch then compares its own identifier with the smallest root identifier stored in this table. If its own identifier is smaller, then the switch is the root of the spanning tree and is, by definition, at a distance 0 of the root. The BPDU of the switch is then <R,0,R,p>, where R is the switch identifier and p will be set to the port number over which the BPDU is sent. Otherwise, the switch chooses the best priority vector from its table, bv=<R,c,T,p>. The port over which this best priority vector was learned is the switch port that is closest to the root switch. This port becomes the Root port of the switch. There is only one Root port per switch. The switch can then compute its BPDU as BPDU=<R,c,S,p> , where R is the root identifier, c the cost of the best priority vector, S the identifier of the switch and p will be replaced by the number of the port over which the BPDU will be sent. The switch can then determine the state of all its ports by comparing its own BPDU with the priority vector received on each port. If the switch’s BPDU is better than the priority vector of this port, the port becomes a Designated port. Otherwise, the port becomes a Blocked port.
The state of each port is important when considering the transmission of BPDUs. The root switch regularly sends its own BPDU over all of its (Designated) ports. This BPDU is received on the Root port of all the switches that are directly connected to the root switch. Each of these switches computes its own BPDU and sends this BPDU over all its Designated ports. These BPDUs are then received on the Root port of downstream switches, which then compute their own BPDU, etc. When the network topology is stable, switches send their own BPDU on all their Designated ports, once they receive a BPDU on their Root port. No BPDU is sent on a Blocked port. Switches listen for BPDUs on their Blocked and Designated ports, but no BPDU should be received over these ports when the topology is stable. The utilisation of the ports for both BPDUs and data frames is summarised in the table below.
| Port state | Receives BPDUs | Sends BPDU | Handles data frames |
|---|---|---|---|
| Blocked | yes | no | no |
| Root | yes | no | yes |
| Designated | yes | yes | yes |
To illustrate the operation of the Spanning Tree Protocol, let us consider the simple network topology in the figure below.
A simple Spanning tree computed in a switched Ethernet network
Assume that Switch4 is the first to boot. It sends its own BPDU=<4,0,4,?> on its two ports. When Switch1 boots, it sends BPDU=<1,0,1,1>. This BPDU is received by Switch4, which updates its table and computes a new BPDU=<1,3,4,?>. Port 1 of Switch4 becomes the Root port while its second port is still in the Designated state.
Assume now that Switch9 boots and immediately receives Switch1 ‘s BPDU on port 1. Switch9 computes its own BPDU=<1,1,9,?> and port 1 becomes the Root port of this switch. This BPDU is sent on port 2 of Switch9 and reaches Switch4. Switch4 compares the priority vector built from this BPDU (i.e. <1,2,9,2>) and notices that it is better than Switch4 ‘s BPDU=<1,3,4,2>. Thus, port 2 becomes a Blocked port on Switch4.
During the computation of the spanning tree, switches discard all received data frames, as at that time the network topology is not guaranteed to be loop-free. Once that topology has been stable for some time, the switches again start to use the MAC learning algorithm to forward data frames. Only the Root and Designated ports are used to forward data frames. Switches discard all the data frames received on their Blocked ports and never forward frames on these ports.
Switches, ports and links can fail in a switched Ethernet network. When a failure occurs, the switches must be able to recompute the spanning tree to recover from the failure. The Spanning Tree Protocol relies on regular transmissions of the BPDUs to detect these failures. A BPDU contains two additional fields : the Age of the BPDU and the Maximum Age. The Age contains the amount of time that has passed since the root switch initially originated the BPDU. The root switch sends its BPDU with an Age of zero and each switch that computes its own BPDU increments its Age by one. The Age of the BPDUs stored on a switch’s table is also incremented every second. A BPDU expires when its Age reaches the Maximum Age. When the network is stable, this does not happen as BPDU s are regularly sent by the root switch and downstream switches. However, if the root fails or the network becomes partitioned, BPDU will expire and switches will recompute their own BPDU and restart the Spanning Tree Protocol. Once a topology change has been detected, the forwarding of the data frames stops as the topology is not guaranteed to be loop-free. Additional details about the reaction to failures may be found in [802.1d]
Virtual LANs¶
Another important advantage of Ethernet switches is the ability to create Virtual Local Area Networks (VLANs). A virtual LAN can be defined as a set of ports attached to one or more Ethernet switches. A switch can support several VLANs and it runs one MAC learning algorithm for each Virtual LAN. When a switch receives a frame with an unknown or a multicast destination, it forwards it over all the ports that belong to the same Virtual LAN but not over the ports that belong to other Virtual LANs. Similarly, when a switch learns a source address on a port, it associates it to the Virtual LAN of this port and uses this information only when forwarding frames on this Virtual LAN.
The figure below illustrates a switched Ethernet network with three Virtual LANs. VLAN2 and VLAN3 only require a local configuration of switch S1. Host C can exchange frames with host D, but not with hosts that are outside of its VLAN. VLAN1 is more complex as there are ports of this VLAN on several switches. To support such VLANs, local configuration is not sufficient anymore. When a switch receives a frame from another switch, it must be able to determine the VLAN in which the frame originated to use the correct MAC table to forward the frame. This is done by assigning an identifier to each Virtual LAN and placing this identifier inside the headers of the frames that are exchanged between switches.
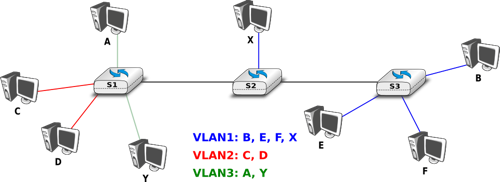
Virtual Local Area Networks in a switched Ethernet network
IEEE defined in the [802.1q] standard a special header to encode the VLAN identifiers. This 32 bit header includes a 20 bit VLAN field that contains the VLAN identifier of each frame. The format of the [802.1q] header is described below.

Format of the 802.1q header
The [802.1q] header is inserted immediately after the source MAC address in the Ethernet frame (i.e. before the EtherType field). The maximum frame size is increased by 4 bytes. It is encoded in 32 bits and contains four fields. The Tag Protocol Identifier is set to 0x8100 to allow the receiver to detect the presence of this additional header. The Priority Code Point (PCP) is a three bit field that is used to support different transmission priorities for the frame. Value 0 is the lowest priority and value 7 the highest. Frames with a higher priority can expect to be forwarded earlier than frames having a lower priority. The C bit is used for compatibility between Ethernet and Token Ring networks. The last 12 bits of the 802.1q header contain the VLAN identifier. Value 0 indicates that the frame does not belong to any VLAN while value 0xFFF is reserved. This implies that 4094 different VLAN identifiers can be used in an Ethernet network.
802.11 wireless networks¶
The radio spectrum is a limited resource that must be shared by everyone. During most of the twentieth century, governments and international organisations have regulated most of the radio spectrum. This regulation controls the utilisation of the radio spectrum, in order to ensure that there are no interferences between different users. A company that wants to use a frequency range in a given region must apply for a license from the regulator. Most regulators charge a fee for the utilisation of the radio spectrum and some governments have encouraged competition among companies bidding for the same frequency to increase the license fees.
In the 1970s, after the first experiments with ALOHANet, interest in wireless networks grew. Many experiments were done on and outside the ARPANet. One of these experiments was the first mobile phone , which was developed and tested in 1973. This experimental mobile phone was the starting point for the first generation analog mobile phones. Given the growing demand for mobile phones, it was clear that the analog mobile phone technology was not sufficient to support a large number of users. To support more users and new services, researchers in several countries worked on the development of digital mobile telephones. In 1987, several European countries decided to develop the standards for a common cellular telephone system across Europe : the Global System for Mobile Communications (GSM). Since then, the standards have evolved and more than three billion users are connected to GSM networks today.
While most of the frequency ranges of the radio spectrum are reserved for specific applications and require a special licence, there are a few exceptions. These exceptions are known as the Industrial, Scientific and Medical (ISM) radio bands. These bands can be used for industrial, scientific and medical applications without requiring a licence from the regulator. For example, some radio-controlled models use the 27 MHz ISM band and some cordless telephones operate in the 915 MHz ISM. In 1985, the 2.400-2.500 GHz band was added to the list of ISM bands. This frequency range corresponds to the frequencies that are emitted by microwave ovens. Sharing this band with licensed applications would have likely caused interferences, given the large number of microwave ovens that are used. Despite the risk of interferences with microwave ovens, the opening of the 2.400-2.500 GHz allowed the networking industry to develop several wireless network techniques to allow computers to exchange data without using cables. In this section, we discuss in more detail the most popular one, i.e. the WiFi [802.11] family of wireless networks. Other wireless networking techniques such as BlueTooth or HiperLAN use the same frequency range.
Today, WiFi is a very popular wireless networking technology. There are more than several hundreds of millions of WiFi devices. The development of this technology started in the late 1980s with the WaveLAN proprietary wireless network. WaveLAN operated at 2 Mbps and used different frequency bands in different regions of the world. In the early 1990s, the IEEE created the 802.11 working group to standardise a family of wireless network technologies. This working group was very prolific and produced several wireless networking standards that use different frequency ranges and different physical layers. The table below provides a summary of the main 802.11 standards.
| Standard | Frequency | Typical throughput | Max bandwidth | Range (m) indoor/outdoor |
|---|---|---|---|---|
| 802.11 | 2.4 GHz | 0.9 Mbps | 2 Mbps | 20/100 |
| 802.11a | 5 GHz | 23 Mbps | 54 Mbps | 35/120 |
| 802.11b | 2.4 GHz | 4.3 Mbps | 11 Mbps | 38/140 |
| 802.11g | 2.4 GHz | 19 Mbps | 54 Mbps | 38/140 |
| 802.11n | 2.4/5 GHz | 74 Mbps | 150 Mbps | 70/250 |
When developing its family of standards, the IEEE 802.11 working group took a similar approach as the IEEE 802.3 working group that developed various types of physical layers for Ethernet networks. 802.11 networks use the CSMA/CA Medium Access Control technique described earlier and they all assume the same architecture and use the same frame format.
The architecture of WiFi networks is slightly different from the Local Area Networks that we have discussed until now. There are, in practice, two main types of WiFi networks : independent or adhoc networks and infrastructure networks [11]. An independent or adhoc network is composed of a set of devices that communicate with each other. These devices play the same role and the adhoc network is usually not connected to the global Internet. Adhoc networks are used when for example a few laptops need to exchange information or to connect a computer with a WiFi printer.

An 802.11 independent or adhoc network
Most WiFi networks are infrastructure networks. An infrastructure network contains one or more access points that are attached to a fixed Local Area Network (usually an Ethernet network) that is connected to other networks such as the Internet. The figure below shows such a network with two access points and four WiFi devices. Each WiFi device is associated to one access point and uses this access point as a relay to exchange frames with the devices that are associated to another access point or reachable through the LAN.

An 802.11 infrastructure network
An 802.11 access point is a relay that operates in the datalink layer like switches. The figure below represents the layers of the reference model that are involved when a WiFi host communicates with a host attached to an Ethernet network through an access point.

An 802.11 access point
802.11 devices exchange variable length frames, which have a slightly different structure than the simple frame format used in Ethernet LANs. We review the key parts of the 802.11 frames. Additional details may be found in [802.11] and [Gast2002] . An 802.11 frame contains a fixed length header, a variable length payload that may contain up 2324 bytes of user data and a 32 bits CRC. Although the payload can contain up to 2324 bytes, most 802.11 deployments use a maximum payload size of 1500 bytes as they are used in infrastructure networks attached to Ethernet LANs. An 802.11 data frame is shown below.

802.11 data frame format
The first part of the 802.11 header is the 16 bit Frame Control field. This field contains flags that indicate the type of frame (data frame, RTS/CTS, acknowledgement, management frames, etc), whether the frame is sent to or from a fixed LAN, etc [802.11]. The Duration is a 16 bit field that is used to reserve the transmission channel. In data frames, the Duration field is usually set to the time required to transmit one acknowledgement frame after a SIFS delay. Note that the Duration field must be set to zero in multicast and broadcast frames. As these frames are not acknowledged, there is no need to reserve the transmission channel after their transmission. The Sequence control field contains a 12 bits sequence number that is incremented for each data frame.
The astute reader may have noticed that the 802.11 data frames contain three 48-bits address fields [12] . This is surprising compared to other protocols in the network and datalink layers whose headers only contain a source and a destination address. The need for a third address in the 802.11 header comes from the infrastructure networks. In such a network, frames are usually exchanged between routers and servers attached to the LAN and WiFi devices attached to one of the access points. The role of the three address fields is specified by bit flags in the Frame Control field.
When a frame is sent from a WiFi device to a server attached to the same LAN as the access point, the first address of the frame is set to the MAC address of the access point, the second address is set to the MAC address of the source WiFi device and the third address is the address of the final destination on the LAN. When the server replies, it sends an Ethernet frame whose source address is its MAC address and the destination address is the MAC address of the WiFi device. This frame is captured by the access point that converts the Ethernet header into an 802.11 frame header. The 802.11 frame sent by the access point contains three addresses : the first address is the MAC address of the destination WiFi device, the second address is the MAC address of the access point and the third address the MAC address of the server that sent the frame.
802.11 control frames are simpler than data frames. They contain a Frame Control, a Duration field and one or two addresses. The acknowledgement frames are very small. They only contain the address of the destination of the acknowledgement. There is no source address and no Sequence Control field in the acknowledgement frames. This is because the acknowledgement frame can easily be associated to the previous frame that it acknowledges. Indeed, each unicast data frame contains a Duration field that is used to reserve the transmission channel to ensure that no collision will affect the acknowledgement frame. The Sequence Control field is mainly used by the receiver to remove duplicate frames. Duplicate frames are detected as follows. Each data frame contains a 12 bits Sequence Control field and the Frame Control field contains the Retry bit flag that is set when a frame is transmitted. Each 802.11 receiver stores the most recent sequence number received from each source address in frames whose Retry bit is reset. Upon reception of a frame with the Retry bit set, the receiver verifies its sequence number to determine whether it is a duplicated frame or not.

IEEE 802.11 ACK and CTS frames
802.11 RTS/CTS frames are used to reserve the transmission channel, in order to transmit one data frame and its acknowledgement. The RTS frames contain a Duration and the transmitter and receiver addresses. The Duration field of the RTS frame indicates the duration of the entire reservation (i.e. the time required to transmit the CTS, the data frame, the acknowledgements and the required SIFS delays). The CTS frame has the same format as the acknowledgement frame.

IEEE 802.11 RTS frame format
Note
The 802.11 service
Despite the utilization of acknowledgements, the 802.11 layer only provides an unreliable connectionless service like Ethernet networks that do not use acknowledgements. The 802.11 acknowledgements are used to minimize the probability of frame duplication. They do not guarantee that all frames will be correctly received by their recipients. Like Ethernet, 802.11 networks provide a high probability of successful delivery of the frames, not a guarantee. Furthermore, it should be noted that 802.11 networks do not use acknowledgements for multicast and broadcast frames. This implies that in practice such frames are more likely to suffer from transmission errors than unicast frames.
In addition to the data and control frames that we have briefly described above, 802.11 networks use several types of management frames. These management frames are used for various purposes. We briefly describe some of these frames below. A detailed discussion may be found in [802.11] and [Gast2002].
A first type of management frames are the beacon frames. These frames are broadcasted regularly by access points. Each beacon frame contains information about the capabilities of the access point (e.g. the supported 802.11 transmission rates) and a Service Set Identity (SSID). The SSID is a null-terminated ASCII string that can contain up to 32 characters. An access point may support several SSIDs and announce them in beacon frames. An access point may also choose to remain silent and not advertise beacon frames. In this case, WiFi stations may send Probe request frames to force the available access points to return a Probe response frame.
Note
IP over 802.11
Two types of encapsulation schemes were defined to support IP in Ethernet networks : the original encapsulation scheme, built above the Ethernet DIX format is defined in RFC 894 and a second encapsulation RFC 1042 scheme, built above the LLC/SNAP protocol [802.2]. In 802.11 networks, the situation is simpler and only the RFC 1042 encapsulation is used. In practice, this encapsulation adds 6 bytes to the 802.11 header. The first four bytes correspond to the LLC/SNAP header. They are followed by the two bytes Ethernet Type field (0x800 for IP and 0x806 for ARP). The figure below shows an IP packet encapsulated in an 802.11 frame.
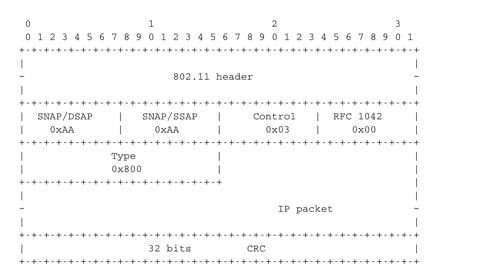
IP over IEEE 802.11
The second important utilisation of the management frames is to allow a WiFi station to be associated with an access point. When a WiFi station starts, it listens to beacon frames to find the available SSIDs. To be allowed to send and receive frames via an access point, a WiFi station must be associated to this access point. If the access point does not use any security mechanism to secure the wireless transmission, the WiFi station simply sends an Association request frame to its preferred access point (usually the access point that it receives with the strongest radio signal). This frame contains some parameters chosen by the WiFi station and the SSID that it requests to join. The access point replies with an Association response frame if it accepts the WiFI station.
Footnotes
| [11] | The 802.11 working group defined the basic service set (BSS) as a group of devices that communicate with each other. We continue to use network when referring to a set of devices that communicate. |
| [12] | In fact, the [802.11] frame format contains a fourth optional address field. This fourth address is only used when an 802.11 wireless network is used to interconnect bridges attached to two classical LAN networks. |
Summary¶
In this chapter, we first explained the principles of the datalink layer. There are two types of datalink layers : those used over point-to-point links and those used over Local Area Networks. On point-to-point links, the datalink layer must at least provide a framing technique, but some datalink layer protocols also include reliability mechanisms such as those used in the transport layer. We have described the Point-to-Point Protocol that is often used over point-to-point links in the Internet.
Local Area Networks pose a different problem since several devices share the same transmission channel. In this case, a Medium Access Control algorithm is necessary to regulate the access to the transmission channel because whenever two devices transmit at the same time a collision occurs and none of these frames can be decoded by their recipients. There are two families of MAC algorithms. The statistical or optimistic MAC algorithms reduce the probability of collisions but do not completely prevent them. With such algorithms, when a collision occurs, the collided frames must be retransmitted. We have described the operation of the ALOHA, CSMA, CSMA/CD and CSMA/CA MAC algorithms. Deterministic or pessimistic MAC algorithms avoid all collisions. We have described the Token Ring MAC where stations exchange a token to regulate the access to the transmission channel.
Finally, we have described in more detail two successful Local Area Network technologies : Ethernet and WiFi. Ethernet is now the de facto LAN technology. We have analysed the evolution of Ethernet including the operation of hubs and switches. We have also described the Spanning Tree Protocol that must be used when switches are interconnected. For the last few years, WiFi became the de facto wireless technology at home and inside enterprises. We have explained the operation of WiFi networks and described the main 802.11 frames.
Exercises¶
- The host H0 pings its peer H1 in the network depicted in the figure below. Explain precisely what happened in the network since it has started.

- Consider the switched network shown in the figure below. What is the spanning tree that will be computed by 802.1d in this network assuming that all links have a unit cost ? Indicate the state of each port.

A small network composed of Ethernet switches
- Consider the switched network shown in the figure above. In this network, assume that the LAN between switches 3 and 12 fails. How should the switches update their port/address tables after the link failure ?
- In the network depicted in the figure below, the host H0 performs a traceroute toward its peer H1 (designated by its name) through a network composed of switches and routers. Explain precisely the frames, packets, and segments exchanged since the network was turned on. You may assign addesses if you need to.

The host H0 performs a traceroute toward its peer H1 through a network composed of switches and routers.
- Many enterprise networks are organized with a set of backbone devices interconnected by using a full mesh of links as shown in the figure below. In this network, what are the benefits and drawbacks of using Ethernet switches and IP routers running OSPF ?

A typical enterprise backbone network
- In the network represented on the figure below, can the host H0 communicate with H1 and vice-versa? Explain. Add whatever you need in the network to allow them to communicate.
Can H0 and H1 communicate?
- Consider the network depicted in the figure below. Both of the hosts H0 and H1 have two interfaces: one connected to the switch S0 and the other one to the switch S1. Will the link between S0 and S1 ever be used? If so, under which assumptions? Provide a comprehensive answer.

Will the link between the switches S0 and S1 ever be used?
- Most commercial Ethernet switches are able to run the Spanning tree protocol independently on each VLAN. What are the benefits of using per-VLAN spanning trees ?